
从 wiscKey 看 LSMtree 的不足
作者简介:
Apache Pulsar committer Apache BookKeeper contributor Apache Pulsar Go client 作者及国内主要维护者 Apache Pulsar Go Functions 作者及国内主要维护者 Stremnative/pulsarctl 作者及国内主要维护者 streamnative/rop 作者及国内主要维护者
近期,阅读WiscKey论文深有感触,特写这篇文章来阐述自己的观点。
说一句废话就是:任何软件的发展,其实都依赖于硬件的设计和进步,所以从这一点来看,LSMtree诞生于上世纪80年代,在那个年代,还是机械硬盘的时代。所以,可以看的到的是,整个LSMtree最初的构建思想都是基于机械硬盘的设计思路,但是需求是无止境的。WiscKey自我感觉是,在LSMtree的基础上,基于SSD的设计思路所做的一种优化,基于这个思路,我们来简单分析一下论文中所阐述的观点。
先阐述几个LSMtree的概念:
Read amplification is the number of I/O’s required to satisfy a particular query Write amplification is the amount of data written to storage compared to the amount of data that the application wrote. Space amplification is the space required by a data structure can be inflated by fragmentation or requirements for temporary copies of the data.
读写放大就不说了,知道LSMtree的人基本都了解,现在说一下空间放大的问题。
空间放大大体上是说:存储采用的数据结构因分裂或临时数据拷贝造成的磁盘空间占用放大。
LSMtree诞生的那一天起,并不是为了存储这些大的value的情况。在这种大value的情况下LSMtree的性能会急速下降,所以,其实数据库都有自我的一种保护机制,来限定每一行value所能够存储的最大值。下面是wisckey和LSMtree的对比,可以看到在value较大的时候,wisckey的性能要远远大于LSMtree的。

下面是随机和排序之后,wisckey和LSMtree的对比:
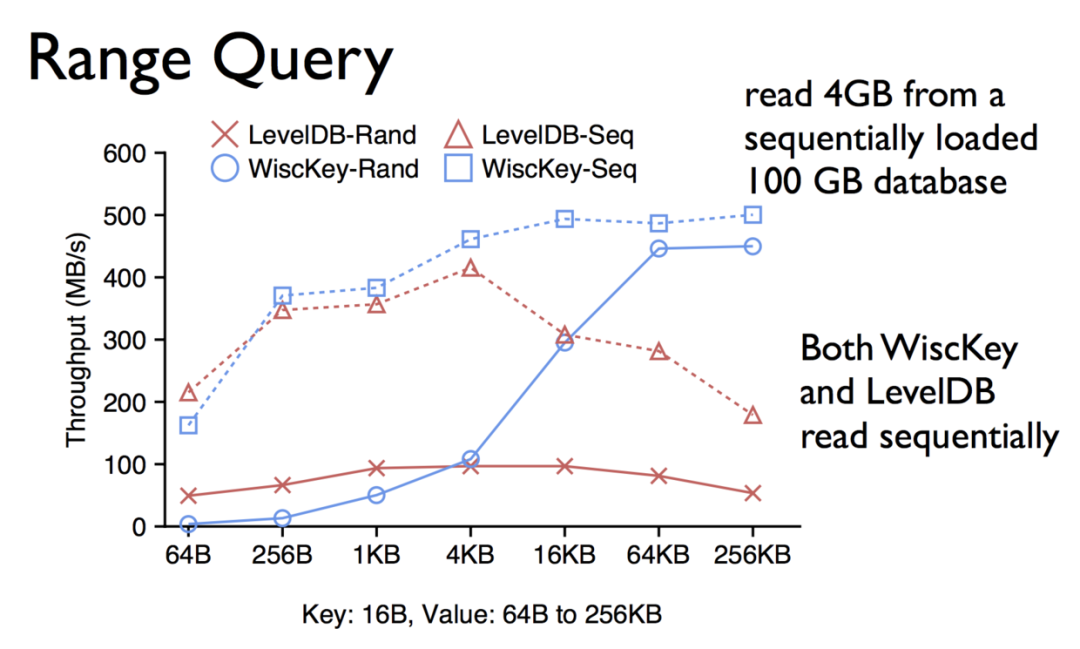
其次,LSMtree都有这种compaction的操作,在做compaction的时候,对磁盘IO的压力是比较大的。再者,LSMtree并不能很好的利用SSD的并行计算能力,这一点也可以理解。
但是,在当下的存储引擎中,LSMtree还是很受欢迎,从性能的角度来考量,读写放大哪怕是空间放大(这三者是不可并存的)我最差的情况也就放大个10-50倍左右的放大成本,但是我能在性能上带来将近千倍的速度提升(将随机写转化为顺序写),所以,在性能面前,这些都是可以容忍的。
SSD与SATA的差异
顺序IO与随机IO 并行计算能力 大量的重读写会使SSD的寿命降低。
当value较大的时候,LSMtree的表现
value越大,越容易触发compaction LSMtree的每一层level都可以简单理解为其下一层的cache,value越大,cache的效果越差,每次访问读取到下层level的概率会增加。 每条数据每次merge的时候,会造成写入的量增加。
wisckey诞生的前景
其实,我们可以仔细回想一下,在LSMtree中,我们并不需要value是有序的,只要保证key是有序的,就可以满足我们的需求。所以,我们是否可以考虑将key继续存储在LSMtree中,而将value区分存储到log文件中,然后把value的指针一起存储到LSMtree中,是的,这也是wisckey的思路:分离后的模型大致如下:

此时,我访问数据的思路是这个样子的:
insert:先append到value log的末尾,再将刚才append的value的地址塞到LSMtree中。 delete:将key从LSMtree中删除,当compaction的时候,如果找不到对应的key那就在垃圾回收的时候顺便一起将它回收掉就OK。 select:拿LSMtree中的key+addr直接获取到value对应的地方,拿出来就行。
wisckey key/value分离的优势
首先,key的存储数据量相比原先的存储模型减少的不仅仅是一个量级,所以,可以充分发挥LSMtree的特性。其次,将value分离之后,避免了compaction操作的时候无效的value移动,从而极大的降低了读写放大,增加SSD的使用寿命。再者,由于key的存储量级的减少,cache能起到更好的效果。
可能引发的问题
之前对range进行操作的时候,只需要顺序读就OK,但是k/v分离之后,可能需要顺序读+多次随机读来达到目的,论文中提到,这个可以充分利用SSD的并行能力解决,但是能解决多少有待进一步追踪。
上面也提到,lsmtree中value的delete操作,是依赖于compaction的时候的GC来操作的,但是k/v分离导致这个回收是异步的进行。基于这一点,我们来看看wisckey的处理思路:

whiskey优化了原有垃圾回收的做法,head指向最新的block插入的位置,tail表示回收value操作开始的那个位置,GC被触发之后,我们从tail开始进行扫描,将有效的block移到head的后面,把tail到head的这一段位置清空,重置tail和head标记。不难看出,将有效的block后移这个操作,在某种程度上也带来了写放大,但是的确提高了效率,总之是在时间和空间这两个点上进行权衡。wisckey他会根据delete这个操作请求的多少来决定触发GC的时机。
奔溃一致性。
由于分离操作,一旦出现事故,wisckey如何保证奔溃情况下的一致性问题呢?
对key和value的操作都是原子的,总共分为三种情况: key/value都写入成功,OK这就是我们要的效果。 key写入成功,value写入失败,则把LSMtree中的key删除,返回value不存在。 key写入失败,value写入成功,返回不存在,写入的value在后续的垃圾回收中回收掉就OK。 如果遇到宕机重启,在恢复的过程中,它是顺序恢复的。
可能存在的问题
假如我的value log中存储的都是一些较短的value,每次都需要和磁盘交互,对磁盘的吞吐量是一种考验。在这里是否可以考虑添加一层缓存结构,将多个小的value合并之后再写。 待续
最后,致敬一下国外同行,关于这篇论文有一篇100页的slides[1]和PDF[2],非常详尽的描述了这篇论文的思路。
参考资料
WiscKey:slides: https://www.usenix.org/sites/default/files/conference/protected-files/fast16_slides_lu.pdf
[2]WiscKey:pdf: https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf