
Pytorch量化之图像超分量化,附实例与code

极市导读
作者使用图像超分为例提供了一个完整的可复现的量化示例,以EDSR为例,模型大小73%,推理速度提升了40%左右,视觉效果几乎无损。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
最近作者在尝试进行图像超分的INT8量化,发现:pytorch量化里面的坑真多,远不如TensorFlow的量化好用。不过花了点时间终于还是用pytorch把图像超分模型完成了量化,以EDSR为例,模型大小73%,推理速度提升40%左右(PC端),视觉效果几乎无损,定量指标待补充。有感于网络上介绍量化的博客一堆,但真正有帮助的较少,所以Happy会尽量以图像超分为例提供一个完整的可复现的量化示例。
背景
量化在不同领域有不同的定义,而在深度学习领域,量化有两个层面的意义:(1) 存储量化,即更少的bit来存储原本需要用浮点数(一般为FP32)存储的tensor;(2) 计算量化,即用更少的bit来完成原本需要基于浮点数(一般为FP32,FP16现在也是常用的一种)完成的计算。量化一般有这样两点好处:
更小的模型体积,理论上减少为FP32模型的75%左右,从笔者不多的经验来看,往往可以减少73%; 更少的内存访问与更快的INT8计算,从笔者的几个简单尝试来看,一般可以加速40%左右,这个还会跟平台相关。
对于量化后模型而言,其部分或者全部tensor(与量化方式、量化op的支持程度有关)将采用INT类型进行计算,而非量化前的浮点类型。量化对于底层的硬件支持、推理框架等要求还是比较高的,目前X86CPU,ARMCPU,Qualcomm DSP等主流硬件对量化都提供了支持;而NCNN、MACE、MNN、TFLite、Caffe2、TensorRT等推理框架也都对量化提供了支持,不过不同框架的支持度还是不太一样,这个就不细说了,感兴趣的同学可以自行百度一下。
笔者主要用Pytorch进行研发,所以花了点精力对其进行了一些研究&尝试。目前Pytorch已经更新到了1.7版本,基本上支持常见的op,可以参考如下:
Activation:ReLU、ReLU6、Hardswish、ELU; Normalization:BatchNorm、LayerNorm、GroupNorm、InstanceNorm; Convolution:Conv1d、Conv2d、Conv3d、ConvTranspose1d、ConvTranspose2d、Linear; Other:Embedding、EmbeddingBag。
目前Pytorch支持的量化有如下三种方式:
Post Training Dynamic Quantization:动态量化,推理过程中的量化,这种量化方式常见诸于NLP领域,在CV领域较少应用; Post Training Static Quantization:静态量化,训练后静态量化,这是CV领域应用非常多的一种量化方式; Quantization Aware Training:感知量化,边训练边量化,一种比静态量化更优的量化方式,但量化时间会更长,但精度几乎无损。
注:笔者主要关注CV领域,所以本文也将主要介绍静态量化与感知量化这种方式。
Tensor量化
要实现量化,那么就不可避免会涉及到tensor的量化,一般来说,量化公式可以描述如下:
目前Pytorch中的tensor支持int8/uint8/int32等类型的数据,并同时scale、zero_point、quantization_scheme等量化信息。这里,我们给出一个tensor量化的简单示例:
x = torch.rand(3, 3)print(x)x = torch.quantize_per_tensor(x, scale=0.2, zero_point=3, dtype=torch.quint8)print(x)print(x.int_repr())
一个参考输出如下所示:
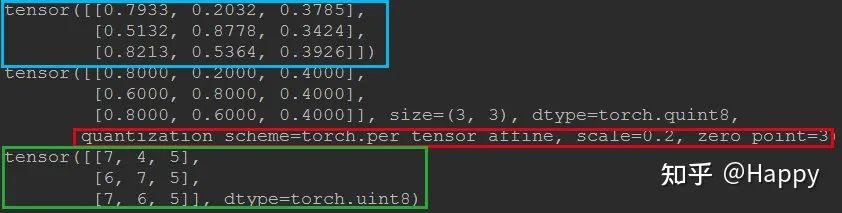
注1:蓝框为原始的浮点数据,红框为tensor的量化信息,绿框则对应了量化后的INT8数值。
注2:量化不可避免会出现精度损失,这个损失与scale、zero_point有关。
在量化方面,Tensor一般有两种量化模式:per tensor与per channel。对于PerTensor而言,它的所有数值都按照相同方式进行scale和zero_point处理;而对于PerChannel而言,它有多种不同的scale和zero_point参数,这种方式的量化精度损失更少。
Post Training Static Quantization
静态量化一般有两种形式:(1) 仅weight量化;(2) weight与activation同时量化。对于第一种“仅weight量化”而言,只针对weight量化可以使得模型参数所占内存显著减小,但在实际推理过程中仍需要转换成浮点数进行计算;而第二种“weight与activation同时量化”则不仅对weight进行量化,还需要结合校验数据进行activation的量化。第一种的量化非常简单,这里略过,本文仅针对第二种方式进行介绍。
Pytorch的静态量化一把包含五个步骤:
fuse_model:该步骤用来对可以融合的op进行融合,比如Conv与BN的融合、Conv与ReLU的融合、Conv与BN以及ReLU的融合、Linear与BN的融合、Linear与BN以及ReLU的融合。目前Pytorch已经内置的融合code:
fuse_modules(model, modules_to_fuse, inplace=False, fuser_func=fuse_known_modules, fuse_custom_config_dict=None)在完成融合后,第一个op将被替换会融合后的op,而其他op则会替换为nn.Identity。
qconfig:该步骤用于设置用于模型量化的方式,它将插入两个observer,一个用于监测activation,一个用于监测weight。考虑到推理平台的不同,pytorch提供了两种量化配置:针对x86平台的 fbgemm以及针对arm平台的qnnpack。
不同平台的量化配置方式存在些微的区别,大概如下:
| backend | activation | weight |
|---|
Prepare:该步骤用于给每个支持量化的模块插入Observer,用于收集数据并进行量化数据分析。以activation为例,它将根据所喂入数据统计min_val与max_val,一般观察几个次迭代即可,然后根据所观察到数据进行统计分析得到scale与zero_point。 Feed Data:为了更好的获得activation的量化参数信息,我们需要一个合适大小的校验数据,并将其送入到前述模型中。这个就比较简单了,就按照模型验证方式往里面送数据就可以了。 Convert:在完成前述四个步骤后,接下来就需要将完成量化的模型转换为量化后模型了,这个就比较简单了,通过如下命令即可。
torch.quantization.convert(model, inplace=True)
该过程本质上就是用量化OP替换模型中的费量化OP,比如用nnq.Conv2d替换nn.Conv2d, nnq.ConvReLU2d替换nni.ConvReLU2d(注:这是Conv与ReLU的合并)。之前的量化op以及对应的被替换op列表如下:
DEFAULT_STATIC_QUANT_MODULE_MAPPINGS = {QuantStub: nnq.Quantize,DeQuantStub: nnq.DeQuantize,: nnq.BatchNorm2d,: nnq.BatchNorm3d,: nnq.Conv1d,: nnq.Conv2d,: nnq.Conv3d,: nnq.ConvTranspose1d,: nnq.ConvTranspose2d,: nnq.ELU,: nnq.Embedding,: nnq.EmbeddingBag,: nnq.GroupNorm,: nnq.Hardswish,: nnq.InstanceNorm1d,: nnq.InstanceNorm2d,: nnq.InstanceNorm3d,: nnq.LayerNorm,: nnq.LeakyReLU,: nnq.Linear,: nnq.ReLU6,# Wrapper Modules:: nnq.QFunctional,# Intrinsic modules:: nniq.BNReLU2d,: nniq.BNReLU3d,: nniq.ConvReLU1d,: nniq.ConvReLU2d,: nniq.ConvReLU3d,: nniq.LinearReLU,: nnq.Conv1d,: nnq.Conv2d,: nniq.ConvReLU1d,: nniq.ConvReLU2d,: nniq.ConvReLU2d,: nniq.LinearReLU,# QAT modules:: nnq.Linear,: nnq.Conv2d,}
在完成模型量化后,我们就要考虑量化模型的推理了。其实量化模型的推理与浮点模型的推理没什么本质区别,最大的区别有这么两点:
量化节点插入:需要在网络的forward里面插入QuantStub与DeQuantSub两个节点。一个非常简单的参考示例,摘自torchvision.model.quantization.resnet.py。
class QuantizableResNet(ResNet):def __init__(self, *args, **kwargs):super(QuantizableResNet, self).__init__(*args, **kwargs)self.quant = torch.quantization.QuantStub()self.dequant = torch.quantization.DeQuantStub()def forward(self, x):x = self.quant(x)# Ensure scriptability# super(QuantizableResNet,self).forward(x)# is not scriptablex = self._forward_impl(x)x = self.dequant(x)return x
op替换:需要将模型中的Add、Concat等操作替换为支持量化的FloatFunctional,可参考如下示例。
class QuantizableBasicBlock(BasicBlock):def __init__(self, *args, **kwargs):super(QuantizableBasicBlock, self).__init__(*args, **kwargs)self.add_relu = torch.nn.quantized.FloatFunctional()def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out = self.add_relu.add_relu(out, identity)return out
准备工作
在真正开始量化之前,我们需要准备好要进行量化的模型,本文以EDSR-baseline模型为基础进行。所以大家可以直接下载官方预训练模型,EDSR的Pytorch官方实现code连接如下:
github.com/thstkdgus35/EDSR-PyTorch
EDSRx4-baseline预训练模型下载连接如下:
https://cv.snu.ac.kr/research/EDSR/models/edsr_baseline_x4-6b446fab.pt
除了要准备上述预训练模型与code外,我们还需要准备校验数据,在这里笔者采用的DIV2K数据,该数据集下载链接如下:
https://cv.snu.ac.kr/research/EDSR/DIV2K.tar模型转换
正如上一篇文章所介绍的,在量化之前需要对模型进行op融合操作,而EDSR官方的实现code是对于融合操作是不太方便的,所以笔者对EDSR进行了一些实现上的调整。调整成如下形式(注:这里的实现code部分参数写成了固定参数):
class ResBlock(nn.Module):def __init__(self, channels=64):super(ResBlock, self).__init__()self.conv1 = nn.Conv2d(channels, channels, 3, 1, 1)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(channels, channels, 3, 1, 1)def forward(self, x):identity = xconv1 = self.conv1(x)relu = self.relu(conv1)conv2 = self.conv2(relu)output = conv2 + identityreturn outputclass EDSR(nn.Module):def __init__(self,num_blocks=16,num_features=64,block=ResBlock):super(EDSR, self).__init__()self.head = nn.Conv2d(3, num_features, 3, 1, 1)body = [block(num_features) for _ in range(num_blocks)]body.append(nn.Conv2d(num_features, num_features, 3, 1, 1))self.body = nn.Sequential(*body)self.tail = nn.Sequential(nn.Conv2d(num_features, num_features * 4, 3, 1, 1),nn.PixelShuffle(upscale_factor=2),nn.Conv2d(num_features, num_features * 4, 3, 1, 1),nn.PixelShuffle(upscale_factor=2),nn.Conv2d(num_features, 3, 3, 1, 1))def forward(self, x, **kwargs):x = self.head(x)res = self.body(x)res += xx = self.tail(res)return x
也许有同学会说,模型转换后原始的预训练模型还能导入吗?直接导入肯定是不行的,checkpoint的key发生了变化,所以我们需要对下载的checkpoint进行一下简单的转换。checkpoint的转换code如下(注:这些转换可以都是写死的,已经确认过的):
checkpoint = torch.load("edsr_baseline_x4-6b446fab.pt", map_location='cpu')newStateDict = OrderedDict()for key, val in checkpoint.items():if 'head' in key:newStateDict[key.replace('.0.', '.')] = valelif 'mean' in key:continue# newStateDict[key] = valelif 'tail' in key:if '.0.0.' in key:newStateDict[key.replace('.0.0.', '.0.')] = valelif '.0.2.' in key:newStateDict[key.replace('.0.2.', '.2.')] = valelse:newStateDict[key.replace('.1.', '.4.')] = valelif 'body' in key:if '.body.0.' in key:newStateDict[key.replace(".body.0.", '.conv1.')] = valelif '.body.2.' in key:newStateDict[key.replace(".body.2.", '.conv2.')] = valelif "16" in key:newStateDict[key] = valtorch.save(newStateDict, "edsr-baseline-fp32.pth.tar")
对比原始code的同学应该会发现:EDSR中的add_mean与sub_mean不见了。是的,笔者将add_mean与sub_mean移到了网络外面,不对其进行量化,具体为什么这样做,见后面的介绍。
除了上述操作外,我们还需要提供前述EDSR实现的量化版本模型,这个没太多需要介绍的,直接看code(主要体现在三点:插入量化节点(即QuantStub与DequantStub)、add转换(即FloatFunctional)、fuse_model模块(即fuse_model函数)):
