来源:AAAI
编辑:Q、小匀
【新智元导读】日前,AAAI 2021公布了各奖项名单,在最受瞩目的最佳论文奖中,共有3篇论文获此殊荣,其中华人一作占2席。更可喜的是,今年华人学者的表现在其余奖项中也十分亮眼。
人工智能领域的最重磅会议之一的AAAI 人工智能大会以虚拟会议的形式拉开帷幕!
在开幕式上,组委会公布了最佳论文奖等各奖项名单。其中,3篇论文获得最佳论文奖,3篇论文被评为Best Paper Runners Up,6篇论文被授予杰出论文奖。
让我们浏览一下本次大会要点。
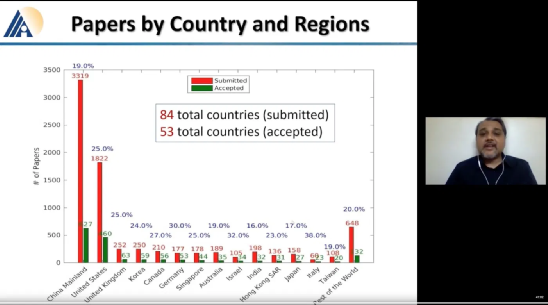
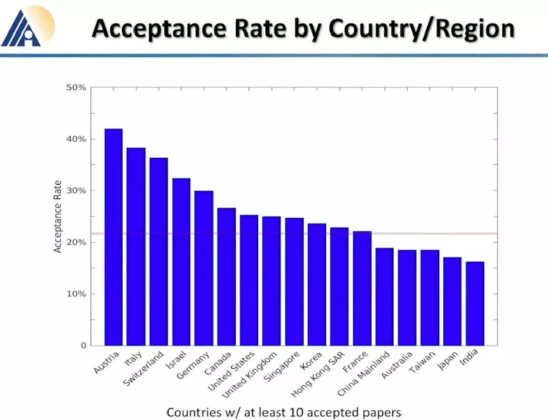
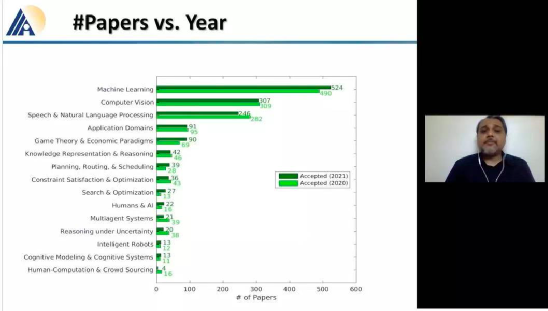
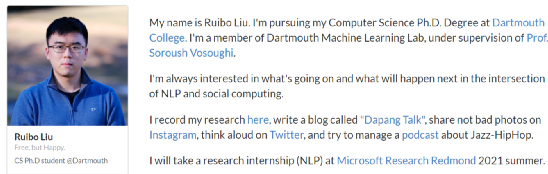
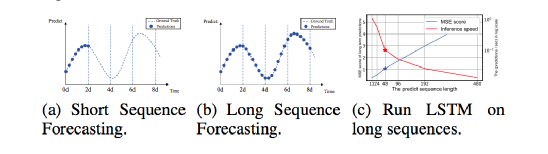
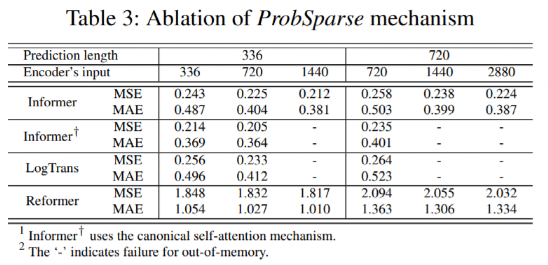
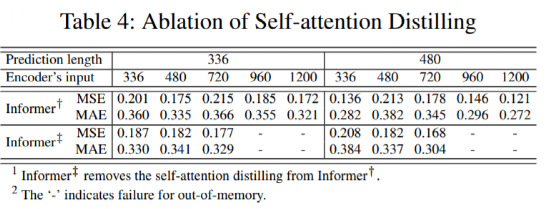
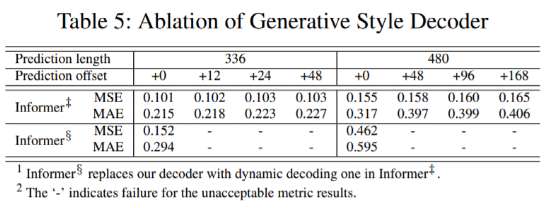
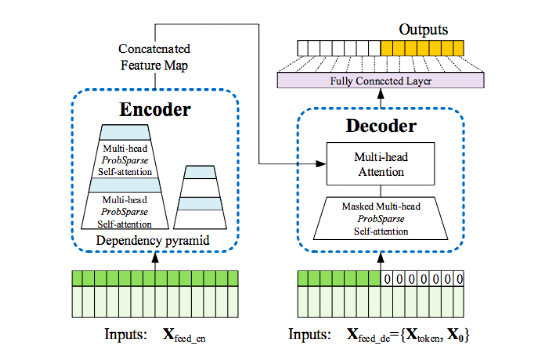
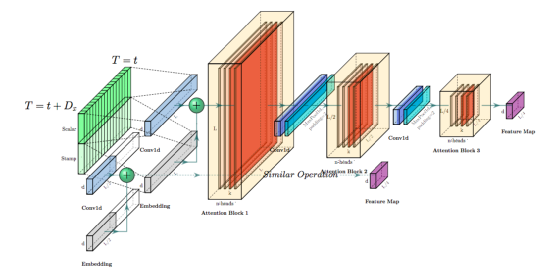
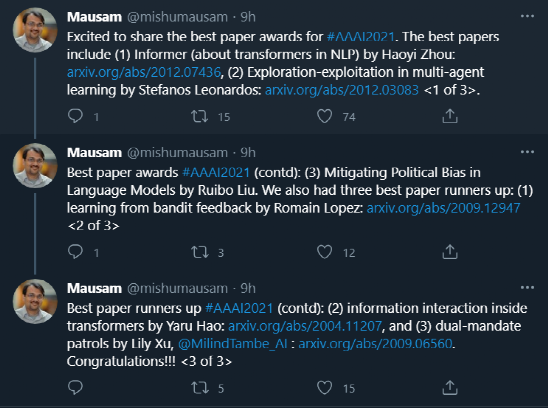
英属哥伦比亚大学的Kevin Leyton-Brown 和 印度理工学院的 Mausam 联合担任 AAAI 2021 的程序委员会主席。本次AAAI 2021共有PC(Program Committee)成员9493位,其中高级606名高级PC,246名领域内主席。平均来说,每位成员都要评审2.82篇论文(其中最少0篇,最多6篇)。AAAI 2021的投稿总数为9034篇,再创历史新高,超过了去年的8800篇。其中,来自中国的投稿量(3319篇)几乎是来自美国的论文(1822篇)的两倍。在7911篇送审论文中,共有1692篇论文入选。今年的录用率为21%,略高于去年的20.6%。不过,需要注意的是,中国论文的接受率并不如投稿数般尽如人意。下图显示了17个国家的论文接受率,我们可以看到中国大陆排到了第13名,落后于中国香港的第11名。排名接受率前五分别是奥地利、意大利、瑞士、以色列、德国;第6到第10则是加拿大、美国、英国、新加坡、韩国;中国台湾则排到了15名,日本第16,印度以第17垫底。在细分领域,无论是投稿数还是接受率,最高的仍然来自于机器学习,其以524/2654的比率高居榜首。其余则依次是计算机视觉(CV)、语音与自然语言处理(Speech & Natural Languages Processing)、数据挖掘与知识管理(Data Mining & Knowledge Management)、应用领域(Application Domains)、博弈论与经济范畴(Game Theory & Economic Paradigms)等等。