
2020最新自动驾驶综述,深度解构核心技术

极市导读
本文是一篇关于自动驾驶系统(ADS)的综述,清晰地介绍了自动驾驶技术当前面临的挑战、系统架构、新兴方法及核心功能等多方面内容。资料翔实,值得一读。
本文主要翻译自 A Survey of Autonomous Driving: Common Practices and Emerging Technologies,结合我自己的理解做了一些精简和删改,希望能对大家有一些帮助。这篇文章很新很全,有时间的朋友建议一读。
摘要
本文主要讨论ADS(Autonomous Driving System)的主要问题以及相关技术层面的综述,包括以下几个方面:当前挑战、系统架构、新兴方法、核心功能(定位,建图,感知,规划,人机交互)等。文章最后介绍了相关可供测试开发的开源框架及仿真器。
引言
主要介绍了一些背景,提到了两个著名的自动驾驶研究项目:
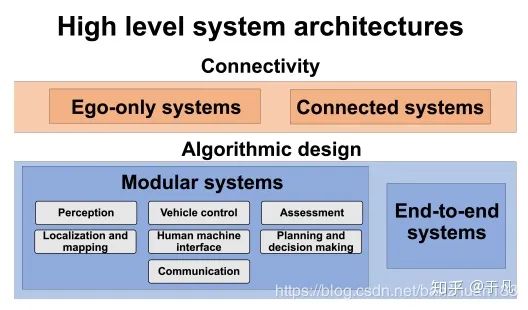
在传统的自动驾驶方案系统架构中,一般将任务划分为多个模块,并在各个模块上使用一系列传感器和算法。但是随着深度学习[3]的发展,逐渐出现了一些端到端的系统。ADS高级系统架构分类如下,主要是按连通性和算法实现逻辑划分,具体介绍在后面。
前景与挑战
前景就不提了,自动驾驶不缺故事。按照美国汽车工程师学会(SAE)的定义,汽车的自动化水平如下:
目前尚无完全实现L4级别及以上的自动驾驶车辆。
系统构成和框架
系统框架
像引言中显示的那样,一般从系统框架上可以分为单车辆系统(Ego-only systems)和互联车辆系统(Connected multi-agent systems);从算法实现上,可以分为两大类,一类是通过将各个部分模块化来实现,另一类是直接通过端到端的实现。

最早的端到端系统可以追溯到ALVINN[5],他训练了一个三层全连接的网络来输出车辆的前进方向。文[74]提出了一种输入图像输出转向的深度卷积神经网络。[75]提出了一种时空网络结构,即FCN-LSTM,可以预测车辆的运动。[4]介绍了另一种卷积模型DeepDriving,可以从输入图像中学习一组离散的感知指标。实际上这种方法并不是严格端到端的,因为如何从一系列感知指标中得到正确的驾驶动作还需要另外的模块。上述的方法都是有监督的训练,也就是说需要一个专家的行为序列。那么就引入了另一个问题,自动驾驶系统是否应该像人一样开车?基于上面那个问题,出现了一种新的深度强化学习模型Deep Q Networks(DQN),将强化学习与深度学习相结合。强化学习的目标是选择一组能最大化奖励的行动,深度卷积神经网络在这里的作用是用来逼近最优奖励函数。简单来说,基于DQN的系统不再是去模仿专家的行为,而是去学习一种“最佳”的驾驶方式[7] 最后一种神经进化是指利用进化算法来训练人工神经网络,但就实际而言,经进化的端到端驾驶不像DQN和直接监督学习那样受欢迎。神经网络的出发点是去除了反向传播,从逻辑上来说,更接近生物的神经网络。在[63]中,作者使用驾驶模拟器对RNN进行神经进化训练。上述三种端到端自动驾驶的方法相比,直接监督学习的方法可以利用标记数据离线训练,而DQN和神经进化都需要在线交互。从理论上讲,端到端自动驾驶是可行的,但是还没有在真实的城市场景中实现(demo不算),最大的缺点是缺乏可解释性和硬编码安全措施(Hard coded safety measures)。- 互联系统(Connected systems):有一些研究人员认为,靠在单车辆系统上叠传感器是局限的,自动驾驶的未来应该是侧重在多车辆之间的信息共享。随着车辆自组织网络(VANETs)的使用,无论是行人信息,传感器信息,亦或者是交通信号等,利用V2X(Vehicle to everything),车辆可以轻松访问其他车辆的数据,来消除单车的感知范围,盲点,算力的限制。车辆自组织网络可以通过两种不同的方式实现:传统的基于IP的网络和以信息为中心的网络( Information-Centric networking,ICN)[8]。由于车辆的高度流动性和在道路网络上的分散性,因此传统的基于IP主机的网络协议不是很适用,事实上,信息源的身份有时候不是那么重要的一件事,ICN显然是更合理的方式。在这种情况下,车辆将查询信息汇聚到某个区域而不是某个地址,同时,它们开源接收来自任何发送方的响应。上面我们提到可以利用车辆间的共享信息来完成一些驾驶任务,但是这里还有一个待解决的问题。想象一下一个城市有几十万辆车,每辆车可能有若干个摄像头,雷达,各种各样的传感器,每时每刻产生的数据量是十分庞大的,更关键的是,大多数情况下,这些数据是雷同的,即使不考虑传输和计算的负担,对算力来说也是极大的浪费。为了减少待处理的数据规模,[9]引入了一个符号学框架,该框架集成了不同的信息源,并将原始传感器数据转换为有意义的描述。除此之外,车辆云计算(Vehicular Cloud Computing,VCC)[10]与传统的云计算不同,它将传感器信息保存在车辆上,只有当本地其他车辆查询时才会被共享,节省了将恒定的传感器数据流上载/下载到web的成本。
传感器和硬件
为了保证系统的鲁棒性和可靠性,大多数任务都需要较高的传感器冗余度,因此ADS一般都采用多种车载传感器。硬件模块大致可以分为五类,外部感知传感器(Exteroceptive sensors),监测车辆自身状态的本体感知传感器(Proprioceptive sensors),通信单元,执行器和计算单元。常见的外部传感器比较如下表:

单目相机(Monocular Cameras):最常见最廉价的传感器之一,除此之外,二维的计算机视觉算是一个比较成熟的研究领域,虽然理论上无法获得深度,但是现在也有一些基于单目深度的结果,缺点主要还是在精度和容易受环境因素影响上。现在还有一些针对特殊场景而开发的相机,如全景相机(Omnidirection Camera),闪光相机(Flash Camera),热敏相机(Thermal Cameras),事件相机(Event Camera)[11]等。所谓的全景相机就是理论上拥有360度视角的相机,事实上,这一类相机的难点并不在捕捉图像而是在图像拼接上,因为球面图像是高度失真的,所以校准的难度很大。而事件相机是一种比较新颖的概念,传统相机是按时间采用,而事件相机是事件触发型,它对场景中移动造成的变换比较敏感,因此可以用在检测动态目标上。事件相机的简单示例如下图所示:

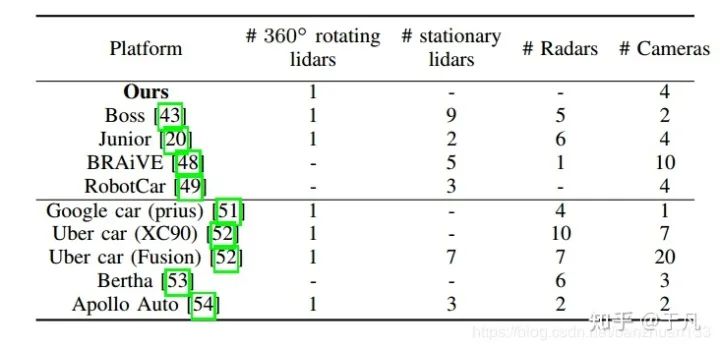
雷达(Radar)和激光雷达(Lidar):一般来说,现在都是采用多传感器的形式,用雷达或者激光雷达来弥补相机(包括深度相机)在深度信息上的缺陷。激光雷达和雷达的工作原理其实差不多,只不过激光雷达发射的是红外线而不是无线电波,在200米以内的精度是很高的,但是相对雷达来说,更容易受到天气的影响。雷达的精度虽然不如激光雷达高,但是由于测距长,成本低,对天气鲁棒性强,目前已经广泛应用于辅助驾驶(ADAS)中,比如接近警告和自适应巡航。(原文中没有提到这两种雷达的干扰问题,实际上金属对电磁波的干扰,生物对红外的干扰,相同频段的(激光)雷达互相干扰是十分关键的问题)。- 本体传感器:一般指车辆自身携带的传感器,如里程计,IMU,转速计等。一些研究机构及公司的整车配置如下表所示:
定位与建图
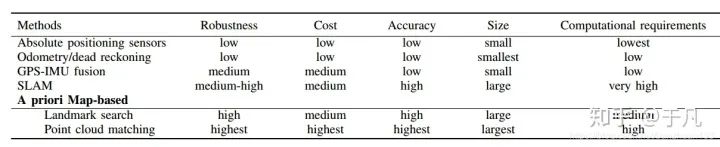
定位指的是在环境中找到相对于参考系的位置,对于任何移动机器人来说这个任务都是最基本的。下文会详细接到三种最常见的方法:GPS-IMU融合,SLAM,基于先验地图定位。几种定位方法的比较如下表所示
GPS-IMU融合
GPS-IMU融合的主要原理是用绝对位置数据修正航位推算(dead reckoning)的累积误差[12]。在GPS-IMU系统中,IMU测量机器人位置和方向的变化,并对这些信息进行处理,以便用航位推算法对机器人进行定位。但是IMU有一个显著的缺点,就是我们常说的累积误差。因此引入GPS的绝对位置信息(相当于一个反馈),可以有效地对IMU误差进行校正。
GPS-IMU融合的方法的精度比较低,实际上并不能直接用在车辆定位上。在2004年的DARPA挑战赛中,卡内基梅隆大学(Carnegie Mellon University)的红队就因为GPS错误而未能通过比赛。除此之外,在密集的城市环境中,像隧道,高层建筑等都会影响GPS的精度。尽管GPS-IMU系统本身无法满足自动驾驶的性能要求,但是可以和激光雷达等传感器相结合进行位姿估计。
SLAM
顾名思义,SLAM是一种在线地图绘制同时定位的行为(理论上的同时)。理论上SLAM不需要关于环境的先验信息,就目前而言,更多是应用在室内环境(室外更多还是基于预先构建的地图进行定位)。关于自动驾驶领域的SLAM可以参见[13]。
基于先验地图定位
基于先验地图的定位技术的核心思想是匹配:定位是通过比较在线数据同先验地图的信息来找到最佳匹配位置[14]。也就是根据先验的地图信息来确定当前的位姿。这个方法有一个缺陷,一般需要额外的一个地图制作步骤,而且,环境的变化可能会对结果产生负面影响(比如光照变化,参照物移动等)。这类方法大致可以分为两大类:基于路标的定位和基于点云的匹配。- 基于路标:与点云匹配相比,基于路标的定位计算成本要低得多。理论上来说,只要路标的数量足够多,这种定位就是鲁棒的。[15]中采用了激光雷达和蒙特卡罗结合的方法,通过匹配路标和路缘(road markers and curbs)来定位车辆的位置。[16]介绍了一种基于视觉的道路标记(road marking)检测方法,事先保存了一份低容量的全局数字标记地图(a low-volume digital marker map with global coordinates),然后与前置相机的采集数据进行比较。最后根据检测结果和GPS-IMU输出利用粒子滤波器进行位置和方向的更新。该方法的主要缺点在于地标的依赖性。
基于点云:点云匹配一般是指局部的在线扫描点云通过平移和旋转同先验的全局点云进行匹配,根据最佳匹配的位置来推测机器人相对地图的局部位置。对于初始位姿的估计,一般是结合GPS利用航位推算。下图展示了利用Autoware进行的地图制作结果:

文献[17]中使用了一种带有概率图的多模态方法,在城市环境中实现了均方误差小于10cm的定位。与一般逐点进行点云匹配并舍弃不匹配部分相比,该方法中所有观测数据的方差都会被建模并应用于匹配任务。后续几种常见的匹配方法包括基于高斯混合模型(Gaussian Mixture Maps ,GMM)),迭代最近点匹配(Iterative Closest Point ,ICP),正态分布变换(Normal Distribution Transform ,NDT)等。关于ICP和NDT,[18]进行了详细的比较(我之前也写过一篇博客)。ICP和NDT算法都有相应的一些改进和变式,比如[19]提出了一种基于NDT的蒙特卡罗定位方法,该方法利用同时利用了离线的静态地图和不断进行更新的短期地图,当静态地图失效时,基于NDT的栅格来更新短期地图。
基于先验地图方法最大的缺陷就在于先验地图的获取上,实际上制作和维护一个可靠的高精度地图是相当费时又费力的一件事。除此之外,还有一些其他情况,比如跨维度的匹配(二维到三维,三维到二维等)。[20]就提到一种利用单目相机在点云中进行定位的方法。在初始姿态估计的基础上,利用离线的三维点云地图生成二维图像,并同相机捕捉到的图像进行在线归一化比较。这种方法相当于简化了感知的工作,但是增大了计算的复杂度。
感知
感知周围环境并提取可供安全导航的信息是自动驾驶的核心之一。而且随着近年来计算机视觉研究的发展,相机包括三维视觉逐渐成为感知中最常用的传感器。本节主要讨论基于图像的目标检测,语义分割,三维目标检测,道路和车道线检测,目标跟踪等。
检测
基于图像的目标检测
一般目标检测指的是识别感兴趣目标的位置和大小(确定图像中是否存在特定类的对象,然后通过矩形边界框确定其位置和大小),比如交通灯,交通标志,其他车辆,行人,动物等。目标检测是计算机视觉的核心问题,更重要的是,它还是其他许多任务的基础,比如说目标跟踪,语义分割等。
对于物体识别的研究虽然始于50多年前,但是直到最近几年,算法的性能才算真正达到自动驾驶相关的水平。2012年深度卷积神经网络(DCNN) AlexNet[21]一举玩穿了ImageNet挑战赛,开启了深度学习用于目标检测的浪潮。基于图像的目标检测survey也有很多,比如[22]。尽管目前最先进的方法基本都依赖于DCNN,但它们之间也存在明显的区别:
1)单级检测框架(Single stage detection frameworks)使用单个网络同时生成对象检测位置和类别预测。
2)区域生成检测框架(Region proposal detection frameworks)有两个不同的阶段,首先生成感兴趣的一般区域(候选区域),然后通过单独的分类器网络进行分类。
