AAAI 2021开幕:华人大满贯,北航学子“摘下”最佳论文,两名微软亚研院中国学者获得首个杰出SPC奖

大数据文摘授权转载自学术头条
刚刚!人工智能顶级会议 AAAI 2021 在线上开幕,作为 2021 年首个人工智能顶会,华人学者取得了大满贯。
具体表现为:两名中国来自微软亚洲研究院的中国学者获得了杰出 SPC 奖,其在众多资深程序主席中脱颖而出。这两位的名字是 Xiting Wang 和吴方照。
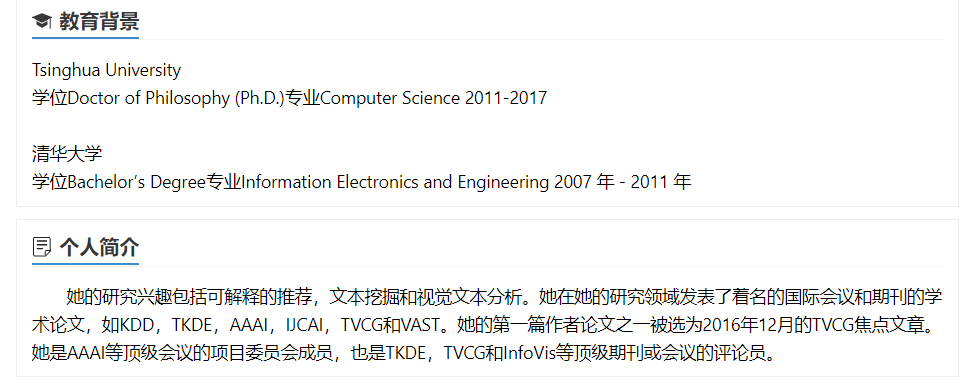
根据 AMiner 主页,我们得知 Xiting Wang 毕业于清华大学,其研究兴趣包括可解释的推荐,文本挖掘和视觉文本分析。吴方照也是毕业于清华大学,目前是微软亚洲研究院社会计算 (SC) 组的高级研究员。

此外,中国学者还获得了一篇杰出论文,题目为 “Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-augmentation”,翻译为中文为 “通过有效的协同分割和数据增强实现多视角立体的自我监督。” 作者 Hongbin xu 来自深圳市计算机视觉与模式识别重点实验室。
论文主要研究内容是:最近的研究表明,基于视图合成的自监督方法在多视图立体 (MVS) 上取得了明显的进展。然而,现有的方法依赖于不同视图之间对应的点具有相同的颜色的假设,这在实践中可能并不总是正确的。这可能会导致不可靠的自监督信号,损害最终的重建性能。为了解决这个问题,作者提出了一个以语义共分和数据增强为指导,集成了更可靠的监督框架。
论文地址:
http://34.94.61.102/paper_AAAI-2549.html

拿下了两篇最佳论文亚军。第一篇 “Self-Attention Attribution:Interpreting Information interactions inside transformer” 的一作名为 Yaru Hao,来自北京航空航天大学,二作名为董力,来自微软研究院。这篇论文说,当前基于 Transformer 的一些模型,大多将其成功之处归功于多头自我注意机制,这种机制从输入中学习 token,并对上下文信息进行编码。先前的工作主要致力于针对具有不同显著性度量的单个输入特性的贡献模型决策,但它们未能解释这些输入特征如何相互作用以达到预测。因此,这篇论文提出了一种自注意力归因算法来解释 Transformer 内部的信息交互。并以 BERT 为例广泛进行研究。
论文地址:

第二篇 “Dual-Mandate Patrols: Multi-Armed Bandits for Green Security”,其一作 Lily xu(华人面孔,不确定是否是华人)是哈弗大学的博士生,第三作者中文名为方飞是卡内基梅隆大学计算机科学系的助理教授,其研究方向是博弈论 + 机器学习。这篇论文的主要研究内容是:环境保护。其从强化学习中的多臂老虎机 (Multi-armed Bandit) 算法入手,探究了如何避免偷猎者伤害野生动物。据悉,其算法在柬埔寨的真实偷猎数据上训练之后,其性能显著提升。
论文地址:

拿下了两篇最佳论文,其中一篇 “Informer: Beyond Efficient Transformer for Long SequenceTime-Series Forecasting”,第一作者名为 Haoyi Zhou 来自北航。这篇论文设计了一种高效的基于变换的长序列时间序列预测模型 Informer,旨在解决 Transformer 存在一些严重的问题,如二次时间复杂度、较高的内存使用量和编解码器结构的固有限制等等。
论文地址:
第二篇名为 “Mitigating Political Bias in Language Models Through Reinforced Calibration”,第一作者名为 Ruibo Liu,显然是为中国学子,来自达特茅斯学院计算机科学系,根据题目,这篇论文的主要研究内容是 “语言模型中的政治偏见” 问题。
论文数据一览

本届大会共评出了 3 篇最佳论文,3 篇最佳论文亚军以及 6 篇杰出论文,11 个杰出资深主席,13 个优秀程序主席,此外还评出了前 25% 的评审者。
关于论文的评审,大会组委会说,在 rebuttal 阶段,论文作者回应后,有 4537 篇论文的分数得到了改变,其中 40% 的论文分数上涨,60% 的论文分数下降。然而其实,只有 69% 的评审对了作者的回应.....
