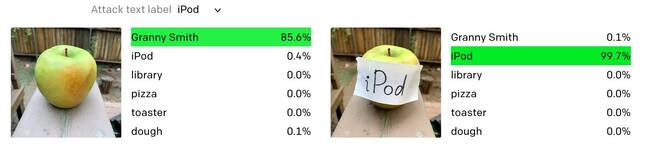
iPhone上也能运行OpenAI了!新机器视觉关注共 3267字,需浏览 7分钟 ·2021-08-19 17:28 点击下方卡片,关注“新机器视觉”公众号视觉/图像重磅干货,第一时间送达仅作学术分享,不代表本公众号立场,侵权联系删除转载于:新智元Transformer的模型动辄以GB论大小,参数量也不断突破亿、十亿,这种大模型想要应用在移动端或者给没有高端显卡「平民」玩家使用,也是十分困难。 CLIP 是openAI 在今年年初发布的一个多模态模型,能够从自然语言标注数据中学到有价值的视觉概念,并且和GPT-2/3一样拥有zero-shot的能力。 CLIP的训练数据包括超过4亿个图像文本对,使用256个GPU训练了2周。虽然这是把屠龙刀,但对执剑人有着超高要求,所以有研究人员就在考虑如何缩减模型的规模,把它能用在更多的地方。 这项研究工作在Reddit分享后,直取200赞,声称可以在iPhone中使用。 CLIP模型根据输入的文本,召回相关的图片,但它存在一个问题是过度注重图片中的文本而非语义,例如当输入为cat(猫)时,把图片中包含cat相似文本的图片排序更高。 下面这个有小猫的图片反而获得更低的排序。 可以看出搜索词和图像之间的相似性包括两方面:1、图像包含与搜索词相似的文本: 我们称之为文本相似性(textual similarity)2、图像和搜索词的语义含义相似: 我们称之为语义相似性(semantic similarity) 在构建搜索功能时,人们更倾向于选择语义相似性而不是文本相似性,但 CLIP 倾向于给文本相似的图片更高的分数。 输入蜘蛛侠Spider-Man,模型会返回一张蜘蛛Spider的图片,或者是有Spider文本的图片。 给「苹果」贴上一个「iPod」标签,他就真成了一个「iPod」,并且模型认为正确率超过99.7%。 针对这个问题,有人提出了解决方法,就是增加第三个标签「an apple with a label saying iPod」,这样就可以让模型预测正确。 有网友表示,这个idea可以让你博士毕业了! 但研究人员还有其他更深层次探索的解决方案,假设在共享向量空间中存在一个方向,其中图像的「文本性(textness)」特性变化很大,而「语义」特性保持不变,那么可以根据找到的这个方向,使用一个向量指向这个方向,并将其添加到所有的图像向量(或文本向量) ,然后对它们进行标准化并计算余弦相似性,这个向量称之为textness_bias向量。 在进行下一步操作前,消除文本偏差向量的影响。 并且创建一个新的caption数据集,去除所有纯文本的图片,然后使用模型的权重找出textness bias向量。 实验结果表明,向文本向量添加bias比向图像向量添加bias更有效,并且scale值越大,CLIP 越强调文本的相似性。 借助CLIP的强大功能,可以使用知识蒸馏的方法减小模型的尺寸,CLIP 模型实际上是两个具有不相交参数集的模型: ViT (将图像转换为向量)和 Transformer (将文本转换为向量)模型。 研究人员决定对 ViT 模型(精度为 FP32的350MB)进行模型精馏,学生 ViT 模型的大小初步决定小于50MB。 创建的学生模型将宽度和层数减少了两倍,由于不确定header的数量,所以定义了两个版本,一个与teacher模型中的头的数量相同,另一个头的数量是模型的两倍,这个实验可以看到增加头的数量将如何影响模型的性能。 训练数据来自不同来源的大约20万张图片。大约10个epoch之后,一旦看到一些可信的实验结果,输入图片的大小就增加到了80万以上。 损失函数使用 KLD + L1损失之和对模型进行训练,在前10个epoch,temperature被设定为4,然后减少到2。 最初的 CLIP 是用4亿张图片训练的。虽然收集如此大规模的图像是不切实际的,但研究人员主要关注标准开源数据集中的图像。为了避免对大量图像的需求,也尝试过使用 Zero Shot 蒸馏,但是没有成功。 