区域生成网络是目前比较先进的检测方法,不足是对计算能力要求高,不容易实现,训练和调整。相应的,单级检测算法具有推理速度快,存储成本低等优点,非常适合实时自动驾驶场景。YOLO[23]是当前十分流行的一种单级检测算法,也有许多改进的版本。YOLO的网络利用DCNN在粗网格上提取图像特征,显著地降低了输入图像的分辨率。之后用一个全连接的神经网络预测每个网格单元的类概率和边界框参数,这种设计使得YOLO速度非常快。另一种广泛使用的方法是单点检测器(Single Shot Detector,SSD)[24],它的速度甚至比YOLO更快。SSD与YOLO都在粗网格上进行检测,但是SSD也使用在DCNN早期得到的高分辨率特征来改进对小目标的检测和定位。
对于自动驾驶任务来说,可靠的检测是至关重要的,但同时也需要平衡精度和计算成本,以便规划和控制模块能有充足的时间来对检测结果做出反应。因此,目前SSD通常是ADS的首选检测算法。当然,区域生成网络(RPN)在目标识别和定位精度方面的性能已经远胜单级检测框架算法,并且近年来随着计算能力的不断提高,也许在不就的将来,RPN或者其他两阶段检测框架就能适用于ADS任务中。
基于图像的目标检测方法的主要不足大多来源于相机的天然缺陷,比如难以处理弱光条件,对于阴影,天气,光照变化的适应性不足等,尤其是监督学习的方法。一方面可以研究一些光照不变特征的方法,另一方面的话,通常来说,采用单传感器很难能适应各种复杂的现实情况,因此采用多传感器融合的策略是大势所趋。比如利用雷达或者红外传感器来处理低光条件下的目标检测等。
语义分割
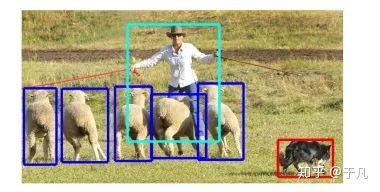
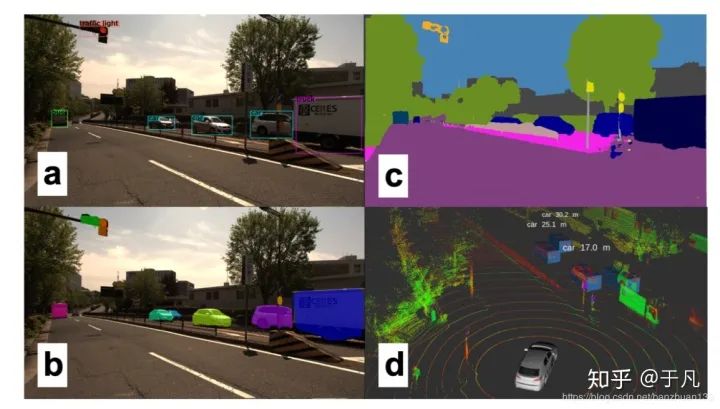
这里简单谈一下我理解的图像分类,目标检测和语义分割的区别。图像分类是给你一堆图,告诉我每张图主要内容的类别,最经典的就是MNIST上的手写数字识别,输出是每张图代表什么数字。目标检测是输入一系列图,把每张图里我感兴趣的目标框出来,比如上面说的用YOLO做行人检测,输出就是用矩形框把每张图里的行人框出来。语义分割的任务是把图像里的每一个像素都归到某个类别里,有点像机器学习中聚类的概念。下面两张图左边是目标检测,右边是语义分割。

为什么自动驾驶需要研究语义分割呢?因为仅仅简单用矩形框把目标框出来的效果可能很差,尤其是在道路,交通线上。甚至我们应该更进一步进行实例分割(Instance segmentation),来区分不同轨迹和行为的对象。得益于目标检测的发展,分割方法逐渐在实时应用中变得可行。Mask R-CNN[25]是Faster R-CNN[26]的推广,多任务网络可以同时实现精确的边界框估计和实例分割,该方法可以用来进行行人姿态估计等任务。Mask R-CNN的速度可以达到每秒5帧,速度接近了实时ADS的要求。
与使用CNN使用区域生成网络进行目标检测不同,分割网络通常采用卷积的组合进行特征提取,然后利用反卷积(去卷积,deconvolutions)来获得像素级标签[27]。此外,特征金字塔网络(Feature pyramid networks)也被广泛使用,比如在PSPNet[28]中,它还引入了扩散卷积(dilated convolutions)进行分割。DeepLab[29]是目前最先进的对象分割模型,主要用到了稀疏卷积(sparse convolutions)的思想。在ADS中使用DeepLab进行分割的效果如下:
尽管大多数分割网络仍然太慢且计算量巨大,无法在ADS中使用,但需要注意的是,许多分割网络最初都是针对不同的任务(如边界框估计)训练的,然后在推广到分割网络。而且之后证明这些网络可以学习图像的通用特征表示并推广到其他任务当中。这也许提供了另一种可能性,利用单一的广义感知网络可以解决ADS的所有不同感知任务。
三维目标检测
鉴于经济性,可用性和研究的广泛性,几乎所有的算法都使用相机作为主要的感知方式。把相机应用在ADS中,限制条件除了前面讨论到的光照等因素外,还有一个问题就是目标检测是在图像空间的,忽略了场景的尺度信息。而当需要进行避障等动态驾驶任务时,我们需要将二维图像映射到三维空间来获得三维的信息。实际上利用单个相机来估计深度也是可行的[30],当然利用立体相机或者多相机的系统更具鲁棒性。从二维到三维的映射必然需要解决一个图像匹配问题,这给已经够复杂的感知过程又增加了大量的计算处理成本。