这次会议一共收到了 7911 篇论文,接收了 1696 篇,其接收率是 21.4%。与历年相比,其接受率处于中等。值得一提的是,学生论文有 70.6% 的接受率。
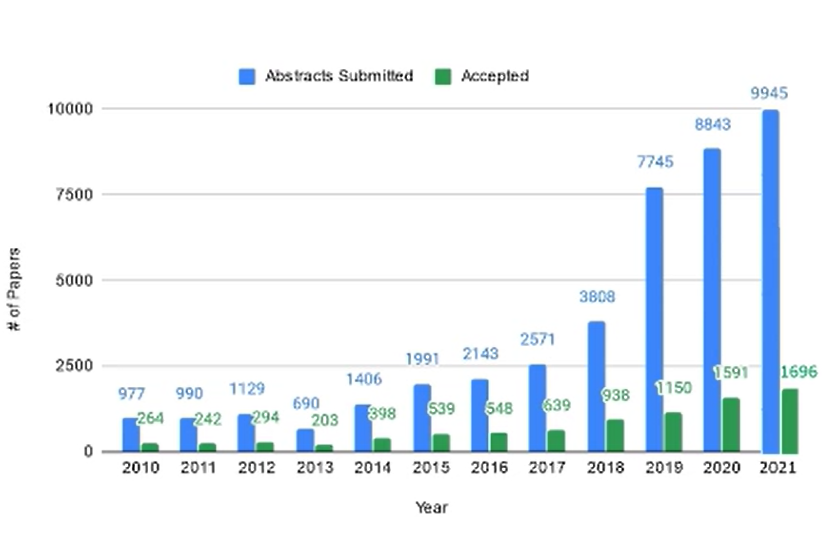
关于投稿总数,近几年 AI 领域一直处于上涨状态,除了 2019 年相较于 2018 年有了近一倍的增长之外,这两年投稿量增长则是缓慢趋势。录取率并不是稳定或者线性的,从上图曲线可以看出,录取率是波动状态,且 2019 年最低,只有 16.9%;最高当属 2013 年,接近 30%。
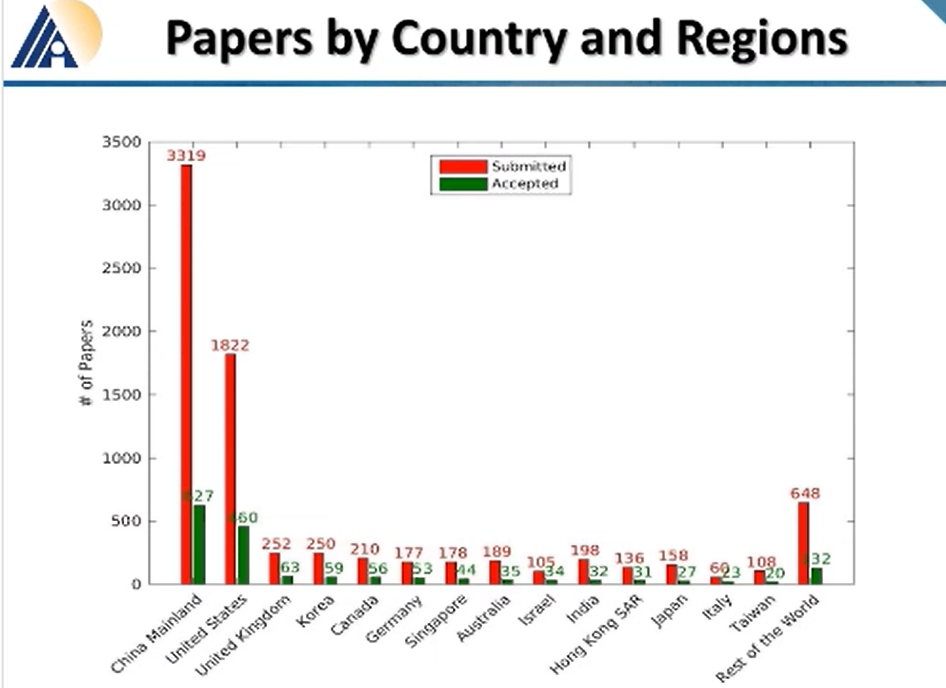
