
PyTorch模型量化工具学习

极市导读
通过减少原始模型参数的数量或比特数,模型量化技术能降低深度学习对内存和计算的需求。本文主要介绍了这种量化技术的方法、流程和工具,并预测了数个有潜力的研究方向。
应用范围
weight的8 bit量化 :data_type = qint8,数据范围为[-128, 127] activation的8 bit量化:data_type = quint8,数据范围为[0, 255]
具有 AVX2 支持或更高版本的 x86 CPU:fbgemm ARM CPU:qnnpack
q_backend = "qnnpack" # qnnpack or fbgemmtorch.backends.quantized.engine = q_backendqconfig = torch.quantization.get_default_qconfig(q_backend)
QConfig(activation=functools.partial(, reduce_range=False), weight=functools.partial(, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric))
量化方法
量化流程
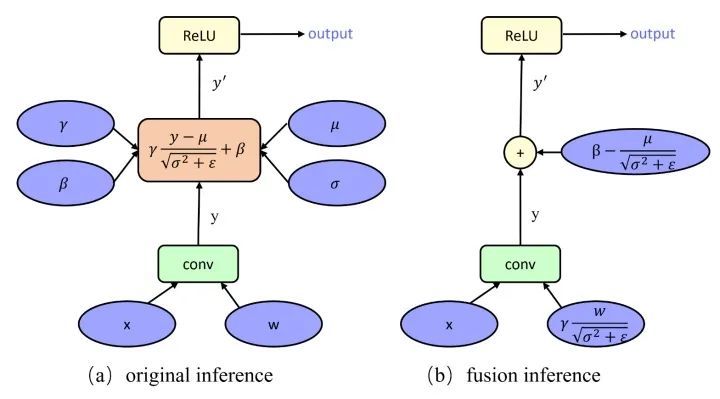
量化工具
Quantization-Aware Training相关模块
总结
推荐阅读

评论