所以我们换一种思路,是否可以直接在三维进行目标检测。我们知道3D雷达收集的数据是三维的,从本质上已经解决了尺度问题,而且3D雷达不依赖于光照条件,不容易受到恶劣天气的影响。3D雷达收集的是场景表面的稀疏3D点,这些点很难用于对象检测和分类,分割反而相对容易。传统方法使用基于欧式距离的聚类(Euclidean clustering)或者区域生长(region-growing)算法[31]来将点划分为不同对象。结合一些滤波技术,比如地面滤波(ground filtering)[32]或者基于地图(map-based filtering)的滤波[33],可以使该方法更具鲁棒性。下图我们展示了一个从原始点云输入中获取聚类对象的例子

与基于图像的方法发展趋势一样,机器学习最近也取代了传统3D检测方法,而且这种方法还特别适用于RGB-D数据。RGB-D产生的数据与点云类似,不过包含颜色信息,由于范围比较有限而且可靠性不高,尚未应用于ADS系统。[34]利用3D占据栅格(occupancy grid)表示的方法完成了RGB-D数据的对象检测。此后不久,类似的方法被应用于激光雷达创建的点云。受基于图像的方法的启发,尽管计算开销很大,但仍然使用了3D CNN。VoxelNet[35]首次给出了令人信服的点云上三维边界框估计的结果。SECOND[36]利用激光雷达数据的自然稀疏性,改进了这些工作的准确性和计算效率。最近提出的几种算法比较如下表所示
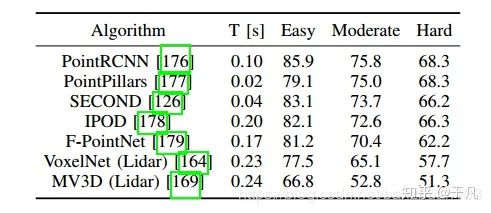
数据集是KITTI[42],结果以中等类别精度排序,算法中只使用点云数据。
基于激光雷达的感知的另一个选择是点云数据的二维投影。点云数据在2D中有两种主要表示形式,一种是深度图,主要是受通过深度估计执行3D对象检测[37]和在RGB-D数据上进行操作方法的启发。VeloFCN网络[38]提出使用单通道深度图像作为浅层单级卷积神经网络的输入,生成3D车辆候选,许多其他算法也都采用了这种方法。深度图的另一个用途是用于激光雷达点的语义分类(semantic classification)[39]。另一种2D投影是指对鸟瞰图(bird’s eye view,BV)的投影,该方式越来越受欢迎。不过鸟瞰图仅有单纯的2D离散信息,因此如果激光雷达点的值仅有高度变化的话,在2D中必定会互相遮挡。MV3D算法[40]使用相机图像,深度图像以及多通道BV图像(这里不同通道对应不同的高度),来最小化这种遮挡。一些工作重复使用基于相机的算法,并训练了有效的网络来在2D BV图像上进行3D对象检测[41]。这些算法都是在KITTI数据集和nuScenes[43]数据集上进行测试的。2D的方法计算成本要比3D小得多,而且利用稀疏性改进这些工作的准确性和效率之后[36],这些方法可以迅速接近ADS系统所需的精度。
目标跟踪
对于复杂和高速情况下的自动驾驶,仅仅估计位置是不够的,为了避免碰撞,还需要估计动态目标的航向和速度,以便应用运动模型跟踪目标并预测目标未来的运动轨迹。同样的,一般都通过多个相机,激光雷达或者雷达来获取传感器信息,且未来更好地应对不同传感器的局限性和不确定性,通常采用传感器融合的策略进行跟踪。
常用目标跟踪算法依赖于简单的数据关联技术和传统的过滤方法。当在三维空间中以高帧速率跟踪对象时,最近邻方法通常足以建立对象之间的关联。基于图像的方法一般需要建立一些外观模型,例如使用颜色直方图,梯度或者其他特征(如KLT)等来评估相似度[44]。基于点云的方法也使用一些相似性度量,例如点密度,Hausdorff距离[45]。由于总是可能出现关联错误的情况,因此经常使用多假设跟踪(multiplehypothesis tracking)算法[46],这确保了跟踪算法可以从任一时间内的不良数据关联中回复。一般我们都是在每帧中使用占据地图(occupancy maps),然后在帧之间进行数据关联,尤其是在使用多个传感器时。为了获得平滑的动态特性,采用传统的Bayes滤波器对检测结果进行滤波。对于简单的线性模型,Kalman滤波一般是足够的,而扩展Kalman滤波器(EKF)和无迹Kalman滤波器(UKF)可用于处理非线性动态模型。我们实现了一个基本的基于粒子滤波的目标跟踪算法,利用相机和3D激光雷达来跟踪行人,结果如下(白色的表示轨迹)

