
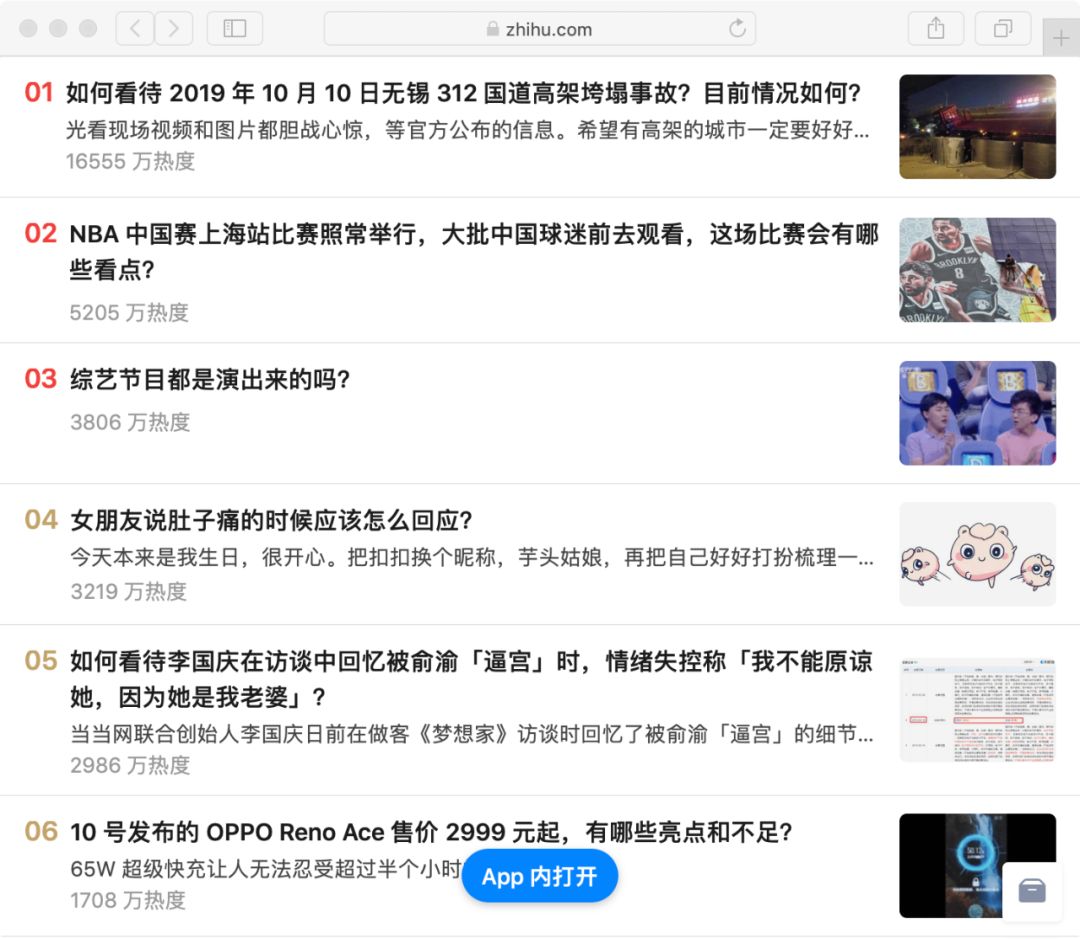
知乎热榜?微博热门?爬!