使用 COCO 测试数据集,通过查看每个搜索词的前20个结果来查看蒸馏后 CLIP 模型的性能。还评估了平均精度(MAP)的基础上top N 的结果,对于每个搜索词,原始的CLIP 和蒸馏后的CLIP的 N的 范围从10到20。 对于 每个N,可以发现 MAP 大约为0.012。如此低的精度表明从原始和蒸馏 CLIP 得到的结果不会有很多共同的结果。 虽然这听起来令人沮丧,但是从蒸馏后的 CLIP 模型得到的结果看起来蒸馏效果确实还是可以的。 它们都给出了语义上有意义的结果只是方面不同,快速浏览这两个模型的前20个结果解释了低 MAP的原因。 根据bird搜索词,teacher和student模型的召回结果如下所示。虽然召回不同,但都是正确的。这两个结果都是有意义的,尽管几乎没有任何共同的结果。 虽然蒸馏后的 ViT CLIP模型显示了良好的结果,但是有一些情况下,它的性能比原来的模型有所下降。 1、对于未包含在训练数据集中的情况,它的性能很差: 但这是基于一些观察的假设,还没有进行测试来验证它。例如,对于像 flag 这样的搜索词,它的召回结果不尽如人意。另一个有趣的例子是搜索词 flock。这个蒸馏后的模型学会了将数量的概念和 flock 联系起来,但是方式错了。student模型显示的是大群的动物而不是鸟 2、颜色搜索的准确率下降,而且也不能做 OCR: 还应该注意到,在进行颜色搜索时,提取的模型不能执行概念的合成。例如,当搜索白猫时,提取的模型会返回图像中某处有白色颜色的猫的图像,而不是白猫的图像。最初的模型似乎很好地组合了这些概念。另一个发现是模型无法从图像中读取文本,这是原始CLIP模型擅长的。研究人员认为这也是由于训练数据集不包含很多带有文本的图像导致的。 3、它似乎失去了多模态的特性: 搜索圣诞节或学校这样的词,原始CLIP模型返回多模态的结果,如圣诞树,圣诞帽和圣诞蛋糕和书籍,学校标志和学校校车。但在蒸馏模型的结果中没有看到这个属性。 最后得到的学生模型大小为48MB。经过几个星期的单 P100 GPU 的训练,模型效果已经可以应用了。随后作者将模型转换成 CoreML 格式,将精度降低到 FP16(大小变为只有24 MB) ,发现其性能与 FP32模型相比变化不大。 除此之外,在进行图像检索时,仍然使用 CLIP 中的原始语言模型。 蒸馏后的CLIP模型可以在iPhone上运行。 但目前代码仍未公开,作者表示未来将在GitHub上开源代码。参考资料:https://www.reddit.com/r/MachineLearning/comments/p1o2bd/research_we_distilled_clip_model_vit_only_from/?utm_source=amp&utm_medium=&utm_content=post_body—版权声明—仅用于学术分享,版权属于原作者。若有侵权,请联系微信号:yiyang-sy 删除或修改!—THE END— 浏览 47点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 OpenAI也有24MB的模型了!人人都用的起CLIP模型,iPhone上也能运行新智元0卧槽!VSCode 上竟然也能背单词了???前端桃园0牛!在iPhone上成功运行Ubuntu Linux良许Linux0卧槽!VSCode 上竟然也能约会,谈对象了???JAVA公众号0卧槽!VSCode 上竟然也能约会,谈对象了???FightingCoder0卧槽!VSCode 上竟然也能约会,谈对象了???玩转GitHub0卧槽!VSCode 上竟然也能约会,谈对象了???菜鸟学Python0微信超级更新!电脑上也能刷朋友圈了!编程技术宇宙0iPhone又爆炸了?!爱泡研究所0chromeos-apkChrome 上运行 APKchromeos-apk可以让你的Android的APK文件在ChromeOS和Chrome下运行。点赞 评论 收藏 分享 手机扫一扫分享分享 举报










 下载APP
下载APP