
用 Jupyter Notebook 爬取微博图片保存本地!

文 | 潮汐
来源:Python 技术「ID: pythonall」

今天咱们用 Jupyter-Notebook 并结合框架(Selenium)模拟浏览器抓取微博图片并将图片保存本地。
Selenium 是一个用电脑模拟人的操作浏览器网页,可以实现自动化测试,模拟浏览器抓取数据等工作。
环境部署
安装 Jupyter notebook
关于 Jupyter notebook 的详细知识点在以往的文章中有做过详细的介绍,详情请参考文章一文吃透 Jupyter notebook
这里只需要在命令行中输入:jupyter notebook 启动跳转到浏览器编辑界面即可。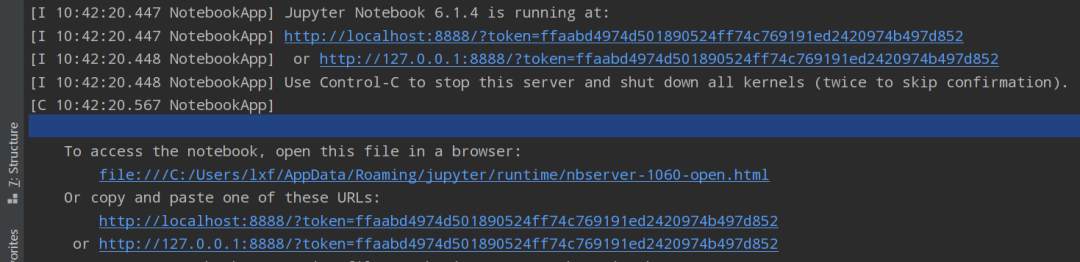
浏览器页面:
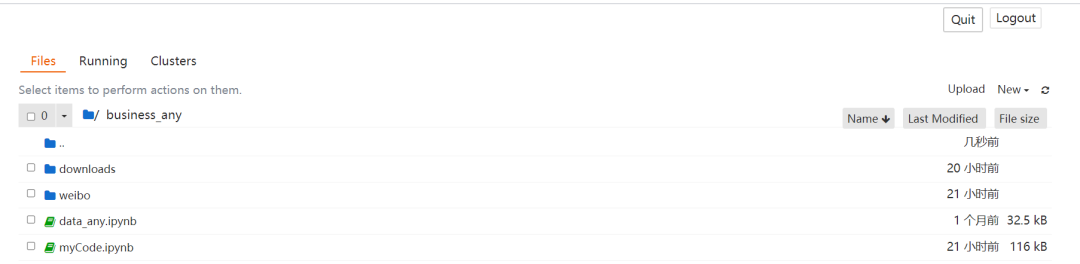
安装 Selenium
安装 Selenium 非常简单,只需要用命令 'pip install Selenium' 即可,安装成功提示信息如下:

下载浏览器驱动
下载驱动地址如下:
Firefox浏览器驱动
Chrome浏览器驱动:chromedriver
IE浏览器驱动:IEDriverServer
Edge浏览器驱动:MicrosoftWebDriver
需要把浏览器驱动放入系统路径中,或者直接告知 selenuim 的驱动路径。
环境都搭建好后就可以直接开始爬取数据了。
抓取微博数据
首先导入包,模拟浏览器访问微博主页,详细代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://weibo.com/')