为了使跟踪更具鲁棒性,经常会用到被跟踪对象的物理模型。在这种情况下,首先使用诸如粒子滤波器之类的非参数化方法,之后利用一些物理参数(如大小)来进行动态跟踪[47]。更为复杂的滤波方法,如raoblockwelled粒子滤波器,被用于跟踪L型车辆模型的动态变量和车辆几何变量(dynamic variables and vehicle geometry variables)[48]。针对车辆和行人,现在有各种各样的模型,甚至一些模型可以推广到任何动态对象。此外,深度学习也开始被应用于跟踪问题,尤其是对图像领域。[49]通过基于CNN的方法实现了单目图像的实时跟踪。利用多任务网络来估计物体动力学的方法也在涌现[50],这进一步表明了能够处理多种感知任务的广义网络可能是ADS感知的未来。
道路和车道线检测
前面介绍的边界框估计方法对于某些感兴趣的对象十分有用,但对于一些连续曲面(如道路)则不适用。可行驶曲面的确定是ADS的关键,所以把该问题从检测问题中单独出来作为一个子类研究。从理论上讲,利用语义分割可以解决该问题。一个简单的做法是从车辆自身来确定可驾驶区域,将道路分为若干个车道,并确立主车道,该技术被应用在许多ADAS中,如车道偏离警告,车道保持和自适应巡航控制[51]。更有挑战性的任务就是怎么确定其他车道和对应的方向,并在此基础之上理解更复杂的语义,比如转向和合并[52]。上述具体不同的任务对ADS的探测距离和可靠性要求各不相同,但是自动驾驶需要对道路结构有一个完整的语义理解以及长距离探测多条车道的能力。
前面提到的数据预处理(包括图像和点云)的方法,在道路处理中也同样适用,比如归一化照明条件(normalize lighting conditions),滤波,颜色,强度,梯度信息统计等。另外,利用道路的均匀性和边缘的突变(elevation gap at the edge )我们可以使用区域生长方法(regiongrowing)[53]。也有一些基于机器学习的方法,包括将地图与数据融合[54]或者完全基于外观的分割[55]。一旦曲面被估计出来之后,就可以利用一些模型拟合来保证道路和车道的连续性,包括参数化模型(比如直线、曲线)和非参数化模型的几何拟合。[56]提出了一个集成了拓扑元素(如车道分割与合并)的模型,还可以结合车辆动力学和动态信息,利用滤波算法获得更平滑的结果。目前道路和车道线检测已经有许多方法,并且有些已经集成到了ADAS系统中,但是大多数方法仍然依赖于各种假设与限制,能够处理复杂道路拓扑的真正的通用系统尚未开发出来。通过对拓扑结构进行编码来获得标准化的道路图并结合新兴的基于机器学习的道路与车道线分类方法,也许会形成一个鲁棒的可应用于自动驾驶的系统。
评估( ASSESSMENT)
一个鲁棒的ADS系统应该能够不断地评估当前状况的总体风险水平并预测周围驾驶员和行人的意图,缺乏敏锐的评估机制可能会导致事故。本节主要讨论以下三类评估:总体风险和不确定性评估,人类驾驶行为评估和驾驶风格识别。
总体风险和不确定性评估
总体评估可以理解为去量化驾驶场景的不确定性和风险水平,目的是为了提高ADS的安全性。[57]提出了一种利用贝叶斯方法来量化深度神经网络的不确定性。[3]设计了一个贝叶斯深度学习体系结构,并在一个模拟场景中展示了它相对于传统方法的优势。这种方法的总体逻辑是每个模块在系统中的传递与输入都服从概率分布,而不是一个精确的结果。另一种方法就是单独评估驾驶场景下的风险水平,可以理解为前者是从系统内部评估,后者是从系统外部评估。[58]将传感器数据输入到一个风险推理框架中,利用隐马尔科夫模型(Hidden Markov Models ,HMMs)和语言模型检测不安全的车道变更事件。[59]引入了一个深度时空网络来推断驾驶场景的总体风险水平,也可以利用来评估车道变更的风险水平。下图是一个示例,代表两种图像序列下的风险评估结果:

周围驾驶行为评估
实际环境中的自动驾驶决策还有周围驾驶员的意图与行为相关。目前该技术在ADS领域尚不常见。[60]用隐马尔可夫模型(HMM)对目标车辆的未来行为进行了预测,通过学习人类驾驶特征,将预测时间范围延长了56%。这里主要是利用了预定义的移动行为来标记观测值,然后再使用HMM以数据位中心学习每种类型的特征。除此之外,还有一些其他的方法,比如贝叶斯网络分类器,混合高斯模型和隐马尔科夫模型相结合[61],支持向量机等。这一类评估的主要问题在于观测时间短,实时计算量要求高,大多数情况下,ADS只能观测周围车辆几秒钟,因此不能使用需要较长观察周期的复杂模型。
驾驶风格识别