class QuantizableResBlock(ResBlock):def __init__(self, *args, **kwargs):super(QuantizableResBlock, self).__init__(*args, **kwargs)self.add = FloatFunctional()def forward(self, x):identity = xconv1 = self.conv1(x)relu = self.relu(conv1)conv2 = self.conv2(relu)output = self.add.add(identity, conv2)return outputdef fuse_model(self):fuse_modules(self, ['conv1', 'relu'], inplace=True)class QuantizableEDSR(EDSR):def __init__(self, *args, **kwargs):super(QuantizableEDSR, self).__init__(*args, **kwargs)self.quant = QuantStub()self.dequant = DeQuantStub()self.add = FloatFunctional()def forward(self, x):x = self.quant(x)x = self.head(x)res = self.body(x)res = self.add.add(res, x)x = self.tail(res)x = self.dequant(x)return xdef fuse_model(self):for m in self.modules():if type(m) == QuantizableResBlock:m.fuse_model()
模型量化
在上一篇文章中,我们也介绍了PTSQ的几个步骤(额外包含了模型的构建与保存)。
init: 模型的定义、预训练模型加载、inplace操作替换为非inplace操作; config:定义量化时的配置方式,这里以 fbgemm为例,它的activation量化方式为Historam,weight量化方式为per_channel;fuse:模型中的op融合,比如相邻的Conv+ReLU融合,Conv+BN+ReLU融合等等; prepare: 量化前的准备工作,也就是对每个需要进行量化的op插入Observer; feed: 送入校验数据,前面插入的Observer会针对这些数据进行量化前的信息统计; convert:用于在将非量化op转换成量化op,比如将nn.Conv2d转换成nnq.Conv2d, 同时会根据Observer所观测的信息进行nnq.Conv2d中的量化参数的统计,包含scale、zero_point、qweight等; save:用于保存量化好的模型参数.
Init
模型的创建与预训练模型,这个比较简单了,直接上code(注:PTSQ模式下模型应当是eval模式)。
checkpoint = torch.load("edsrx4-baseline-fp32.pth.tar")model = QuantizableEDSR(block=QuantizableResBlock)model.load_state_dict(checkpoint)_replace_relu(model)model.eval()
config
这个步骤主要是为了指定与推理引擎搭配的一些量化方式,比如X86平台应该采用fbgemm方式进行量化,而ARM平台则应当采用qnnpack方式量化。本文主要是在PC端进行,所以选择了fbgemm进行,相关配置信息如下:
backend = 'fbgemm'torch.backends.quantized.engine = backendmodel.qconfig = torch.quantization.QConfig( activation=default_histogram_observer, weight=default_per_channel_weight_observer)
Fuse&Prepare
Fuse与Prepare两个步骤的作用主要是
进行OP的融合,比如Conv+ReLU的融合,Conv+BN+ReLU的融合,这个可以见前述实现code中的'fuse_model',pytorch目前提供了几种类型的融合。我们只需知道就可以了,这块不用太过关心,两行code就可以完成:
model.fuse_model()torch.quantization.prepare(model, inplace=True)
插入Observer,在每个需要进行量化的op中插入Observer,不同的量化方式会有不同的Observer,它将对喂入的校验数据进行统计,比如统计数据的最大值、最小值、直方图分布等等。
Feed
这个步骤需要采用校验数据喂入到上述准备好的模型中,这个就比较简单了,按照常规模型的测试方式处理就可以了,参考code如下:
注:笔者这里用了100张数据,这个用全部也可以,不过耗时会更长meanBGR = torch.FloatTensor((0.4488, 0.4371, 0.4040)).view(3, 1, 1) * 255data_root = "${DIV2K_train_LR_bicubic/X4}"for index in range(1, 100):image_path = os.path.join(data_root, f"{index:04d}.png")inputs = preprocess(image_path)inputs -= meanBGRwith torch.no_grad():output = model(inputs)
Convert&Save
在完成前面几个步骤后,我们就可以将浮点类型的模型进行量化了,这个只需要一行code就可以。在转换过程中,它会将nn.Conv2d这类浮点类型op转换成量化版op:nnq.Conv2d。
torch.quantization.convert(model, inplace=True)torch.save(model.state_dict(), "edsrx4-baseline-qint8.pth.tar")
经过上面的几个步骤,我们就完成了EDSR模型的INT8量化,也将其进行了保存。也就是说完成了初步的量化工作,因为接下来的测试论证很关键,如果量化损失很严重也不行的。
量化模型测试
接下来,我们对上述量化好的模型进行一下测试看看效果。量化模型的调用code如下(与常规模型的调用有一点点的区别):
def fp32edsr(block=ResBlock, pretrained=None):model = EDSR(block=block)if pretrained:state_dict = torch.load(pretrained, map_location="cpu")model.load_state_dict(state_dict)return modeldef qint8edsr(block=QuantizableResBlock, pretrained=None, quantize=False):model = QuantizableEDSR(block=block)_replace_relu(model)if quantize:backend = 'fbgemm'quantize_model(model, backend)else:assert pretrained in [True, False]if pretrained:state_dict = torch.load(pretrained, map_location="cpu")model.load_state_dict(state_dict)return modeldef quantize_model(model, backend):if backend not in torch.backends.quantized.supported_engines:raise RuntimeError("Quantized backend not supported ")torch.backends.quantized.engine = backendmodel.eval()_dummy_input_data = torch.rand(1, 3, 64, 64)# Make sure that weight qconfig matches that of the serialized modelsif backend == 'fbgemm':model.qconfig = torch.quantization.QConfig(activation=torch.quantization.default_histogram_observer,weight=torch.quantization.default_per_channel_weight_observer)elif backend == 'qnnpack':model.qconfig = torch.quantization.QConfig(activation=torch.quantization.default_histogram_observer,weight=torch.quantization.default_weight_observer)model.fuse_model()torch.quantization.prepare(model, inplace=True)model(_dummy_input_data)torch.quantization.convert(model, inplace=True)
从上面code可以看到:相比fp32模型,量化模型多了两步骤:
replace=True的op替换为replace=False的op; 模型的最简单量化版本,完成初步的op替换。
结合上述code,我们就可以直接对DIV2K数据进行测试了,测试的部分code摘录如下:
index = 1image_path = os.path.join(data_root, f"{index:04d}.png")inputs = preprocess(image_path)inputs -= meanBGRwith torch.no_grad():output1 = model(inputs)output2 = fmodel(inputs)output1 += meanBGRoutput2 += meanBGRshow1 = post_process(output1)cv2.imwrite(f"results/{index:03d}-init8.png", show1)show2 = post_process(output2)cv2.imwrite(f"results/{index:03d}-fp32.png", show2)

上图给出了DIV2K训练集中0016的两种模型的效果对比,左图为FP32模型的超分效果,右图为INT8量化模型的超分效果。可以看到:量化后模型在效果上是视觉无损的(就是说:量化损失导致的效果下降不可感知)。总而言之,量化前后模型大小减少73%,推理延迟减少43%。
注意事项
为什么要将add_mean与sub_mean移到网络外面不参与量化呢?
从我们的量化对比来看,将其移到外面效果更佳。可能也跟add_mean与sub_mean中的参数有关,两者只是简单的均值处理, 这个地方的量化会导致weight值出现较大偏差,进而影响后续的量化精度。
在量化方式方面,该如何选择呢?
在量化方式方面,activation支持:HistogramObserver,MinMaxObserver,, weight支持:PerChannelMinMaxObserver,MinMaxObserver. 从我们的量化对比来看,Histogram+PerChannelMinMax这种组合要比MinMaxObserver+PerChannelMinMax更佳。下图给出了DIV2K训练集中0018数据采用第二种量化组合效果对比,可以感知到明显的量化损失。

参考文章
如何使用PyTorch的量化功能?(https://mp.weixin.qq.com/s/wzAgIS1Omm-K-4-tx68CCQ)
PyTorch模型量化工具学习(https://zhuanlan.zhihu.com/p/144025236)
Pytorch实现卷积神经网络训练量化(https://zhuanlan.zhihu.com/p/164901397)
推荐阅读
