
60亿击败1750亿、验证胜过微调:OpenAI发现GPT-3解决数学题,并非参数越大越好
视学算法报道
编辑:杜伟、陈
现在,OpenAI 的模型也具备解决小学数学应用题的能力了。
比如问题:安东尼有 50 支铅笔。他把 1/2 的铅笔给了布兰登,剩下的 3/5 铅笔给了查理。他保留了剩下的铅笔。问安东尼保留了多少支铅笔?
论文地址:https://arxiv.org/pdf/2110.14168.pdf
数据集地址:https://github.com/openai/grade-school-math
Tim 种了 5 棵树。他每年从每棵树上收集 6 个柠檬。他十年能得到多少柠檬?





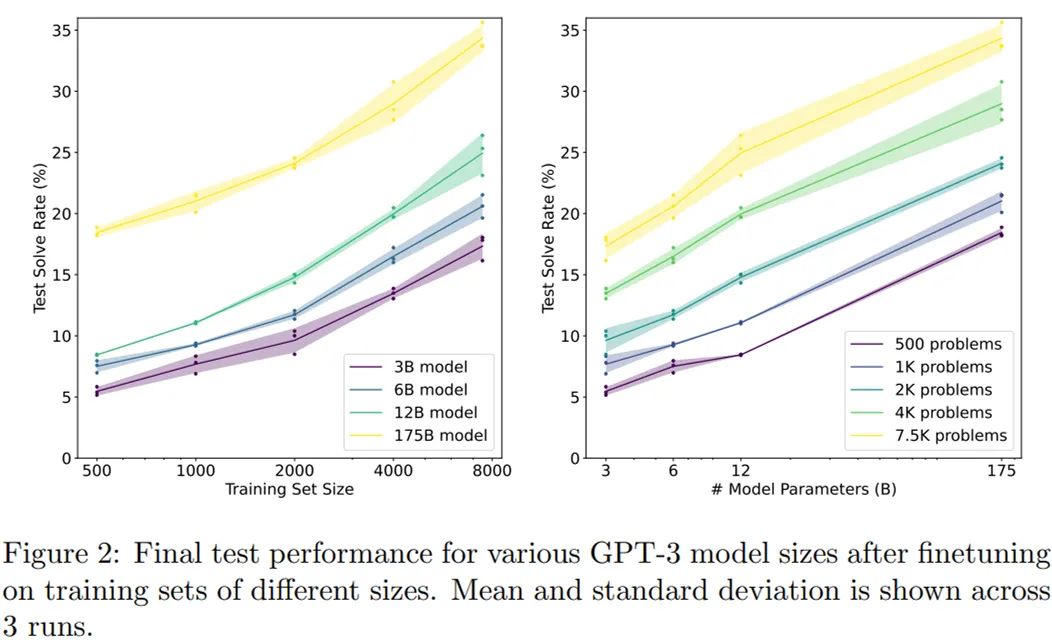
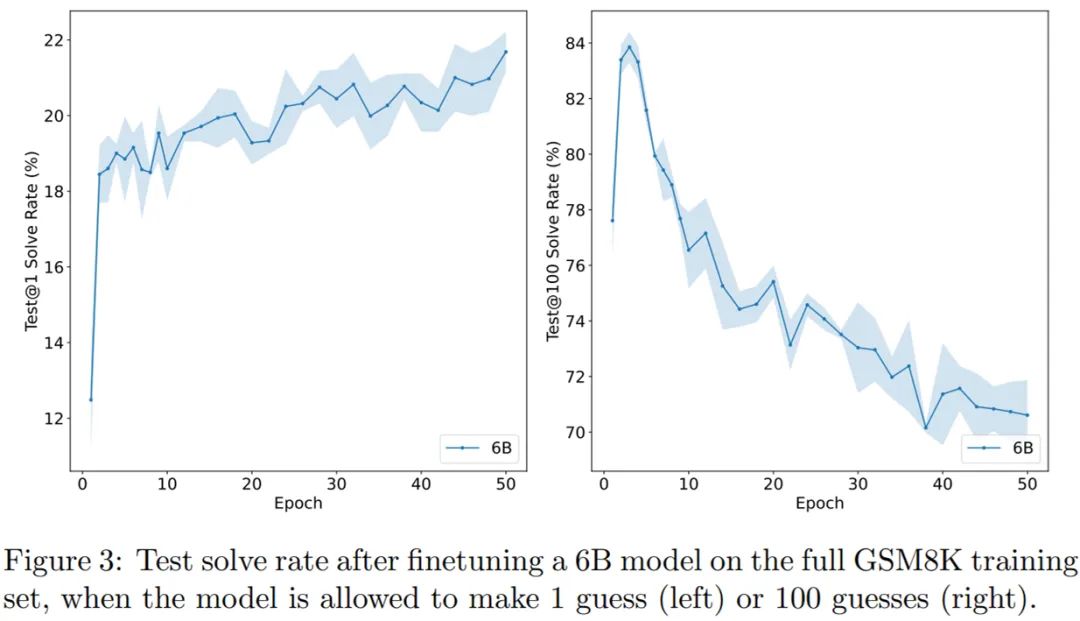
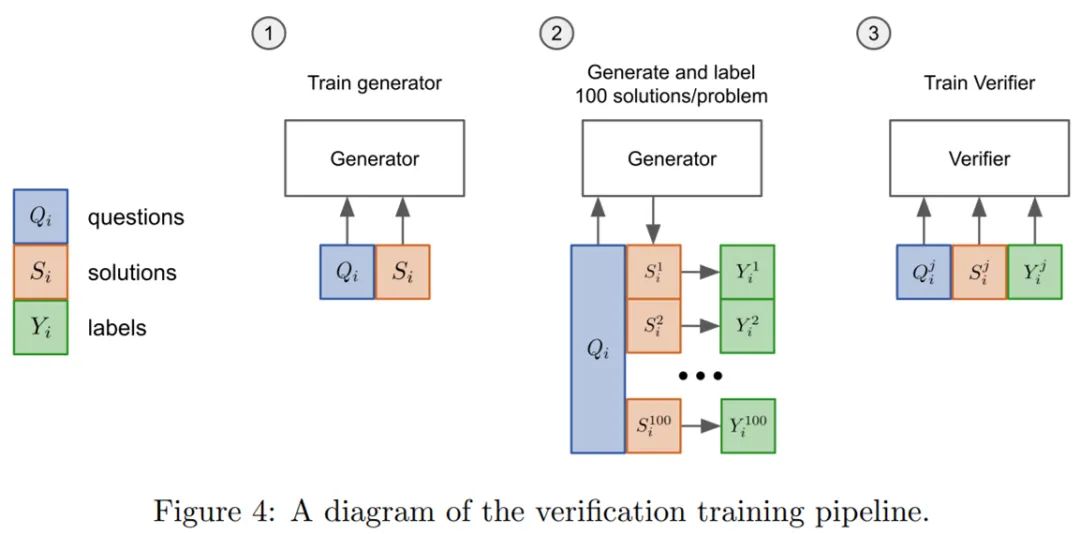