不过仔细分析,虽然语音与自然语言处理的投稿量和接受率虽然都很高,但相比于去年是有所下降的。本次有三篇论文脱颖而出,夺得最佳论文(Best Papers),其中有两篇文章是华人一作。Informer:Beyond Efficient Transformer for Long Sequence Time-Series Forecasting论文链接:https://arxiv.org/pdf/2012.07436.pdf这篇论文主要为长序列时间序列预测(LSTF)的问题设计了一个基于Transformer的模型——Informer,大幅提高了LSTF的推断速度,并且优于现有的算法。论文的一作之一是来自北京航空航天大学的Haoyi Zhou,目前是北航的在读博士。Exploration-Exploitation in Multi-Agent Learning: Catastrophe Theory Meets Game Theory论文链接:https://arxiv.org/pdf/2012.03083.pdf这篇论文的作者研究了Q-Learning的平滑模拟,展现探索-开发在多智能体学习中的效果,展示了学习模型作为研究探索-开发的最佳模型的强有力的理论依据。Mitigating Political Bias in Language Models Through Reinforced Calibration论文链接:https://www.cs.dartmouth.edu/~rbliu/aaai_copy.pdf这篇论文主要提出了衡量GPT-2生成中产生的政治偏见的指标,并且提出了一种强化学习框架,用来缓解生成的文本中的偏见。通过使用来自词嵌入或分类器的奖励,作者提出的RL框架无需访问训练数据或要求对模型进行重新训练即可指导去偏生成。其中,Ruibo Liu是这篇文章的一作,从他在达特茅斯学院的简介上可以看出,他的研究兴趣在NLP和社交计算的交叉领域,并且今年暑期会到雷德蒙德微软研究所实习。本次除了公布以上三篇最佳论文之外,还有三篇论文获得Best Paper Runners Up。Learning From EXtreme Bandit Feedback论文链接:https://arxiv.org/pdf/2012.07436.pdf这篇论文中,作者研究了在极大的动作空间中通过Bandit Feedback进行批处理学习的问题,同时介绍了一种选择性重要性抽样估计器(sIS),该估计器在明显更有利的偏差-方差体制下运行。Selt-Attention Attribution: Interpreting Information Interactions Inside Transformer论文链接:https://arxiv.org/pdf/2012.07436.pdf在这篇论文中,作者提出了一种自注意力归因算法来解释Transformer内部的信息交互,同时以BERT为例进行了广泛的研究。