人和机器最大的不同在于人是有情绪的,有些驾驶员比较激进,有些比较稳重。2016年,谷歌的自动驾驶汽车在换道时和迎面而来的巴士相撞,原因就是自动驾驶汽车以为巴士会减速,而巴士司机却加速了。如果能事先知道司机的驾驶风格,并结合进行预测,这场事故也许是可以避免的。当然,驾驶风格目前还没有一个准确的定义,因此分类的依据也有很多种,比如油耗,均速,跟车行为等。一般来说,对驾驶风格的分类大多是将其分为若干类,对应于不同的离散值,但是也有连续型的驾驶风格分类算法,比如[62]将其描述为介于-1到+1之间的值。
同样,也有一些基于机器学习的方法。[63]采用主成分分析法( Principal component analysis, PCA),以无监督的方式检测出5个不同的驾驶类别。[64]使用了基于GMM的驾驶员模型来识别单个驾驶员的行为,主要研究了跟车行为和踏板操作(pedal operation)。[65]使用词袋(Bag-of-words)和K均值聚类来表示个体的驾驶特征。[66]使用了一个自编码网络(autoencoder network)来提取基于道路类型的驾驶特征。类似的还有将驾驶行为编码到3通道RGB空间中,利用一个深度稀疏的自编码器(deep sparse autoencoder)来可视化各个驾驶风格[67]。将驾驶风格识别成功应用到真实的ADS系统的目前还没有相关报道,但是这些研究可能是未来ADS发展的一个方向。
规划与决策
全局规划
全局规划是比较成熟的一个研究领域,几乎所有车都已经配备了导航系统,利用GPS和离线地图能够轻易规划全局路径。全局路径规划可以分为以下四种:目标导向(goal-directed),基于分割( separator-based),分级规划( hierarchical)和有界跳跃(bounded-hop)。目标导向最常见,比如Djikstra和A*,已经广泛应用于各个领域。基于分割的逻辑有点像路由算法,删去一些边或者顶点,计算每个子区域间的最短路径,这种方法可以有效加快计算速度,示例如下
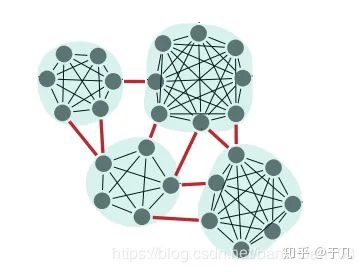
基于分级的技术利用了道路的层次逻辑,比如道路有国道省道乡道等,对于路线的查询,层次结构的重要性应该随着距离的增长而增加。有界跳跃是一种典型的空间换时间做法,很明显,计算一对顶点间的所有可能路径是不切实际的,事先保存若干选定顶点之间的距离和路径并在导航中使用才是一种合理的做法,对于路径规划的查询可以利用标签集线器(hub labeling)[68]来加快查询速度。当然,这些方法并不互斥,互相组合的方法也很常见。[69]将分割法与有界跳跃法相结合,提出了Transit Node Routing with Arc Flags(TNR + AF)算法。
局部规划
局部规划实际可以理解为为了实现全局规划来找到一条足够优化且能避开障碍物的轨迹。同样可以分为四类:基于图搜索(graph-based planners),基于采样( sampling-basedplanners),曲线插值( interpolating curve planners)和数值优化( numerical optimization)方法。当然,后续还有一些基于深度学习的方法。基于图搜索的方法基本和基于图的全局规划差不多,Dijkstra和A*以及其改进算法依然是最常见的方法。基于图搜索常见的做法都是将地图离散成状态格,这种做法在高维的情况下会产生指数爆炸。因此就有了基于采样的方法,最常见的基于采样的方法是概率图(PRM)和快速随机搜索树(RRT)。这类方法的缺陷主要是不稳定,在某些特定环境下可能要很长时间才能收敛。曲线插值是在一系列已知点上拟合一条可行的轨迹曲线,常见的曲线有回旋线,多项式曲线,贝塞尔曲线等,这种方法的避障策略一般是插入新的无碰撞的轨迹,如果偏离了初始轨迹,则避开障碍之后再返回初始轨迹。这种方法生成的轨迹较光滑,计算量也比较大,但是在实际ADS中,轨迹光滑一般意味着对乘客比较友好。数值优化一般可以用来改善已有的轨迹,比如[70]利用非线性数值函数(numeric non-linear functions )来优化A*得到的轨迹,[71]利用牛顿法解决了势场法(Potential Field Method,PFM)的固有震荡问题。我之前写过一篇博客详细介绍了几种主流方法的原理,有兴趣的可以戳这里。
