
PyTorch与向量化计算
向量化计算是一种特殊的并行计算方式。一般来说,程序在同一时间内只执行一个操作,而并行计算可以在同一时间内执行多个操作。向量化计算是指对不同的数据执行同样的一个或一批指令,或者把指令应用到一个数组或向量上,从而将多次循环操作变成一次计算。
向量化操作可以极大地提高科学运算的效率。尽管Python本身是一门高级语言,使用简便,但是其中存在着许多低效的操作,例如for循环等。因此,在科学计算中应当极力避免使用Python原生的for循环,尽量使用向量化数值运算,下面举例说明:
In: import torch as t# 定义for循环完成加法操作def for_loop_add(x, y):result = []for i, j in zip(x, y):result.append(i + j)return t.tensor(result)x = t.zeros(100)y = t.ones(100)%timeit -n 100 for_loop_add(x, y)%timeit -n 100 (x + y) # +是向量化计算Out:100 loops, best of 3: 786 µs per loop100 loops, best of 3: 2.57 µs per loop
从上面的例子中可以看出,for循环和向量化计算之间存在数百倍的速度差距,在实际使用中应该尽量调用内建函数(buildin-function)。这些函数底层由C/C++实现,在实现中使用了向量化计算的思想,通过底层优化实现了高效计算。在日常编程中应该养成向量化的编程习惯,避免对较大的Tensor进行逐元素的遍历操作,从而提高程序的运行效率。
本文将主要从广播法则、高级索引两个方面介绍PyTorch中的向量化计算。
01
广播法则(broadcast)是科学计算中经常使用的一个技巧,它在快速执行向量化计算的同时不会占用额外的内存/显存。NumPy中的广播法则定义如下。
所有输入数组都与形状(shape)最大的数组看齐,形状不足的部分在前面加1补齐。
两个数组要么在某一个维度的尺寸一致,要么其中一个数组在该维度的尺寸为1,否则不符合广播法则的要求。
如果输入数组的某个维度的尺寸为1,那么计算时沿此维度复制扩充成目标的形状大小。
虽然PyTorch已经支持了自动广播法则,但是建议通过以下两种方式的组合手动实现广播法则,这样更加直观,也更不容易出错。
unsqueeze、view或者tensor[None] :为数据某一维度补1,实现第一个广播法则。
expand或者expand_as,重复数组,实现第三个广播法则;该操作不会复制整个数组,因此不会占用额外的空间。
注意:repeat可以实现与expand类似的功能,expand是在已经存在的Tensor上创建一个新的视图(view),repeat会将相同的数据复制多份,因此会占用额外的空间。
首先来看自动广播法则:
In: # 自动广播法则# 第一步:a是2维的,b是3维的,所以先在较小的a前面补1个维度,# 即:a.unsqueeze(0),a的形状变成(1,3,2),b的形状是(2,3,1),# 第二步:a和b在第一和第三个维度的形状不一样,同时其中一个为1,# 利用广播法则扩展,两个形状都变成了(2,3,2)a = t.ones(3, 2)b = t.zeros(2, 3, 1)(a + b).shapeOut:torch.Size([2, 3, 2])
再来看如何手动实现以上广播过程:
In: # 手动广播法则,下面两行操作是等效的,推荐使用None的方法# a.view(1, 3, 2).expand(2, 3, 2) + b.expand(2, 3, 2)a[None,:,:].expand(2, 3, 2) + b.expand(2, 3, 2)Out:tensor([[[1., 1.],[1., 1.],[1., 1.]],[[1., 1.],[1., 1.],[1., 1.]]])
