
【硬核干货】数据分析哪家强?选Pandas还是选SQL
Pandas和SQL之间语法的差异,相信对于不少数据分析师而言,无论是Pandas模块还是SQL,都是日常学习工作当中用的非常多的工具,当然我们也可以在Pandas模块当中来调用SQL语句,通过调用read_sql()方法建立数据库
首先我们通过SQL语句在新建一个数据库,基本的语法相信大家肯定都清楚,
CREATE TABLE 表名 (
字段名称 数据类型 ...
)
那么我们来看一下具体的代码
import pandas as pd
import sqlite3
connector = sqlite3.connect('public.db')
my_cursor = connector.cursor()
my_cursor.executescript("""
CREATE TABLE sweets_types
(
id integer NOT NULL,
name character varying NOT NULL,
PRIMARY KEY (id)
);
...篇幅有限,详细参考源码...
""")
同时我们也往这些新建的表格当中插入数据,代码如下
my_cursor.executescript("""
INSERT INTO sweets_types(name) VALUES
('waffles'),
('candy'),
('marmalade'),
('cookies'),
('chocolate');
...篇幅有限,详细参考源码...
""")
我们可以通过下面的代码来查看新建的表格,并且转换成DataFrame格式的数据集,代码如下
df_sweets = pd.read_sql("SELECT * FROM sweets;", connector)
output
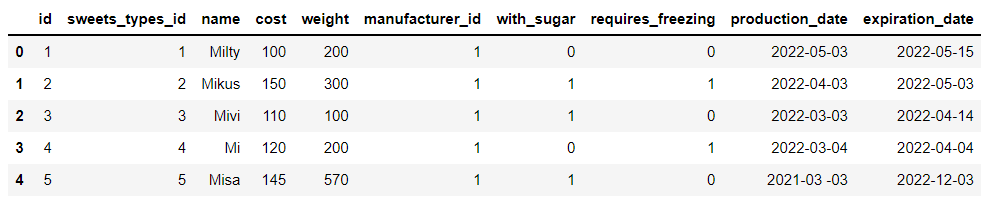
df_manufacturers = pd.read_sql("SELECT * FROM manufacturers", connector)
output

加工的数据集当中则涉及到了工厂的主要负责人和联系方式,而仓储的数据集当中则涉及到了仓储的详细地址、城市所在地等等
df_storehouses = pd.read_sql("SELECT * FROM storehouses", connector)
output

还有甜品的种类数据集,
df_sweets_types = pd.read_sql("SELECT * FROM sweets_types;", connector)
output
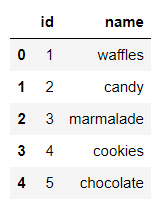
数据筛查
简单条件的筛选
Pandas模块中的代码是这个样子的# 转换数据类型
df_sweets['weight'] = pd.to_numeric(df_sweets['weight'])
# 输出结果
df_sweets[df_sweets.weight == 300].name
output
1 Mikus
6 Soucus
11 Macus
Name: name, dtype: object
当然我们还可以通过pandas当中的read_sql()方法来调用SQL语句
pd.read_sql("SELECT name FROM sweets WHERE weight = '300'", connector)
output

我们再来看一个相类似的案例,筛选出成本等于100的甜品名称,代码如下
# Pandas
df_sweets['cost'] = pd.to_numeric(df_sweets['cost'])
df_sweets[df_sweets.cost == 100].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost = '100'", connector)
output
Milty
针对文本型的数据,我们也可以进一步来筛选出我们想要的数据,代码如下
# Pandas
df_sweets[df_sweets.name.str.startswith('M')].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)
output
Milty
Mikus
Mivi
Mi
Misa
Maltik
Macus
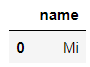
当然在SQL语句当中的通配符,%表示匹配任意数量的字母,而_表示匹配任意一个字母,具体的区别如下
# SQL
pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)
output

pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M_'", connector)
output
复杂条件的筛选
# Pandas
df_sweets[(df_sweets.cost == 150) & (df_sweets.weight == 300)].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost = '150' AND weight = '300'", connector)
output
Mikus
或者是筛选出成本价控制在200-300之间的甜品名称,代码如下
# Pandas
df_sweets[df_sweets['cost'].between(200, 300)].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost BETWEEN '200' AND '300'", connector)
output
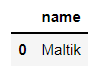
要是涉及到排序的问题,在SQL当中使用的是ORDER BY语句,代码如下
# SQL
pd.read_sql("SELECT name FROM sweets ORDER BY id DESC", connector)
output

