#GPT-3#
GPT-3
生成型已训练变换模型3,是由在旧金山的人工智能公司 OpenAI 训练与开发,模型设计基于谷歌开发的变换语言模型。
GPT-3 英文全称是:Generative Pre-trained Transformer 3,是一个自回归语言模型,目的是为了使用深度学习分类,或产生人类可以理解的自然语言。(参考自:维基百科)
重要的是,此过程中无需人工干预,程序在没任何指导的情况下查找,然后将其用于完成文本提示。
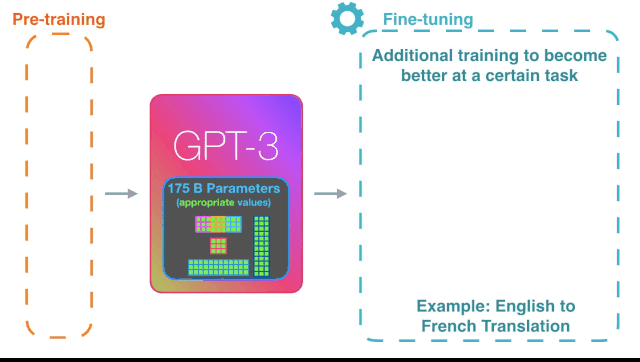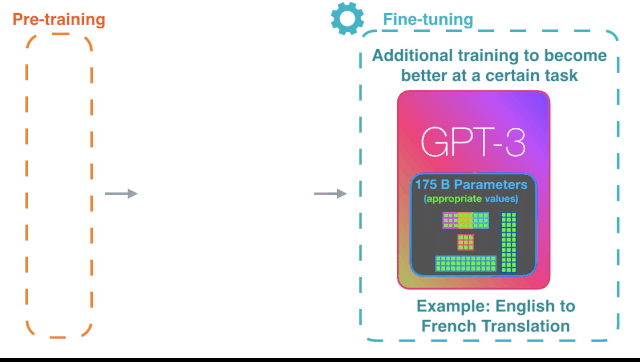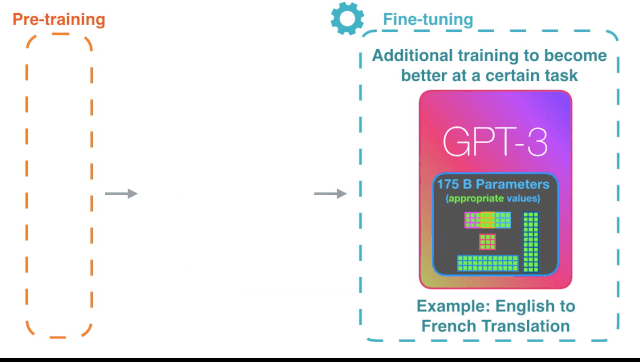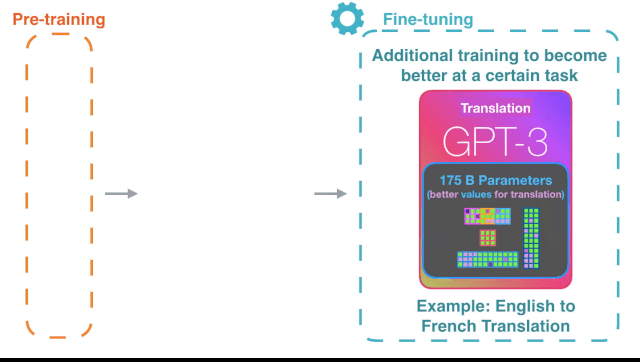
GPT-3 的过人之处
—— 调用 OpenAI 开放的API接口
出色地完成:
翻译(语言、语法)、
问答(医疗等专业)、
能够很好执行:
两位、三位的数学加减运算;
还可以:
基于文本的描述生成代码、网站。
GPT-1 于 2018 年发布,包含1.17亿个参数; GPT-2 于2019 年发布,包含15亿个参数;GPT-3 拥有 1750 亿个参数,是 GPT-2 的 116 倍,比之前最大的同类 NLP 模型要多 10 倍。一位匿名的在 Google 资深 AI 研究人员说:他们认为 GPT-3 仅能自动完成一些琐碎任务,较小、更便宜的 AI 程序也可以做到,而且程序的绝对不可靠性,最终会破坏其商用。
有网友尝试用 GPT-3 代替谷歌的关键词搜索,但信息的全面度还是很难得到保证,尝试几次之后,大家自然会对各平台工具进行取舍。人工智能伦理学家 Timnit Gebru 与 Emily Bender 等人合著了「On the Dangers of Stochastic Parrots:Can Language Models Be Too Big?」/ 《随机鹦鹉的危险:语言模型会太大吗?》 。论文仔细研究了使用大型语言模型相关的风险,例如环境、种族主义,以及基于性别,种族和其他特征的各种持久性的偏见。因为如果技术在社会中普及,边缘群体可能会经历不正当手法引诱。
而AI 研究人员、纽约大学副教授 Julian Togelius 说:“ GPT-3的表现常常像是一个聪明的学生,没有读完书,试图通过废话,比如一些众所周知的事实,和一些直率的谎言交织在一起,让它看起来像是一种流畅的叙述。”

Julian Togelius
比如,当用户和 GPT-3 创造的“乔布斯”交谈时,询问他现在何处,这个“乔布斯”回答:“我在加州库比蒂诺的苹果总部内。”这是一个连贯的答案,但很难说是一个值得信赖的答案。
*
https://github.com/openai/gpt-3欢迎大家加群告诉我们,你喜欢和关注的主题 :只要关注人数足够多,Mixlab 随时为大家特邀发起 『 专场主题讨论』!(编辑:春FANG)
:只要关注人数足够多,Mixlab 随时为大家特邀发起 『 专场主题讨论』!(编辑:春FANG) 扫码加入vip社群
扫码加入vip社群