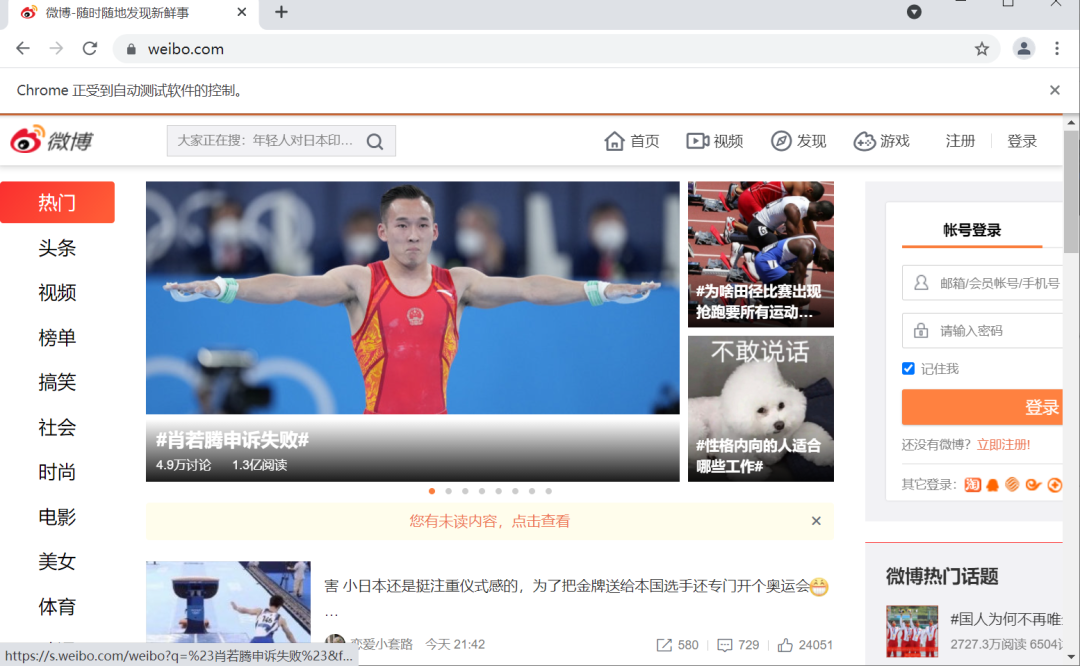
此时浏览器会打开一个新页面,如下图所示:
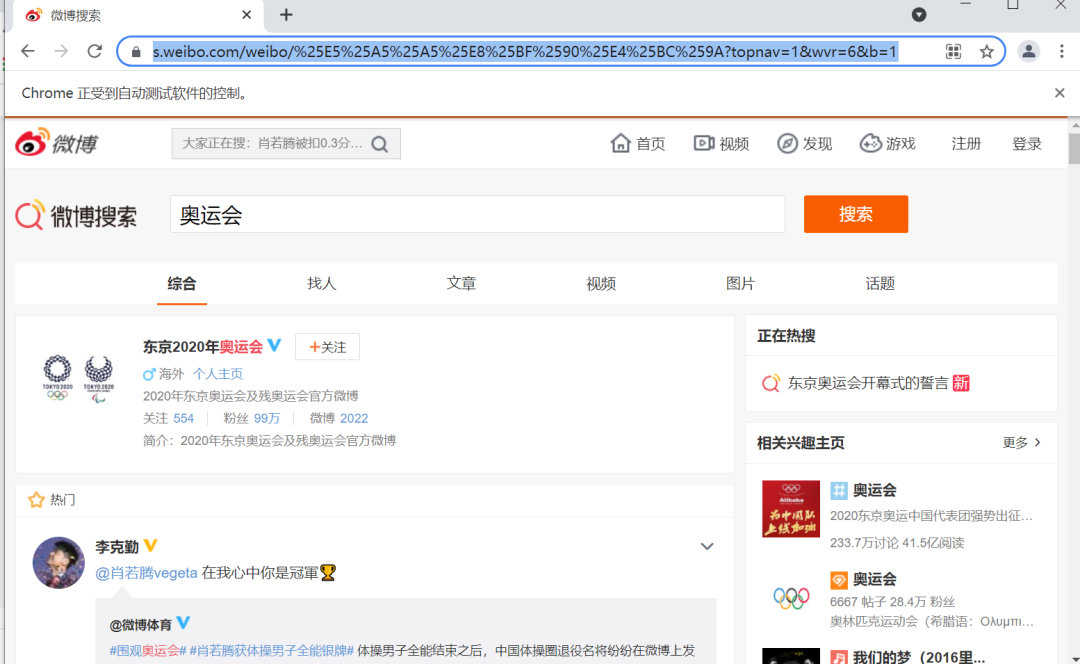
接下来开始分析页面数据:微博页面搜索奥运会关键字后出现新的页面,然后复制网址,抓取和奥运会相关的图片保存于本地,搜索界面如下:
输入网址获取网页内容:
driver.get('https://s.weibo.com/weibo/%25E5%25A5%25A5%25E8%25BF%2590%25E4%25BC%259A?topnav=1&wvr=6&b=1')
contents = driver.find_elements_by_xpath(r'//p[@class="txt"]')
print(len(contents))
输出内容如下:

查看网页详细信息:
for i in range(0,3):
print("==============================")
print(contents[i].get_attribute('innerHTML'))
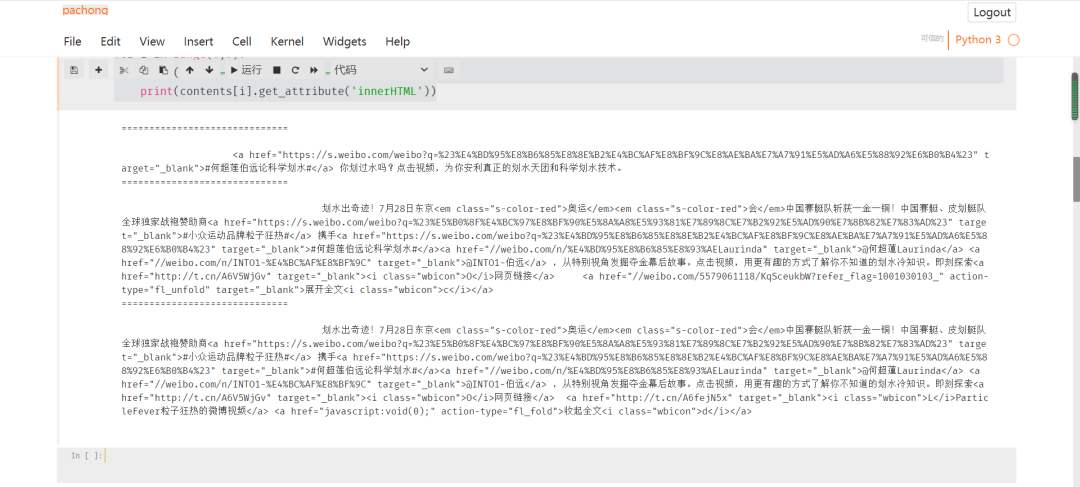
获取图片信息:
contents = driver.find_elements_by_xpath(r'//img[@action-type="fl_pics"]')
print(len(contents))
for i in range(0,20):
print("==============================")
print(contents[i].get_attribute('src'))
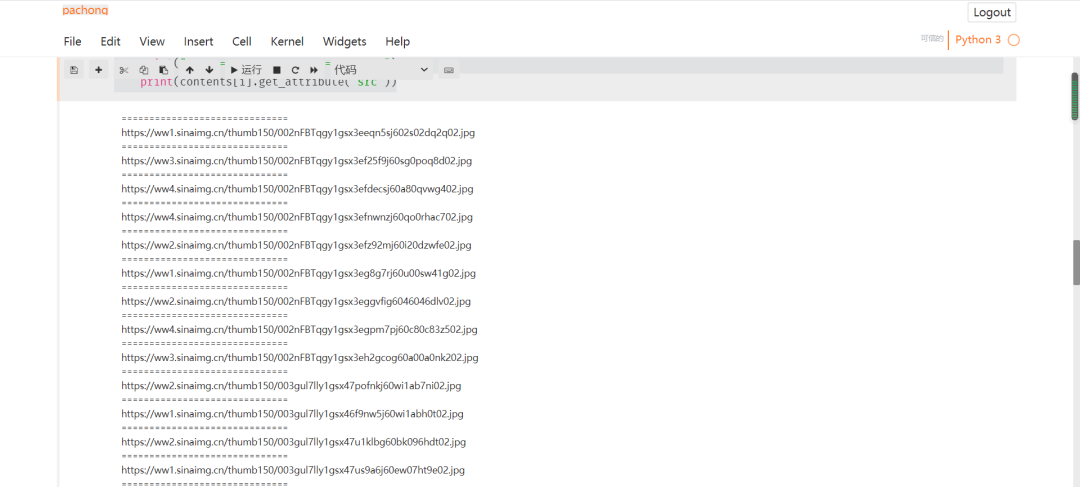
下载图片在本地:
import os
import urllib.request
for i in range(0,20):
print("==============================")
image_url=contents[i].get_attribute('src')
file_name="downloads//p"+str(i)+".jpg"
print(image_url,file_name)
urllib.request.urlretrieve(image_url, filename=file_name)
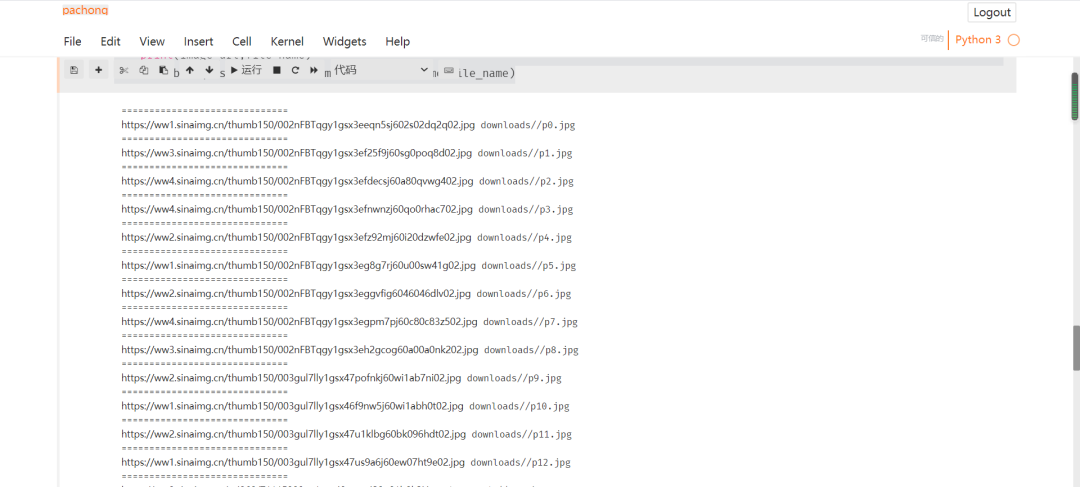
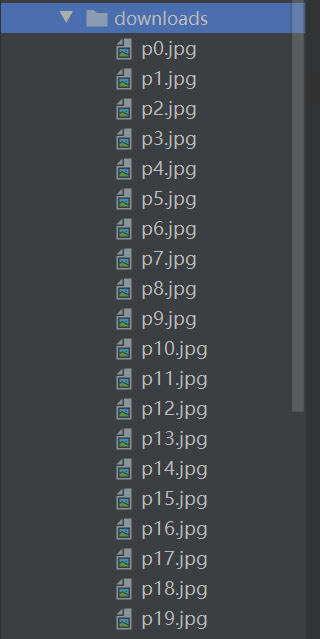
至此微博页面关于奥运会的相关图片已保存于本地,图片保存详情如下:
汇总代码如下
from selenium import webdriver
import urllib.request
driver = webdriver.Chrome()
driver.get('https://weibo.com/')
driver.get('https://s.weibo.com/weibo/%25E5%25A5%25A5%25E8%25BF%2590%25E4%25BC%259A?topnav=1&wvr=6&b=1')
contents = driver.find_elements_by_xpath(r'//p[@class="txt"]')
for i in range(0,3):
print("==============================")
print(contents[i].get_attribute('innerHTML'))
contents = driver.find_elements_by_xpath(r'//img[@action-type="fl_pics"]')
print(len(contents))
for i in range(0,20):
print("==============================")
print(contents[i].get_attribute('src'))
for i in range(0,20):
print("==============================")
image_url=contents[i].get_attribute('src')
file_name="downloads//p"+str(i)+".jpg"
print(image_url,file_name)
urllib.request.urlretrieve(image_url, filename=file_name)
以上汇总代码给没有安装 Jupyter Notebook 的朋友们使用,希望对大家有帮助。
总结
今天的文章主要讲解用 Jupyter Notebook 工具和 Selenium 框架抓取微博数据,希望对大家有所帮助。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】