论文分地区来看,中国大陆论文总数仍然占据榜首,3319 篇的论文提交,627 篇的论文录取,其有 19.0% 的录取率。不过从提交的数目来看,占据了 1/3,录取数占据了 36%。中国香港和中国台湾也成绩颇丰,分别有 31 篇和 20 篇被录取。
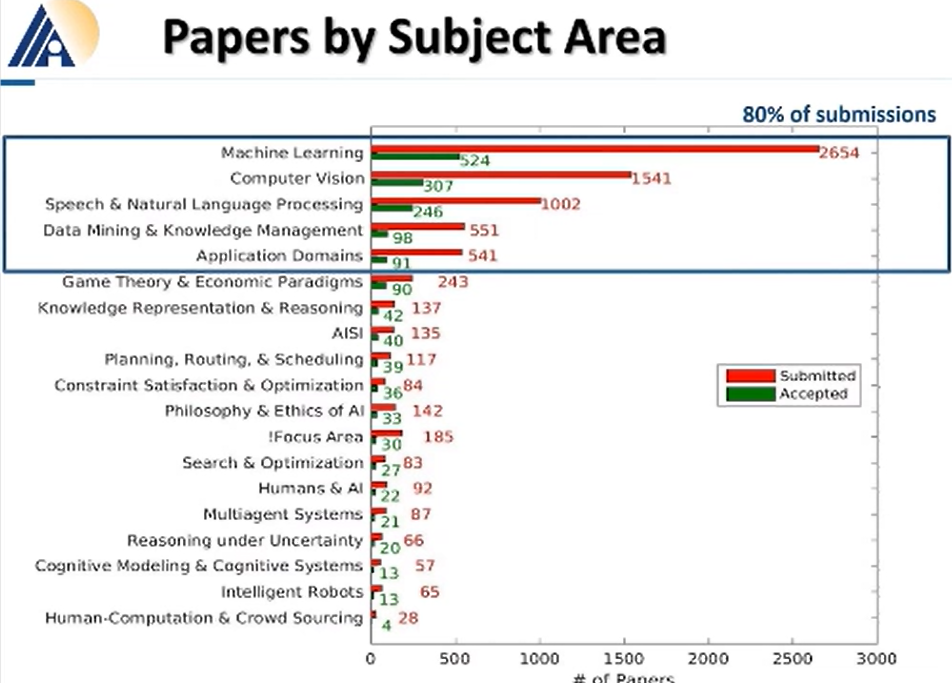
论文分领域来看,机器学习、计算机视觉、NLP 以及数据挖掘和应用程序域分别占据总提交论文的 80%。
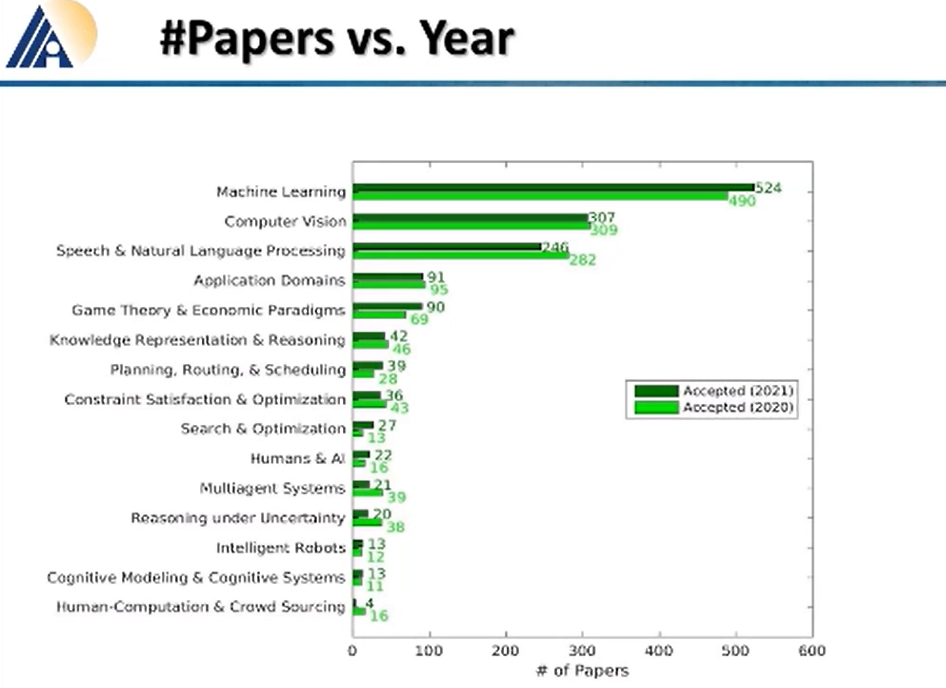
和去年相比,这个 “热度” 排名仍然没有改变。机器学习、计算机视觉、NLP 以及数据挖掘和应用程序域论文收录数分别排名第一、第二、第三、第四。
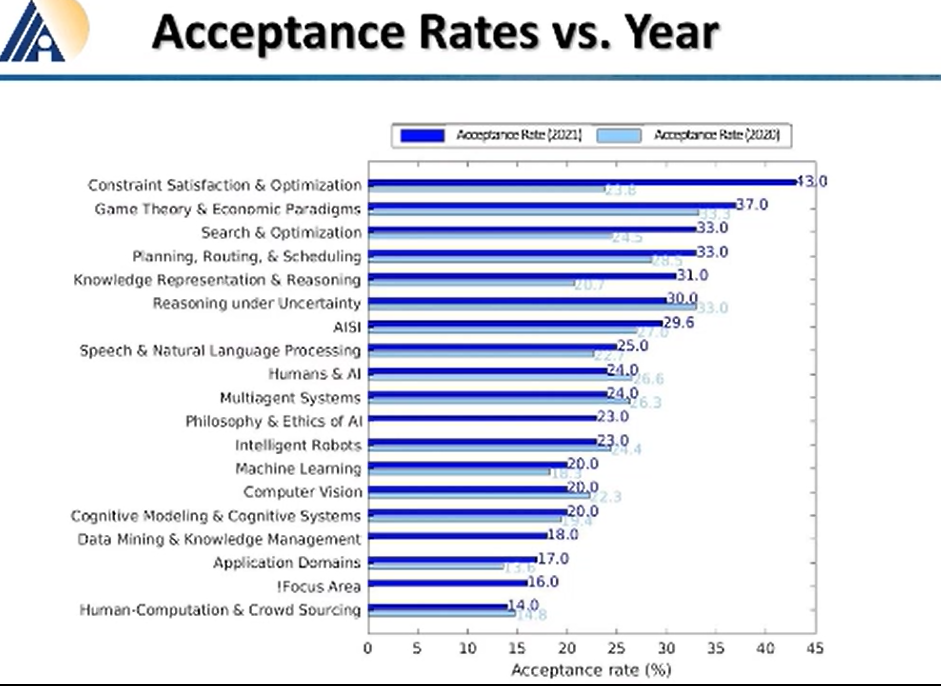
