
OpenAI新发现:GPT-3做小学数学题能得55分,验证胜过微调!
 大数据文摘授权转载在AI科技评论
大数据文摘授权转载在AI科技评论
论文地址:https://arxiv.org/pdf/2110.14168.pdf
数据集地址:https://github.com/openai/grade-school-math
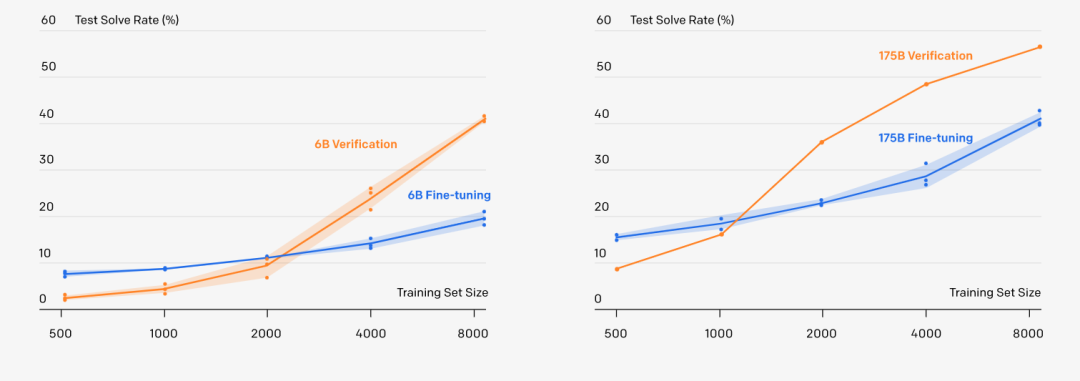
训练验证器:从错误中学习的模型
训练验证器:从错误中学习的模型
高质量:GSM8K中的问题都是人工设计的,避免了错误问题的出现。
高多样性:GSM8K中的问题都被设计得相对独特,避免了来自相同语言模板或仅在表面细节上有差异的问题。
中等难度:GSM8K中的问题分布对大型SOTA语言模型是有挑战的,但又不是完全难以解决的。这些问题不需要超出早期代数水平的概念,而且绝大多数问题都可以在不明确定义变量的情况下得到解决。
自然语言解决方案:GSM8K中的解决方案是以自然语言而不是纯数学表达式的形式编写的。模型由此生成的解决方案也可以更容易被人理解。此外,OpenAI也期望它能阐明大型语言模型内部独白的特性。

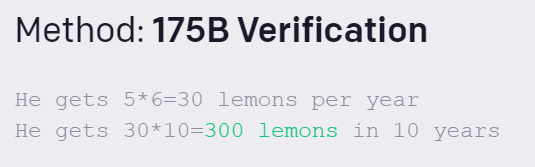


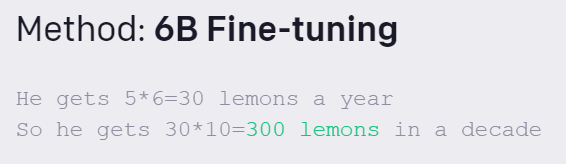
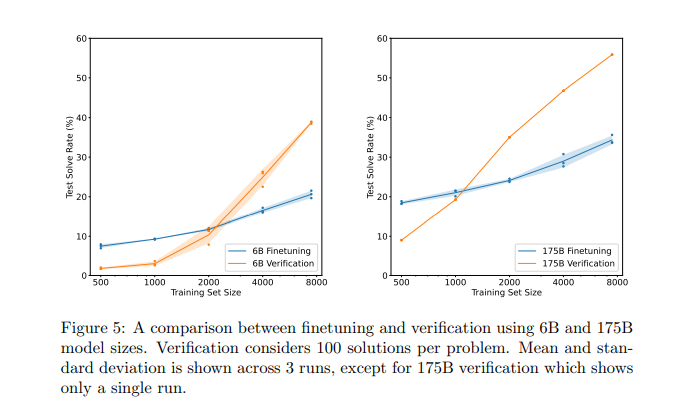
新方法是如何验证的
新方法是如何验证的
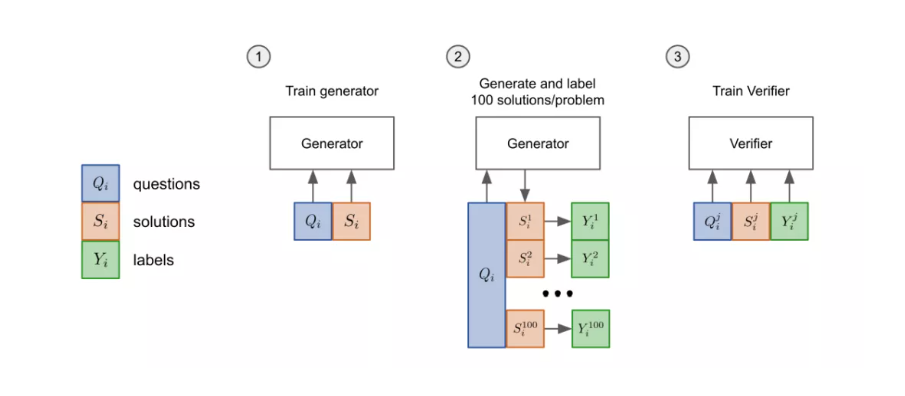
先把模型的「生成器」在训练集上进行2个epoch的微调。
从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。
在数据集上,验证器再训练单个epoch。
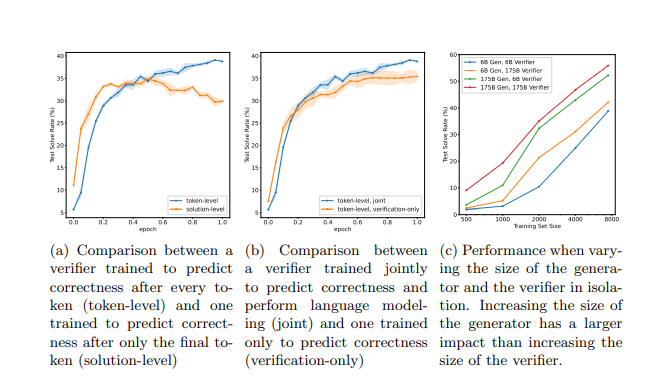
写在最后
写在最后
参考链接:
评论