一直也没写过爬虫的代码,一来是接触练习的少,二来也对爬虫心存偏见:老有种做贼偷数据的感觉。
最近在体验过爬虫的高效便捷后,觉得确实有必要多实践一下。其实我本身学爬虫没多久,远没到分享爬虫技术的水平。但公众号平台嘛,又不是课堂,分享点实战经验和思路,相互交流下心得,也是挺不错的。
今天来分享下这两天写的入门级的爬取知乎热榜和微博热门数据的代码和思路。首先明确下爬虫、知乎热榜和微博热门这些概念。
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
——百度百科,“网络爬虫”
知乎热榜中的内容热度值,是根据该条内容近24小时内的浏览量、互动量、专业加权、创作时间及在榜时间等维度,综合计算得出的。知乎热榜即根据内容热度值制定的排行榜。
知乎热榜链接:https://www.zhihu.com/billboardhttps://www.zhihu.com/hot
微博的热度值是根据该篇微博被转发、点赞数和微博发布时间等各项因素,来算出热度基数,再与热度权重相加,得出最终的热度值。微博热门即话题热度排行榜。
微博热门链接:https://s.weibo.com/top/summary
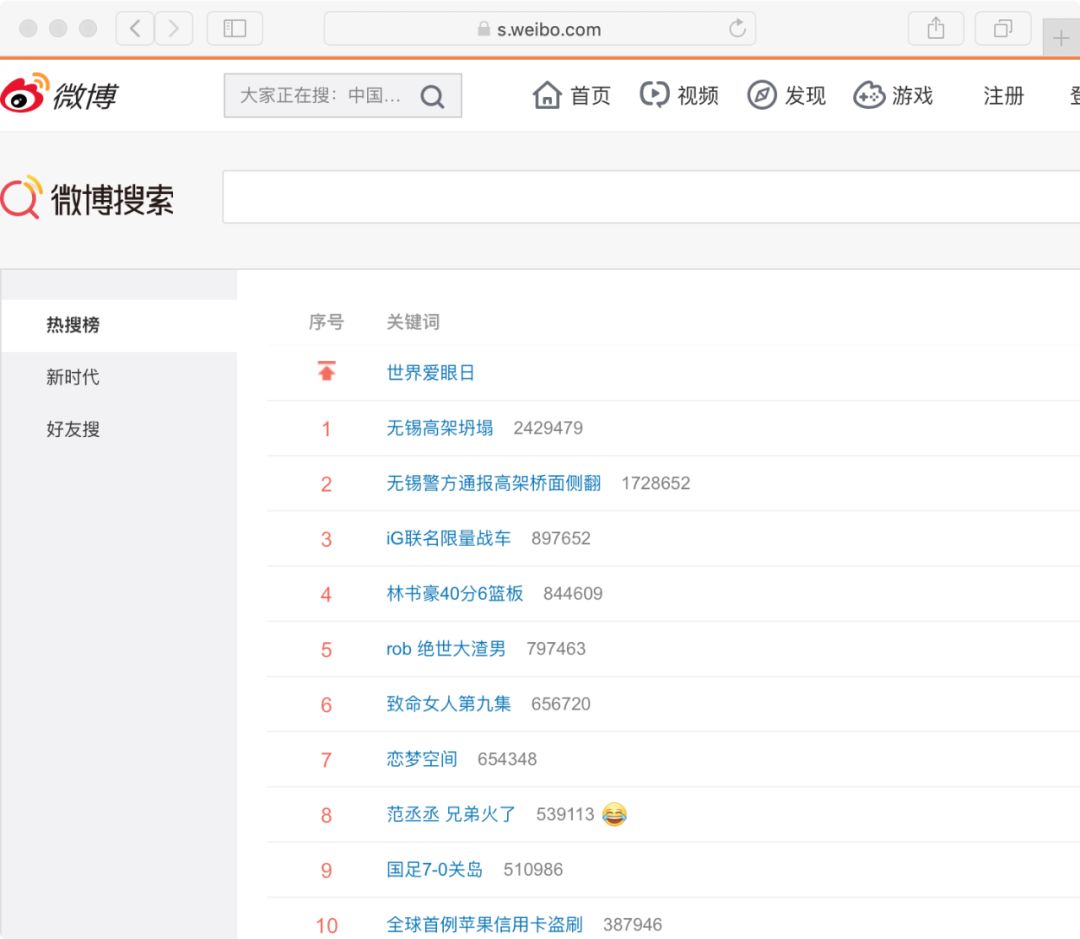
今天我们要做的就是将相关排行榜中的话题内容爬取下来当作数据素材。换句话说,我们要把页面上排好的信息,通过代码读取并保存起来。
1. 爬取网页内容
Python 爬虫通常采用 requests 库来处理网络请求。这里关于 requests 的方法和参数暂不展开。
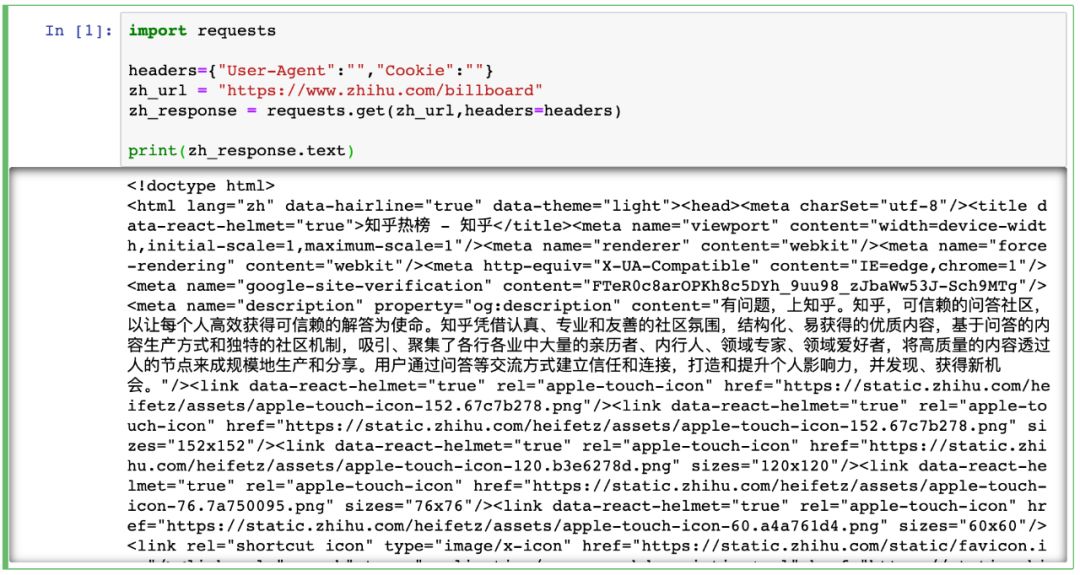
知乎热榜
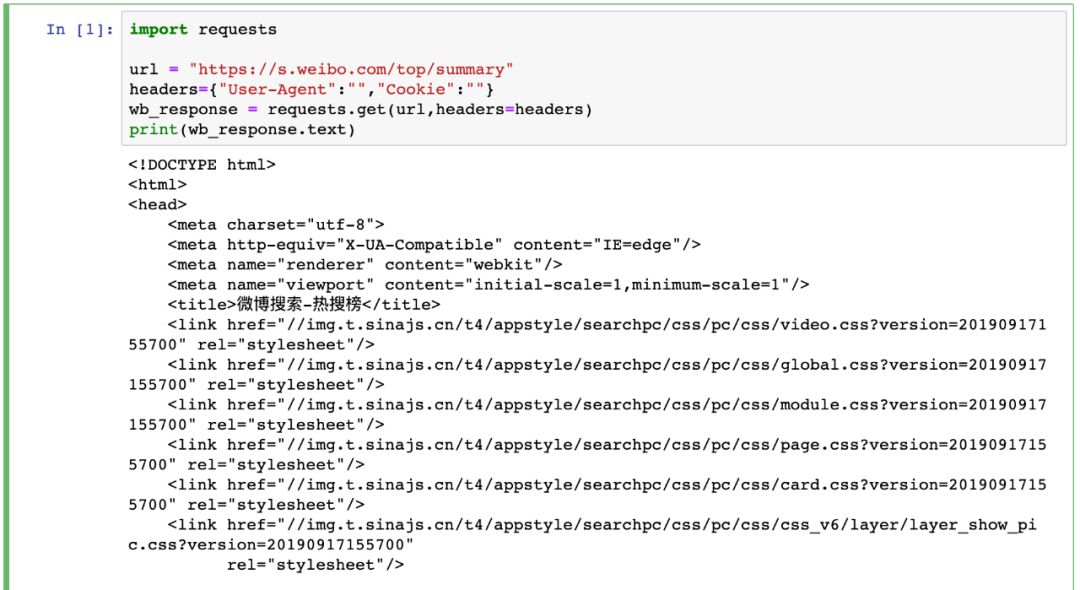
微博热门
这里有两点要注意:
我们选用的网址链接在未登录状态下也可访问,因此 requests 方法中的参数为空也不影响。但爬虫时更多的情况是需要登陆状态,因此也就要求通过设置不同参数来模拟登陆去进行相关操作。
通过 requests 模块获取的网页内容,对应的是在网站上右键单击,选择“显示网页源代码”后展现的页面。它与我们实际看到的网页内容或者 F12 进入开发者模式中看到的网页 elements 是不同的。前者是网络请求后返回结果,后者是浏览器对页面渲染后结果。