随着人工智能的火热,一些基于深度学习和强化学习方法的规划策略也开始涌现出来。[72]利用三维全卷积神经网络(Fully convolutional 3D neural networks)从激光雷达等输入设备获取点云并生成未来的轨迹。[73]利用深度强化学习在仿真环境下实现了交叉路口的安全路径规划。基于深度学习的缺陷前面已经提到过了,缺乏硬编码的安全措施,除此之外还有泛化能力问题,数据来源问题等,但总的来说,这一类方法应该是未来的趋势之一。
人机交互
车辆一般通过人机模块(HMI)与驾驶员或乘客交互。互动的强度取决于自动化程度,传统的L0的车需要持续的用户操作输入,而理论上L5级别的车仅需要在行程开始的时候给予一个输入即可。根据目的不同大致可以把交互任务分为两类:首要任务(与驾驶相关)和次要任务,理论上讲,次要任务的交互输入更期望是非视觉选项,因为视觉在驾驶任务中是不可替代的,需要视觉的次要任务界面会影响首要任务,从而影响驾驶的可靠性[72]。一个可替代的方案就是听觉用户界面(Auditory User Interfaces ,AUI),听觉不需要刻意集中注意力于某个界面之上。音频交互的主要挑战是自动语音识别(automatic speech recognition, ASR)。ASR算是一个比较成熟的领域,但是在车辆领域还有一些挑战,比如一些不可控的噪声(驾驶噪声,风声,道路噪声等)。除此之外,如何与ADS实现对话也是一个尚未解决的挑战。人机交互最大的挑战应该是出现在L3和L4,这两个阶段需要人和ADS互相理解对方的意图来实现手动和自动的切换。在监控自动驾驶时,驾驶员会表现出较低的主观认知欲望,尽管可以通过一些基于头部和眼睛追踪的摄像机来识别驾驶员的活动,并使用视觉和听觉来提示驾驶员做好切换准备,但目前主要是在模拟环境下实现[73],在真实环境中能够高效切换的系统目前还未出现。这是一个悬而未决的问题,未来的研究应着重于提供更好的方法来告知驾驶员以简化过渡过程。
数据集和开源工具
数据集和标准
数据集对于研究人员和开发人员来说至关重要,因为大多数算法和工具在上路之前都必须经过测试和训练。通常的做法是将传感器数据输入到一系列具有不同目标的算法中,并在标注过的数据集上测试和验证这些算法。有些算法的测试是相互关联的,有些则是单独的。CV领域已经有很多专门用于目标检测和跟踪的标注数据集,而对于端到端系统,还需要额外的车辆信号,主要包括转向和径向控制信号。
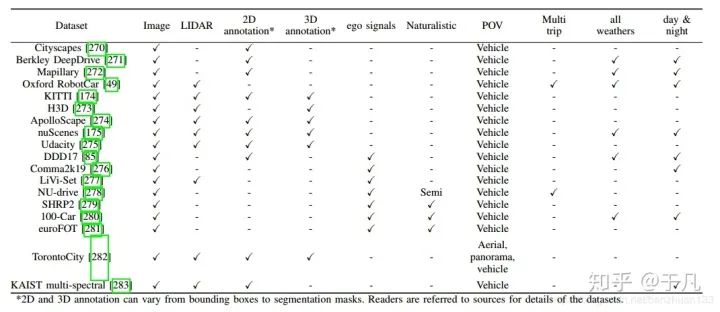
随着学习方法的出现,支持它们的训练数据集也随之出现。从2005年一直增长到2012年,PASCAL VOC数据集是第一个包含大量ADS相关数据的数据集之一。但是这些数据通常以单个对象为特征,不能代表驾驶场景中遇到的情况。2012年,KITTI Vision Benchmark通过提供大量的标记驾驶场景弥补了这一缺陷,直到现在它仍然是自动驾驶中使用最广泛的数据集之一。当然,从数量上来说,它远远比不上ImageNet和COCO这样的通用图像数据库。通用数据库在训练某一特定模块是有用的,但是由于缺少前后关联信息(the adequate context),不足以用来测试ADS的能力。加州大学伯克利分校DeepDrive是一个带有注释图像数据的最新数据集。牛津的RobotCar在英国使用六个摄像头、激光雷达、GPS和惯性导航系统收集了超过1000公里的驾驶数据,不过这些数据没有标注。还有一些其他的数据集可以见下表
开源框架和模拟器
常见的ADS开源框架包括Autoware、Apollo、Nvidia DriveWorks和openpilot等。常见的模拟器包括CARLA、TORCS、Gazebo 、SUMO等。CARLA可以模仿各种城市场景包括碰撞场景,TORCS是一个赛车仿真模拟器,Gazebo 是一个常见的机器人模拟器,SUMO可以模拟车流量。
总结
这篇文章概述了在ADS中现有的一些系统及关键的创新。目前来看,自动驾驶在很多方面都存在着明显的缺陷。无论是模块化还是端到端系统,不同的模型都存在着各自的缺陷。具体到算法,建图,定位,感知等方面,仍然缺乏准确性和效率,对不理想的路况或者天气的鲁棒性也仍有待提高。V2X仍然处于起步阶段,由于所需的基础设施比较复杂,基于云的集中式信息管理也尚未实现。人机交互的研究还比较少,存在着许多问题。本文也讨论了一些可能对自动驾驶产生重要影响的新技术的研究进展,这些进展可以克服以前的问题或者作为一种替代方法。总的来说,未来可期,但路还很长。
推荐阅读