02
2.1 基本索引
元组序列:在索引中直接使用一个元组序列对Tensor中数据的具体位置进行定位,也可以直接使用多个整数(等价于元组序列省略括号的形式)代替。 切片对象(Slice Object):在索引中常见的切片对象形如start:stop:step,对一个维度进行全选时可以直接使用:。 省略号(...):在索引中常用省略号来代表一个或多个维度的切片。 None:与NumPy中的newaxis相同,None在PyTorch索引中起到增加一个维度的作用。
2.1.1 元组序列
In: a = t.arange(1, 25).view(2, 3, 4)aOut:tensor([[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])In: # 提取位置[0, 1, 2]的元素# 等价于a[(0, 1, 2)](保留括号的元组形式)a[0, 1, 2]Out:tensor(7)
注意:a[0, 1, 2]与a[[0, 1, 2]]、a[(0, 1, 2),]并不等价,后面两个不满足基本索引的条件,既不是一个元组序列又不是一个切片对象,它们属于高级索引的范畴,这部分内容将在后文进行讲解。
2.1.2 : 和 ...
在实际编程中,经常会在Tensor的任意维度上进行切片操作,PyTorch已经封装好了两个运算符:和...,它们的用法如下。
:常用于对一个维度进行操作,基本的语法形式是:start:end:step。单独使用:代表全选这个维度,start和end为空分别表示从头开始和一直到结束,step的默认值是1。
...用于省略任意多个维度,可以用在切片的中间,也可以用在首尾。
下面举例说明这两个运算符的使用方法:
In: a = t.rand(64, 3, 224, 224)print(a[:,:,0:224:4,:].shape) # 第三个维度间隔切片# 省略start和end代表整个维度print(a[:,:,::4,:].shape)Out:torch.Size([64, 3, 56, 224])torch.Size([64, 3, 56, 224])In: # 使用...代替一个或多个维度,建议一个索引中只使用一次a[...,::4,:].shape# a[...,::4,...].shape # 如果将最后一个维度也改为...,那么在匹配维度时将混乱出错Out:torch.Size([64, 3, 56, 224])
2.1.3 None索引
在PyTorch的源码中,None索引经常被使用。None索引可以直观地表示维度的扩展,在广播法则中充当1的作用。使用None索引,本质上与使用unsqueeze函数是等价的,都能起到扩展维度的作用。在维度较多的情况下,或者需要对多个维度先进行扩展再进行矩阵计算时,使用None索引会更加清晰直观。因此,推荐使用None索引进行维度的扩展,下面举例说明:
In: a = t.rand(2, 3, 4, 5)# 在最前面加一个维度,下面两种写法等价print(a.unsqueeze(0).shape)print(a[None, ...].shape)Out:torch.Size([1, 2, 3, 4, 5])torch.Size([1, 2, 3, 4, 5])In: # 在原有的四个维度中均插入一个维度,成为(2,1,3,1,4,1,5)# unsqueeze方法,每成功增加一个维度,都需要重新计算下一个需要增加的维度位置b = a.unsqueeze(1)b = b.unsqueeze(3)b = b.unsqueeze(5)b.shapeOut:torch.Size([2, 1, 3, 1, 4, 1, 5])In: # None索引方法,直接在需要增加的维度上填写None即可a[:,None,:,None,:,None,:].shapeOut:torch.Size([2, 1, 3, 1, 4, 1, 5])
2.2 高级索引
与基本索引相比,高级索引的触发条件有所不同,常见的高级索引遵循以下三个规律。
索引是一个非元组序列:例如tensor[(0, 1, 2),]。
索引是一个整数类型或者布尔类型的Tensor。
索引是元组序列,但是里面至少包含一个整数类型或者布尔类型的Tensor。
2.2.1 整数数组索引
对于整数数组索引(Integer Array Indexing),一般情况下需要先确定输入输出Tensor的形状,这是因为所有的整数索引都有一个相对固定的模式:
其中
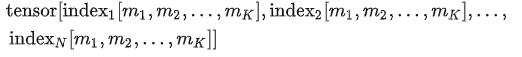
如果index的形状不完全相同,但是满足广播法则,那么它们将自动对齐成一样的形状,从而完成整数数组索引操作。对于不能够广播或者不能够得到相同形状的索引,无法进行整数数组索引操作。下面举例说明:
In: a = t.arange(12).view(3, 4)# 相同形状的index索引# 获取索引为[1,0]、[2,2]的元素a[t.tensor([1, 2]), t.tensor([0, 2])]Out:tensor([ 4, 10])In: # 不相同形状的index索引,满足广播法则# 获取索引为[1,0]、[2,0]、[1,2]、[2,2]的元素a[t.tensor([1,2])[None,:], t.tensor([0, 2])[:,None]]Out:tensor([[ 4, 8],[ 6, 10]])
有时高级索引与基本索引需要混合使用,这时候基本索引(如切片对象、省略号、None等)会将高级索引切分成多个区域。假设高级索引idx1,idx2,idx3的形状都是
所有的高级索引都处于相邻的维度:例如tensor[idx1, :, :]或者tensor[:, idx2, idx3],那么直接将所有高级索引所在区域的维度转换成高级索引的维度,Tensor的其他维度按照基本索引正常计算。
基本索引将多个高级索引划分到不同区域:例如tensor[idx1, :, idx3],那么统一将高级索引的维度放在输出Tensor维度的开头,剩下部分补齐基本索引的维度。这时所有的高级索引并不相邻,无法确定高级索引的维度应该替换Tensor的哪些维度,因此统一放到开头位置。
下面举例说明:
In: a = t.arange(24).view(2, 3, 4)idx1 = t.tensor([[1, 0]]) # shape 1×2idx2 = t.tensor([[0, 2]]) # shape 1×2# 所有的高级索引相邻a[:, idx1, idx2].shapeOut:torch.Size([2, 1, 2])In: # 手动计算输出形状# a的第一个维度保留,后两个维度是索引维度a.shape[0], idx1.shapeOut:(2, torch.Size([1, 2]))In: a = t.arange(120).reshape(2, 3, 4, 5)# 中间两个维度替换成高级索引的维度a[:, idx1, idx2, :].shapeOut:torch.Size([2, 1, 2, 5])In: # 高级索引被划分到不同区域# 高级索引的维度放在输出维度的最前面,剩下的维度依次补齐a[idx1, :, idx2].shapeOut:torch.Size([1, 2, 3, 5])In: a[:,idx1,:,idx2].shapeOut:torch.Size([1, 2, 2, 4])
整数数组索引是根据索引数组(
当索引数组的个数等于Tensor的维度数时,索引输出的形状等价于
的形状,输出的每一个元素等价于 。 当索引数组的个数小于Tensor的维度数时,类似于切片操作,将这个切片当做索引操作的结果。
下面来看几个示例:
In: a = t.arange(12).view(3, 4)print(a)print(a[[2,0]]) # 索引数组个数小于a的维度数# 索引数组个数等于a的维度数# 获取索引为[1,3]、[2,2]、[0,1]的元素print(a[[1, 2, 0], [3, 2, 1]]) Out:tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])tensor([[ 8, 9, 10, 11],[ 0, 1, 2, 3]])tensor([ 7, 10, 1])In: # 输出形状取决于索引数组的形状# 获取索引为[0,1]、[2,3]、[1,3]、[0,1]的元素idx1 = t.tensor([[0, 2], [1, 0]])idx2 = t.tensor([[1, 3], [3, 1]])a[idx1, idx2]Out:tensor([[ 1, 11],[ 7, 1]])
In: # 错误示范idx1 = [[0, 2], [1, 0]]idx2 = [[1, 3], [3, 1]]idx = t.tensor([idx1, idx2]) # 提前将索引数组进行组合# a[idx]# 如果报错,表示超出了索引范围# 没报错,但是结果不是想要的结果。这是因为只索引了第一个维度,后面的维度直接进行切片
2.2.2 布尔数组索引
在高级索引中,如果索引数组的类型是布尔型,那么就会使用布尔数组索引(Boolean Array Indexing)。布尔类型的数组对象可以通过比较运算符产生,下面举例说明:
In: a = t.arange(12).view(3, 4)idx_bool = t.rand(3, 4) > 0.5idx_boolOut:tensor([[ True, True, True, True],[False, False, False, False],[False, False, False, False]])In: a[idx_bool] # 返回idx_bool中为True的部分Out:tensor([0, 1, 2, 3])