Dual-Mandate Patrols: Multi-Armed Bandits for Green Security论文链接:https://arxiv.org/pdf/2009.06560.pdf巡逻人员必须在很大范围巡逻以保护珍稀动植物免受攻击者(例如偷猎者或非法伐木者)的侵害。作者将问题描述为随机的多臂老虎机问题,每个动作代表巡逻策略,使之能够保证巡逻策略的收敛速度。同时为了提高性能,还利用了奖励功能的平滑性和动作的可分解性。此外,大会还公布了「杰出论文奖」(Distinguished Papers),共有6篇论文获得该奖项:其中题为「Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation」是来自中国学者的,一作是深圳市计算机视觉与模式识别重点实验室、华南理工大学Hongbin Xu。时间序列预测在许多领域都起到关键作用,比如传感器网络监控、能源和智能电网管理、经济和金融,以及疾病传播分析等。在这些场景中,我们可以通过大量的时间序列来利用过去行为的数据进行长期预测,即长序列时间序列预测(LSTF)。然而,现有的方法都是在有限的问题下进行设置,比如预测48 points或更少。(a)短序列预测仅仅揭示了比较近的未来情况;(b)长序列时间序列预测可以延展到一个更长的时间周期中,来做出更好的policy-planning和investment-protecting;(c)现有方法预测的容量限制了长序列的表现现在,越来越多的长序列使得模型的预测能力受到限制,一些人认为这一趋势是LSTF研究持续发展的原因。Transformer虽然具有提高预测能力的潜力,但由于二次时间复杂度、内存占用率高、编码器-解码器架构等固有限制,使得无法直接应用于LSTF。这篇论文设计了基于Transformer的LSTF模型,并命名为Informer,它具有以下三个特点:1.ProbSparse自注意力机制,时间复杂度为O(Llog L),并在序列的依赖性对齐上有相当不错的表现。2.自注意力蒸馏通过将级联层输入减半来突出了注意力,并高效处理极长的输入序列。3.生成式的解码器虽然概念简单,但它会在一次正向操作的方式预测较长的时间序列,而不是一步步的进行预测,极大地提高了长序列预测的推理速度。Encoder接收大量的长序列输入(绿色部分),此处用文中提出的ProbSparse自注意力机制代替了标准的自注意力机制。蓝色梯形是自注意力蒸馏,可以提取主导注意力( dominating attention),大幅减小网络大小,层之间的堆叠也提高了鲁棒性。Decoder部分接收长序列作为输入,将目标元素填充为零,测量特征图的加权注意力构成,并以生成式的方式即时预测输出元素(橙色部分)。 图中的每个水平堆栈都代表一个单独的编码器;其中,上层栈是主栈,接收整个输入序列,而第二堆栈则取一半输入;红色部分是自注意力机制的点积矩阵,并通过在每层上应用「自注意蒸馏」,减少级联;最后,将两个堆栈的特征图合并,作为编码器的输出。通过在四个大型数据集上进行的大量实验表明,Informer的性能明显优于现有方法,并且为LSTF问题提供了新的解决方案。