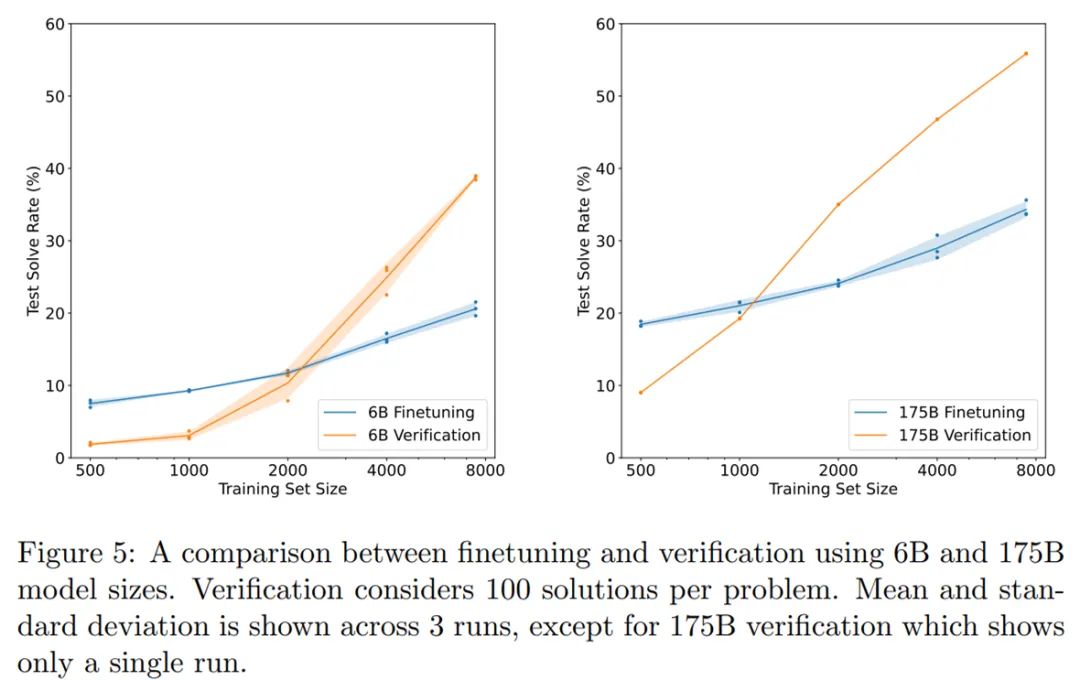
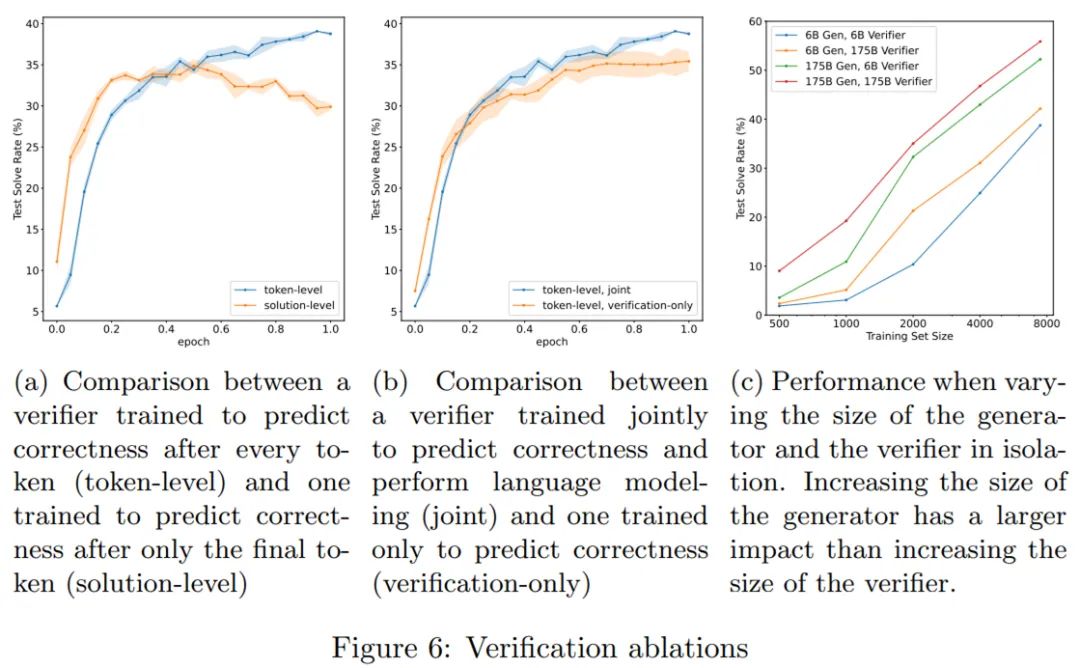
在训练集上对模型(生成器)进行 2 个 epoch 的微调;
从生成器中为每个训练问题抽取 100 个完成样本,并将每个解决方案标记为正确或不正确;
在数据集上训练一个单一 epoch 的验证器。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论