2. 解析爬到的内容
第一步爬到的是整个页面内容,接下来要在所有内容中去对目标定位,然后将其读取并保存起来。
这里我采用的是 BeautifulSoup,因为学爬虫最先接触这个,用起来也蛮顺手。通过 BeautifulSoup 提供的方法和参数,可以很便捷定位到目标。
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
Beautiful Soup 4.4.0 文档;https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
之前讲到爬虫所获取的网页对应的是网页源代码,那么在定位网页中目标时可以结合网页源代码来制定解析策略。
这里提一点特别的,在知乎热榜的网页源代码中,拉到最下方可以看到如下:
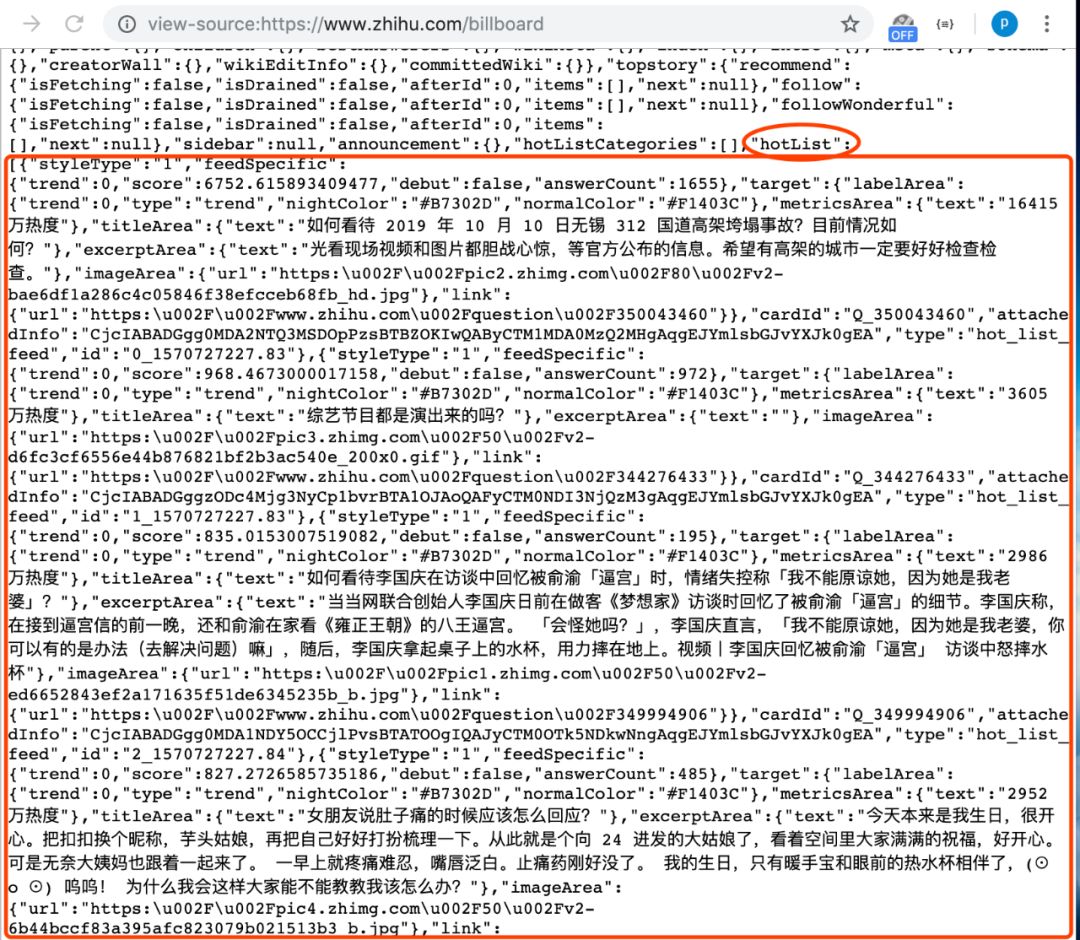
在源代码中网页的 script 部分,有现成的整理好的热榜数据。所以我们为了减少工作量,直接通过 BeautifulSoup 取出 script 中内容,再用正则表达式匹配热榜数据列表处的内容。
