
Pytorch量化感知训练详解
前言
量化感知训练(Quantization Aware Training )是在模型中插入伪量化模块(fake_quant module)模拟量化模型在推理过程中进行的舍入(rounding)和钳位(clamping)操作,从而在训练过程中提高模型对量化效应的适应能力,获得更高的量化模型精度 。在这个过程中,所有计算(包括模型正反向传播计算和伪量化节点计算)都是以浮点计算实现的,在训练完成后才量化为真正的int8模型。
Pytorch官方从1.3版本开始提供量化感知训练API,只需修改少量代码即可实现量化感知训练。目前torch.quantization仍处于beta阶段,不保证API前向、后向兼容性。以下介绍基于Pytorch 1.7,其他版本可能会有差异。
Pytorch量化感知训练流程
首先给出提供一个可运行demo,直观了解量化感知训练的6个步骤,再进行详细的介绍
import torch
from torch.quantization import prepare_qat, get_default_qat_qconfig, convert
from torchvision.models import quantization
# Step1:修改模型
# 这里直接使用官方修改好的MobileNet V2,下文会对修改点进行介绍
model = quantization.mobilenet_v2()
print("original model:")
print(model)
# Step2:折叠算子
# fuse_model()在training或evaluate模式下算子折叠结果不同,
# 对于QAT,需确保在training状态下进行算子折叠
assert model.training
model.fuse_model()
print("fused model:")
print(model)
# Step3:指定量化方案
# 通过给模型实例增加一个名为"qconfig"的成员变量实现量化方案的指定
# backend目前支持fbgemm和qnnpack
BACKEND = "fbgemm"
model.qconfig = get_default_qat_qconfig(BACKEND)
# Step4:插入伪量化模块
prepare_qat(model, inplace=True)
print("model with observers:")
print(model)
# 正常的模型训练,无需修改代码
# Step5:实施量化
model.eval()
# 执行convert函数前,需确保模型在evaluate模式
model_int8 = convert(model)
print("quantized model:")
print(model_int8)
# Step6:int8模型推理
# 指定与qconfig相同的backend,在推理时使用正确的算子
torch.backends.quantized.engine = BACKEND
# 目前Pytorch的int8算子只支持CPU推理,需确保输入和模型都在CPU侧
# 输入输出仍为浮点数
fp32_input = torch.randn(1, 3, 224, 224)
y = model_int8(fp32_input)
print("output:")
print(y)
Step1:修改模型
Pytorch下需要适当修改模型才能进行量化感知训练,以下以常用的MobileNetV2为例。官方已修改好的MobileNetV2的代码,详见这里(https://github.com/pytorch/vision/blob/master/torchvision/models/quantization/mobilenet.py)
修改主要包括3点,以下摘取相应的代码进行介绍:
(1)在模型输入前加入QuantStub(),在模型输出后加入DeQuantStub()。目的是将输入从fp32量化为int8,将输出从int8反量化为fp32。模型的__init__()和forward()修改为:
class QuantizableMobileNetV2(MobileNetV2):
def __init__(self, *args, **kwargs):
"""
MobileNet V2 main class
Args:
Inherits args from floating point MobileNetV2
"""
super(QuantizableMobileNetV2, self).__init__(*args, **kwargs)
self.quant = QuantStub()
self.dequant = DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self._forward_impl(x)
x = self.dequant(x)
return x
(2)对加法等操作加入伪量化节点。因为int8数值进行加法运算容易超出数值范围,所以不是直接进行计算,而是进行反量化->计算->量化的操作。以InvertedResidual的修改为例:
class QuantizableInvertedResidual(InvertedResidual):
def __init__(self, *args, **kwargs):
super(QuantizableInvertedResidual, self).__init__(*args, **kwargs)
# 加法的伪量化节点需要记录所经过该节点的数值的范围,因此需要实例化一个对象
self.skip_add = nn.quantized.FloatFunctional()
def forward(self, x):
if self.use_res_connect:
# 普通版本MobileNet V2的加法
# return x + self.conv(x)
# 量化版本MobileNet V2的加法
return self.skip_add.add(x, self.conv(x))
else:
return self.conv(x)
(3)将ReLU6替换为ReLU。MobileNet V2使用ReLU6的原因是对ReLU的输出范围进行截断以缓解量化为fp16模型时的精度下降。因为int8量化本身就能确定截断阈值,所以将ReLU6替换为ReLU以去掉截断阈值固定为6的限制。官方的修改代码在建立网络后通过_replace_relu()将MobileNetV2中的ReLU6替换为ReLU:
model = QuantizableMobileNetV2(block=QuantizableInvertedResidual, **kwargs)
_replace_relu(model)
Step2:算子折叠
算子折叠是将模型的多个层合并成一个层,一般用来减少计算量和加速推理。对于量化感知训练而言,算子折叠作用是将模型变“薄”,减少中间计算过程的误差积累。
以下比较有无算子折叠的结果(上:无算子折叠,下:有算子折叠,打印执行prepare_qat()后的模型)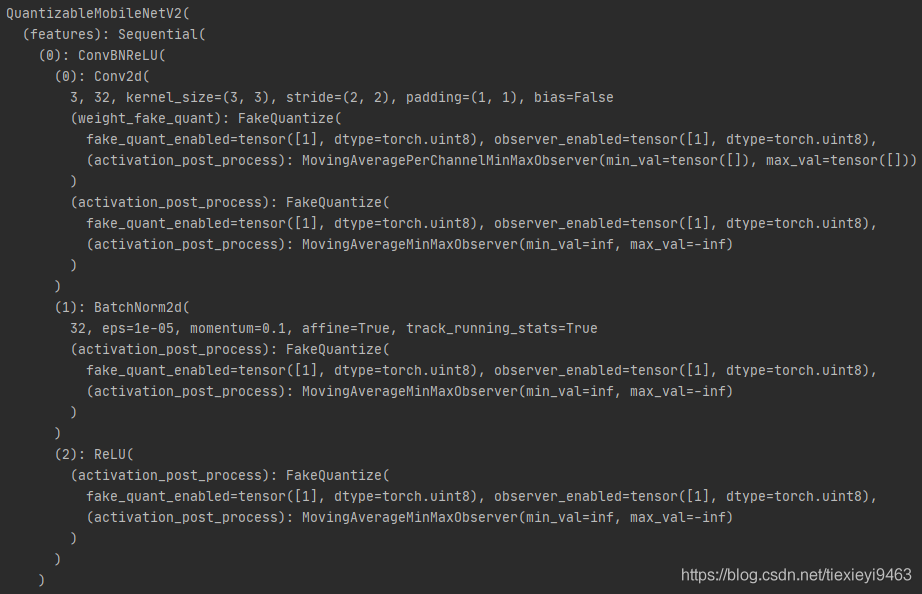
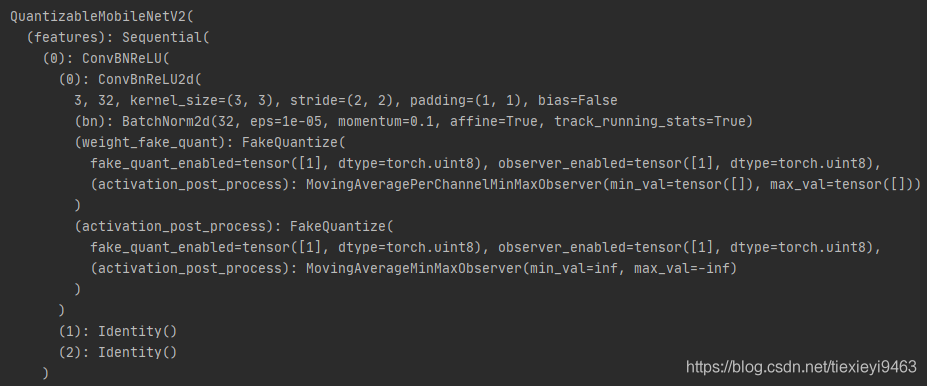 如果不进行算子折叠,每个Conv-BN-ReLU单元一共会插入4个FakeQuantize模块。而进行算子折叠后,原来Conv2d()被ConvBnReLU2d()代替(3层合并到了第1层),BatchNorm2d()和ReLU()被Inentity()代替(仅作为占位),最终只插入了2个FakeQuantize模块。
如果不进行算子折叠,每个Conv-BN-ReLU单元一共会插入4个FakeQuantize模块。而进行算子折叠后,原来Conv2d()被ConvBnReLU2d()代替(3层合并到了第1层),BatchNorm2d()和ReLU()被Inentity()代替(仅作为占位),最终只插入了2个FakeQuantize模块。
FakeQuantize模块的减少意味着推理过程中进行的量化-反量化的次数减少,有利于减少量化带来的性能损失。
算子折叠由实现torch.quantization.fuse_modules()。目前存在的比较遗憾的2点:
算子折叠不能自动完成,只能由程序员手工指定要折叠的子模型。以torchvision.models.quantization.mobilenet_v2()中实现的算子折叠函数为例:
def fuse_model(self):
# 遍历模型内的每个子模型,判断类型并进行相应的算子折叠
for m in self.modules():
if type(m) == ConvBNReLU:
fuse_modules(m, ['0', '1', '2'], inplace=True)
if type(m) == QuantizableInvertedResidual:
# 调用子模块实现的fuse_model(),间接调用fuse_modules()
m.fuse_model()
能折叠的算子组合有限。目前支持的算子组合为:ConV + BN、ConV + BN + ReLU、Conv + ReLU、Linear + ReLU、BN + ReLU。如果尝试折叠ConvTranspose2d、ReLU6等不支持的算子则会报错。
Step3:指定量化方案
目前支持fbgemm和qnnpack两种backend方案。官方推荐x86平台使用fbgemm方案,ARM平台使用qnnpack方案。 量化方案通过如下方法指定
model.qconfig = get_default_qat_qconfig(backend="fbgemm")
# 或
model.qconfig = get_default_qat_qconfig(backend="qnnpack")
即通过给model增加一个名为qconfig为成员变量并赋值。
量化方案可通过设置qconfig自定义,本文暂不讨论。
Step4:插入伪量化模块
通过执行prepare_qat(),实现按qconfig的配置方案给每个层增加FakeQuantize()模块 每个FakeQuantize()模块内包含相应的Observer()模块,在模型执行forward()时自动记录数值,供实施量化时使用。
Step5:实施量化
完成训练后,通过执行convert()转换为真正的int8量化模型。 完成转换后,FakeQuantize()模块被去掉,原来的ConvBNReLU2d()算子被替换为QuantizedConvReLU2d()算子。
完成转换后,FakeQuantize()模块被去掉,原来的ConvBNReLU2d()算子被替换为QuantizedConvReLU2d()算子。
Step6:int8模型推理
int8模型的调用方法与普通的fp32模型的调用无异。需要注意的是,目前量化算子仅支持CPU计算,故须确保输入和模型都在CPU侧。
若模型推理中出现报错,一般是前面的步骤存在设置不当,参考常见问题第1点。
常见问题
(1) RuntimeError: Could not run XX with arguments from the YY backend. XX is only available for these backends ZZ
虽然fp32模型和int8模型都能在CPU上推理,但fp32算子仅接受tensor作为输入,int8算子仅接受quantedtensor作为输入,输入和算子的类型不一致导致上述错误。
一般排查方向为:是否完成了模型修改,将加法等操作替换为量化版本;是否正确添加了QuantStub()和DeQuantStub();是否在执行convert()前是否执行了model.eval()(在traning模型下,dropout无int8实现但没有被去掉,然而在执行推理时会报错)。
(2) 是否支持GPU训练,是否支持DistributedDataParallel训练?
支持。官方有一个完整的量化感知训练的实现,使用了GPU和DistributedDataParallel,可惜在文档和教程中未提及,参考这里(https://github.com/pytorch/vision/blob/master/references/classification/train_quantization.py)。
(3) 是否支持混合精度模型(例如一部分fp32推理,一部分int8推理)?
官方没有明确说明,但经实践是可以的。
模型是否进行量化取决于是否带qconfig。因此可以将模型定义修改为
class MixModel(nn.Module):
def __init__(self):
super(MixModel, self).__init__()
self.fp32_part = Fp32Model()
self.int8_part = Int8Model()
def forward(self, x):
x = self.int8_part(x)
x = self.fp32(x)
return x
mix_model = MixModel()
mix_model.int8_part.qconfig = get_default_qat_qconfig(BACKEND)
prepare_qat(mix_model, inplace=True)
由此可实现所需的功能。注意将QuantStub()、Dequant()模块移到Int8Model()中。
(4)精度保持效果如何,如何提升精度?
笔者进行的实验不多,在做过的简单的OCR任务中,可以做到文字检测和识别模型的指标下降均不超过1个点(量化的int8模型对比正常训练的fp32模型)。官方教程中提供了分类例子的效果和提升精度的技巧,可供参考。
总结
Pytorch官方提供的量化感知训练API,上手较为简单,易于集成到现有训练代码中。但目前手动修改模型和算子折叠增加了一定的工作量,期待在未来版本的改进。
- END -欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。