布尔数组索引常用于对特定条件下的数值进行修改。例如,对一个Tensor中的所有正数进行乘2操作,最直观的方法是写一个for循环,遍历整个Tensor,对满足条件的数进行计算。
In: # 利用for循环a = t.tensor([[1, -3, 2], [2, 9, -1], [-8, 4, 1]])for i in range(a.shape[0]):for j in range(a.shape[1]):if a[i, j] > 0:a[i, j] *= 2aOut:tensor([[ 2, -3, 4],[ 4, 18, -1],[-8, 8, 2]])
此时,可以使用布尔数组索引来简化运算:
In: # 利用布尔数组索引a = t.tensor([[1, -3, 2], [2, 9, -1], [-8, 4, 1]])a[a > 0] *= 2aOut:tensor([[ 2, -3, 4],[ 4, 18, -1],[-8, 8, 2]])
2.3 einsum / einops
在高级索引中还有一类特殊方法:爱因斯坦操作。下面介绍两种常用的爱因斯坦操作:einsum和einops,它们被广泛地用于向量、矩阵和张量的运算。灵活运用爱因斯坦操作可以用非常简单的方式表示较为复杂的多维Tensor之间的运算。
2.3.1 einsum
In: # 转置操作import torch as ta = t.arange(9).view(3, 3)b = t.einsum('ij->ji', a) # 直接交换两个维度print(a)print(b)Out:tensor([[0, 1, 2],[3, 4, 5],[6, 7, 8]])tensor([[0, 3, 6],[1, 4, 7],[2, 5, 8]])In: # 求和操作a = t.arange(36).view(3, 4, 3)b = t.einsum('ijk->', a) # 所有元素求和bOut:tensor(630)In: # 多个张量之间的混合运算a = t.arange(6).view(2, 3)b = t.arange(3)# 矩阵对应维度相乘,b进行了广播t.einsum('ij,j->ij', a, b)Out:tensor([[ 0, 1, 4],[ 0, 4, 10]])In: # 直观表达矩阵的内积和外积a = t.arange(6).view(2, 3)b = t.arange(6).view(3, 2)c_in = t.einsum('ij,ij->', a, a) # 内积,结果是一个数c_out = t.einsum('ik,kj->ij', a, b) # 外积,矩阵乘法的结果print(c_in)print(c_out)Out:tensor(55)tensor([[10, 13],[28, 40]])
2.3.2 einops
除了上面介绍的爱因斯坦求和,其他的爱因斯坦操作都封装在einops中,它支持NumPy、PyTorch、Chainer、TensorFlow等多种框架的数据格式。在爱因斯坦操作中,多次转置操作不再使用tensor_x.transpose(1, 2).transpose(2, 3),而是用更直观的方式:rearrange(tensor_x, 'b c h w -> b h w c')代替。
einops有很多复杂的操作,这里仅讲解最常见、最直观的用法,并分析如何在深度学习框架中高效使用einops操作。有关einops更详细的内容示例和底层实现可以参考einops的说明文档。
In: from einops import rearrange, reducea = t.rand(16, 3, 64, 64) # batch × channel × height × weight# 转置操作rearrange(a, 'b c h w -> b h w c').shapeOut:torch.Size([16, 64, 64, 3])In: # 融合部分维度y = rearrange(a, 'b c h w -> b (h w c)') # flatteny.shapeOut:torch.Size([16, 12288])
爱因斯坦操作凭借其便捷、直观的特点,在视觉Transformer中得到了广泛的应用。假设输入是256×256×3的彩色图像,根据Transformer的要求,现在需要将其划分成8×8=64个块,每个块有32×32×3=3072个像素,使用爱因斯坦操作实现如下:
In: img = t.randn(1, 3, 256, 256)x = rearrange(img, 'b c (h p1) (w p2) -> b (p1 p2) (h w c)', p1=8, p2=8)x.shapeOut:torch.Size([1, 64, 3072])