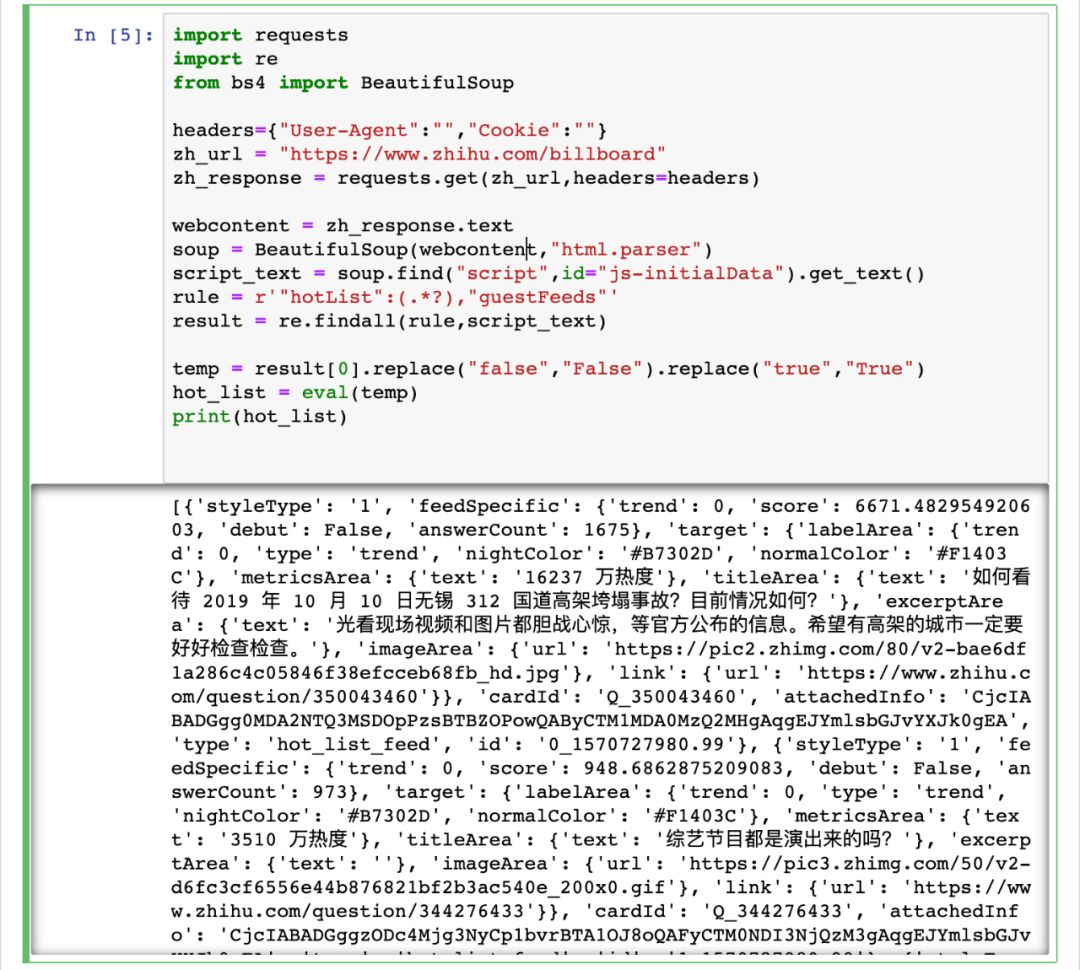
import requestsimport refrom bs4 import BeautifulSoupheaders={"User-Agent":"","Cookie":""}zh_url = "https://www.zhihu.com/billboard"zh_response = requests.get(zh_url,headers=headers)webcontent = zh_response.textsoup = BeautifulSoup(webcontent,"html.parser")script_text = soup.find("script",id="js-initialData").get_text()rule = r'"hotList":(.*?),"guestFeeds"'result = re.findall(rule,script_text)temp = result[0].replace("false","False").replace("true","True")hot_list = eval(temp)print(hot_list)
这里我利用了 script 中热榜数据的列表结构,在定位取出相关字符串后,先将 js 中的 true 和 false 转化为 Python 中的 True 和 False,最后直接通过 eval() 来将字符串转化为直接可用的数据列表。
运行代码结果如图:
至于对微博热门的解析,就是中规中矩地利用 BeautifulSoup 来对网页元素进行定位获取:
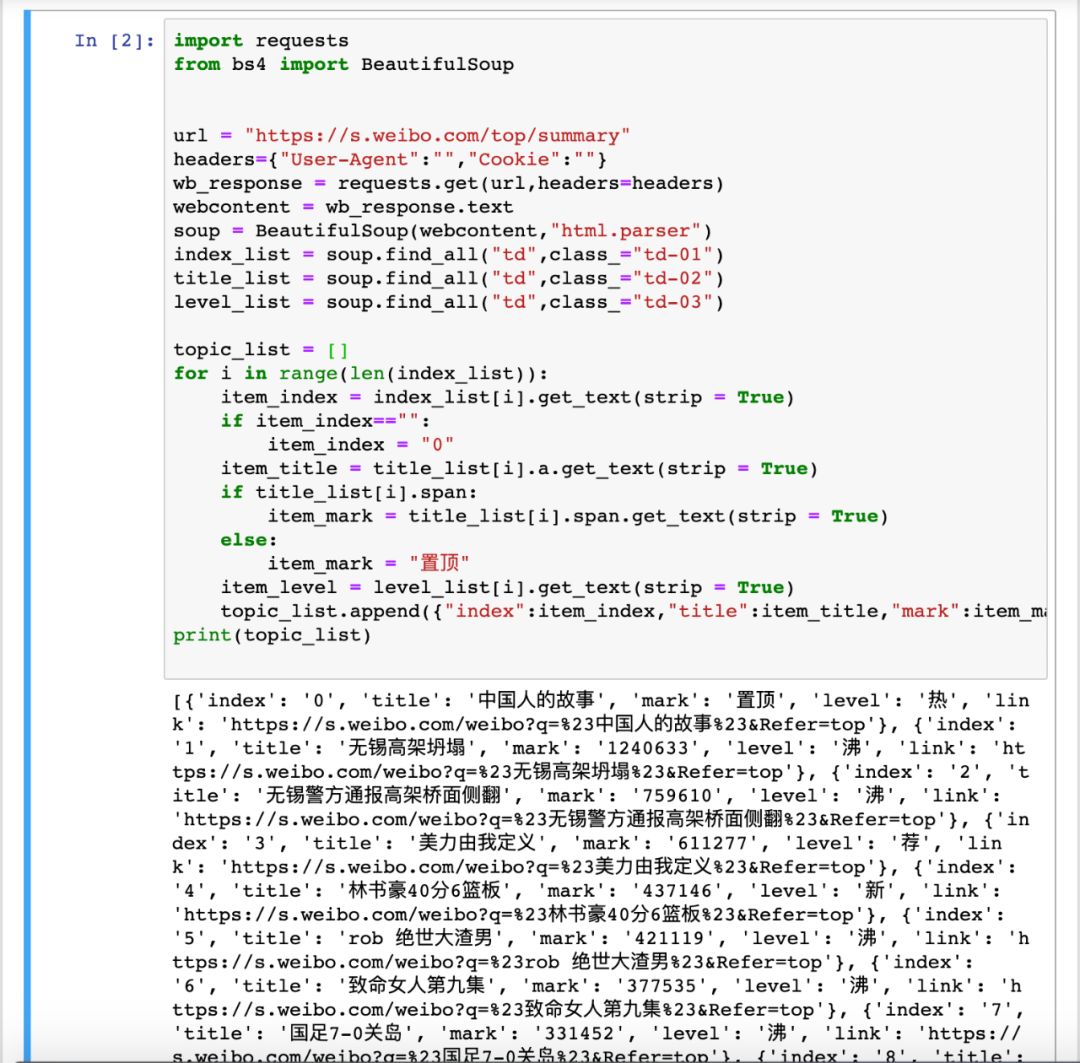
import requestsfrom bs4 import BeautifulSoupurl = "https://s.weibo.com/top/summary"headers={"User-Agent":"","Cookie":""}wb_response = requests.get(url,headers=headers)webcontent = wb_response.textsoup = BeautifulSoup(webcontent,"html.parser")index_list = soup.find_all("td",class_="td-01")title_list = soup.find_all("td",class_="td-02")level_list = soup.find_all("td",class_="td-03")topic_list = []for i in range(len(index_list)):item_index = index_list[i].get_text(strip = True)if item_index=="":item_index = "0"item_title = title_list[i].a.get_text(strip = True)if title_list[i].span:item_mark = title_list[i].span.get_text(strip = True)else:item_mark = "置顶"item_level = level_list[i].get_text(strip = True)topic_list.append({"index":item_index,"title":item_title,"mark":item_mark,"level":item_level,"link":f"https://s.weibo.com/weibo?q=%23{item_title}%23&Refer=top"})print(topic_list)
通过解析,将微博热门数据逐条存入列表中:
后续对拿到的数据加以处理展示,即可得到很多有趣的应用或实现某些功能。例如集成诸多平台排行榜的 “今日热榜”:
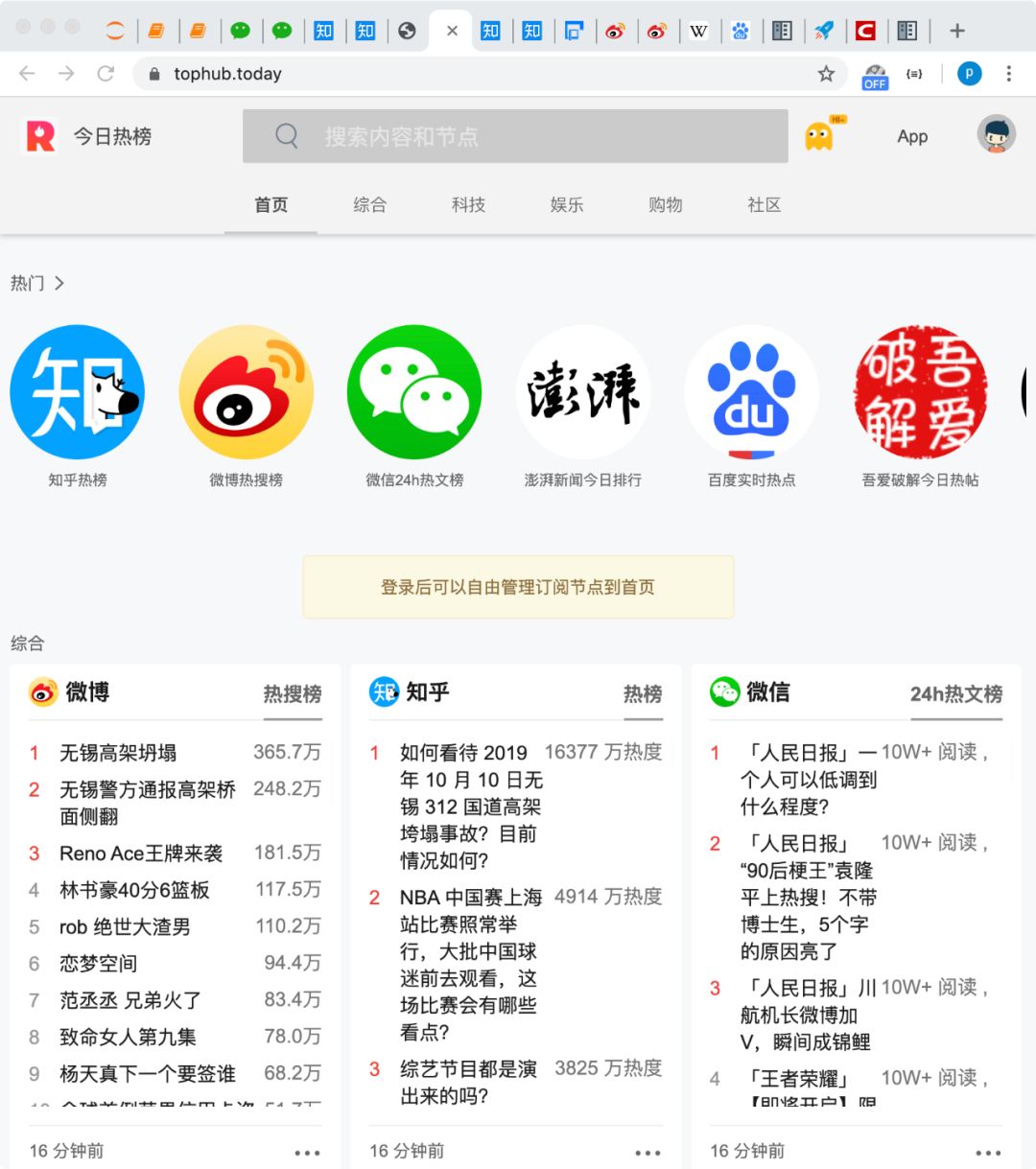
今日热榜链接:https://tophub.today
因为并未展开爬虫细节,今天的总结也比较简单:
首先在选取要爬的网址时要给自己降低难度,例如同样是知乎热榜,zhihu.com/hot 需要登陆,而 zhihu.com/billboard 无需登录便可访问
解析爬取到的内容时,要结合具体页面内容选择最便捷的方式。当需要批量爬取相似页面时,也要尽量整理通用的解析策略。
代码下载移步留言区!
当然,拿到数据只是开始,后续如何去处理才是关键和价值所在,之后我们继续探讨。
以上,感谢阅读!