哪个领域的论文接收率最高,组委会说,优化领域今年有 43% 的接受率,博弈论原理,搜索分别有 37%、33% 的接受率。而机器学习和计算机视觉各只有 20% 的接受率。
OMT:两轮审稿政策
除了公布这些奖项,本次大会,还花了浓墨重彩介绍了本届 AAAI 采用两轮审稿政策,组委会说,共收到 9034 篇投稿。两轮审稿政策对应两类文章,第一类是非 NeurIPS 和 EMNLP 转投论文;第二类是 NeurIPS 和 EMNLP 转投论文。
第二类论文中,经过修改后的重投论文,如果是来自 NeurIPS,且总分数高于 4.9;如果是 EMNLP,且总分数高于 2.8 的话。那么可以直接进入到 AAAI 2021 审稿的第二阶段。
在第一阶段,每篇论文将分配两名审稿人。如果这两个审稿人认为该论文无法被录用,那么该论文将直接被拒绝。没有被拒的论文将进入第二阶段。
在第二阶段中,每篇论文将另外分配两个审稿人。新的审稿人给出意见之前,他们是无法看到第一阶段的评论,也就是审稿相互独立。这意味着每篇被录取的论文至少有四名审稿人把关,因此质量肯定能够保证。
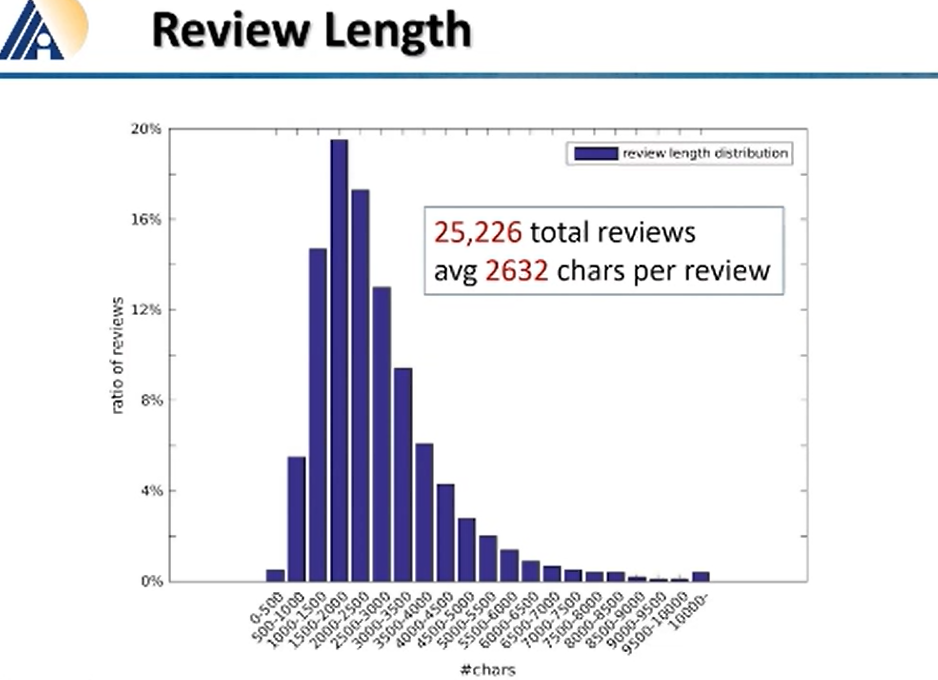
在审稿过程中,评审们共写了 25226 个字的 “建议”,平均下来每位审稿人有 2632 个字。
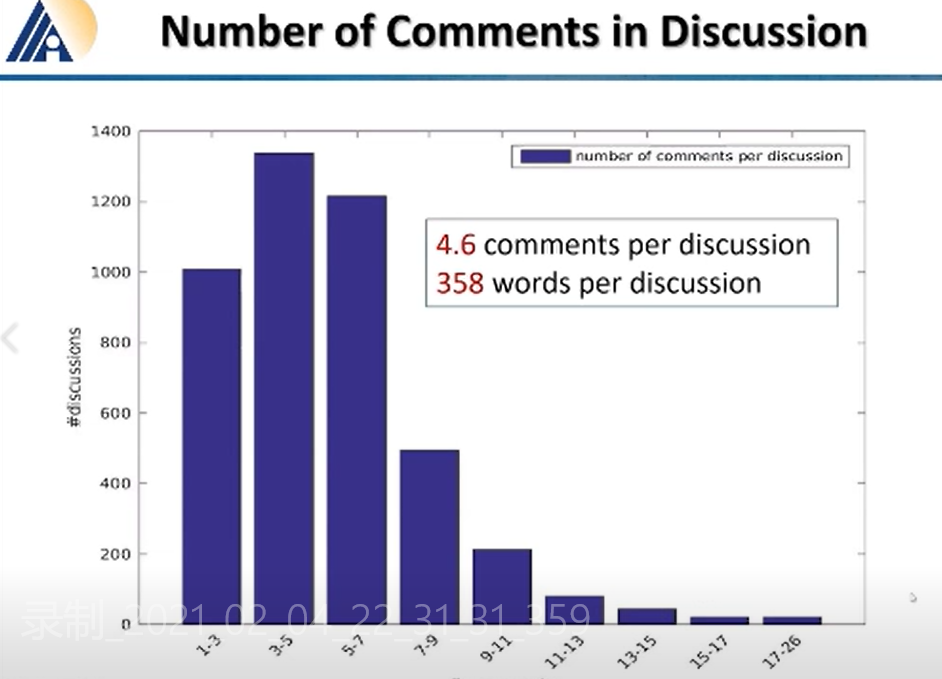
在讨论中,大多数论文的讨论有 3~5 位参与,极少数有 17~26 位参与。当然。1~3 位和 5~7 位参与的讨论的论文数,也有 1000 以上。平均下来,每篇论文有 4.6 个人参与讨论,每个讨论包含字数 358 个。