在很多网络结构中,需要提取通道间或者空间像素之间的信息,从而完成通道的部分维度和空间的部分维度之间的转化。直接使用索引等操作会比较烦琐,einops操作可以直观地完成这个过程:
In: # Space to Depthb = t.rand(16, 32, 64, 64)s2d = rearrange(b, 'b c (h h0) (w w0) -> b (h0 w0 c) h w', h0=2, w0=2)# Depth to Spaced2s = rearrange(b, 'b (c h0 w0) h w -> b c (h h0) (w w0)', h0=2, w0=2)print("Space to Depth: ", s2d.shape)print("Depth to Space: ", d2s.shape)Out:Space to Depth: torch.Size([16, 128, 32, 32])Depth to Space: torch.Size([16, 8, 128, 128])
除了rearrange,常见的einops操作还有reduce,它常用于求和、求均值等操作,同时也用于搭建卷积神经网络中的池化层,下面举例说明:
In: # 对空间像素求和y = reduce(a, 'b c h w -> b c', reduction='sum')y.shape # 对h和w维度求和Out:torch.Size([16, 3])In: # 全局平局池化global_avg_pooling = reduce(a, 'b c h w -> b c', reduction='mean')global_avg_pooling.shape Out:torch.Size([16, 3])
einops的所有操作都支持反向传播,可以有效地嵌入到深度学习模型框架中,示例如下:
In: x0 = t.rand(16, 3, 64, 64)x0.requires_grad = Truex1 = reduce(x0, 'b c h w -> b c', reduction='max')x2 = rearrange(x1, 'b c -> c b')x3 = reduce(x2, 'c b -> ', reduction='sum')x3.backward()x0.grad.shapeOut:torch.Size([16, 3, 64, 64])
03
向量化思想可以解决深度学习中的很多经典问题,例如实现img2col快速卷积算法、在目标检测中计算检测结果框与ground truth的交并比(IoU)以及实现RCNN网络中的RoI Align算法等。这里我们以反向Unique函数为例进行说明。
在PyTorch中有一个unique函数,它的功能是返回输入Tensor中不同的元素组成的unique list,同时返回输入Tensor对应于这个unique list的索引。当拿到了这个unique list和对应的索引,能否还原出输入的Tensor呢?
答案是肯定的。最简单的思路是遍历这个索引,逐个生成输入Tensor对应位置的元素,最后进行组合即可。这个过程比较繁琐,可以考虑使用高级索引解决这个问题。根据上文中整数数组索引的思路,这个索引的size和目标Tensor的size是一致的,因此可以直接使用整数数组索引对原始Tensor进行构建,具体实现如下:
In: # 随机生成一组形状为(10, 15, 10, 5)、0~9数字组成的张量a = t.randint(1, 10, (10, 15, 10, 5))# 获取输出的unique list和索引output, inverse_indices = t.unique(a, return_inverse=True)# 通过整数数组索引 还原原始tensora_generate = output[inverse_indices]a_generate.equal(a)Out:True
上述结果可以看出,还原的Tensor值与原始值一致,这意味着使用高级索引方法可以便捷地完成反向unique操作,从而避免了耗时较长的循环遍历操作。
04
本文对PyTorch中的向量化计算与高级索引进行了详细介绍。向量化思想在高维数据处理时能够有效提升计算效率,高级索引操作可以帮助用户灵活地对Tensor进行取值、切片等操作,以便进行更加复杂的计算。读者可以仔细体会其中的向量化思想,并在解决实际问题时尝试使用向量化思想进行编程,从而提高程序的运行效率。
本文内容节选自 @KEDE @陈云 的书籍《深度学习框架PyTorch入门与实践(第2版)》
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》