而在Pandas模块当中调用的则是sort_values()方法,代码如下
# Pandas
df_sweets.sort_values(by='id', ascending=False).name
output
11 Macus
10 Maltik
9 Sor
8 Co
7 Soviet
6 Soucus
5 Soltic
4 Misa
3 Mi
2 Mivi
1 Mikus
0 Milty
Name: name, dtype: object
筛选出成本价最高的甜品名称,在Pandas模块当中的代码是这个样子的
df_sweets[df_sweets.cost == df_sweets.cost.max()].name
output
11 Macus
Name: name, dtype: object
而在SQL语句当中的代码,我们需要首先筛选出成本最高的是哪个甜品,然后再进行进一步的处理,代码如下
pd.read_sql("SELECT name FROM sweets WHERE cost = (SELECT MAX(cost) FROM sweets)", connector)我们想要看一下是仓储的城市具体是有哪几个,在Pandas模块当中的代码是这个样子的,通过调用unique()方法
df_storehouses['city'].unique()
output
array(['Moscow', 'Saint-petersburg', 'Yekaterinburg'], dtype=object)
而在SQL语句当中则对应的是DISTINCT关键字
pd.read_sql("SELECT DISTINCT city FROM storehouses", connector)
数据分组统计
在Pandas模块当中分组统计一般调用的都是groupby()方法,然后后面再添加一个统计函数,例如是求分均值的mean()方法,或者是求和的sum()方法等等,例如我们想要查找出在不止一个城市生产加工甜品的名称,代码如下
df_manufacturers.groupby('name').name.count()[df_manufacturers.groupby('name').name.count() > 1]
output
name
Mishan 2
Name: name, dtype: int64
而在SQL语句当中的分组也是GROUP BY,后面要是还有其他条件的话,用的是HAVING关键字,代码如下
pd.read_sql("""
SELECT name, COUNT(name) as 'name_count' FROM manufacturers
GROUP BY name HAVING COUNT(name) > 1
""", connector)
数据合并
当两个数据集或者是多个数据集需要进行合并的时候,在Pandas模块当中,我们可以调用merge()方法,例如我们将df_sweets数据集和df_sweets_types两数据集进行合并,其中df_sweets当中的sweets_types_id是该表的外键
df_sweets.head()
output
df_sweets_types.head()
output
具体数据合并的代码如下所示
df_sweets_1 = df_sweets.merge(df_sweets_types, left_on='sweets_types_id', right_on='id')
output
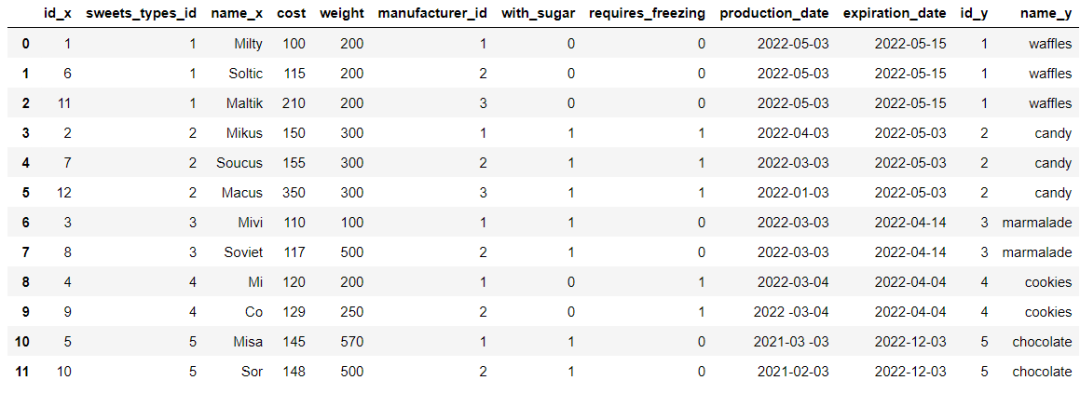
我们再进一步的筛选出巧克力口味的甜品,代码如下
df_sweets_1.query('name_y == "chocolate"').name_x
output
10 Misa
11 Sor
Name: name_x, dtype: object
而SQL语句则显得比较简单了,代码如下
# SQL
pd.read_sql("""
SELECT sweets.name FROM sweets
JOIN sweets_types ON sweets.sweets_types_id = sweets_types.id
WHERE sweets_types.name = 'chocolate';
""", connector)
output

数据集的结构
我们来查看一下数据集的结构,在Pandas模块当中直接查看shape属性即可,代码如下
df_sweets.shape
output
(12, 10)
而在SQL语句当中,则是
pd.read_sql("SELECT count(*) FROM sweets;", connector)
output
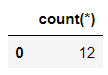
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码