
从JavaScript看字符编码的前世今生!

导语 | 每个程序员都应该了解一下字符编码,有了基础概念之后我们对编程语言、字符处理能有更深入的理解。本文我花了大量时间进行资料查阅和考证,希望能够给大家带来一些帮助,多多交流!
一、起因
最近在研究Babel的源码,在看到Acorn词法解析源码中有这样一段逻辑:
pp.fullCharCodeAtPos = function() {let code = this.input.charCodeAt(this.pos)if (code <= 0xd7ff || code >= 0xdc00) return codelet next = this.input.charCodeAt(this.pos + 1)return next <= 0xdbff || next >= 0xe000 ? code : (code << 10) + next - 0x35fdc00}
这段代码初看的时候完全不得其解,看起来像是判断了编码范围,重新计算了一个编码。于是朝着字符编码的方向深入探索了一下,结果发现了一段庞大的历史。
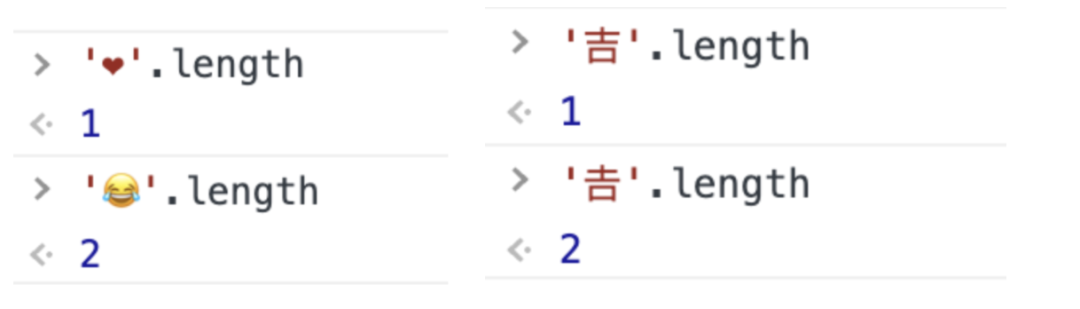
记得在前几年,Emoji的问题还蛮火的,大家都挺奇怪,为什么有的Emoji在JavaScript里的长度是2,还有一个'𠮷'的问题好像更火一些:
二、字符编码的早期历史
(一)从电报说起
在电报还没发明以前,要想进行长途通信,只能通过驿站、信鸽、烽烟这样的形式,需要一个非常高昂的成本。在18世纪,大家开始研究电的特质,以及用电来传输讯息的可能。
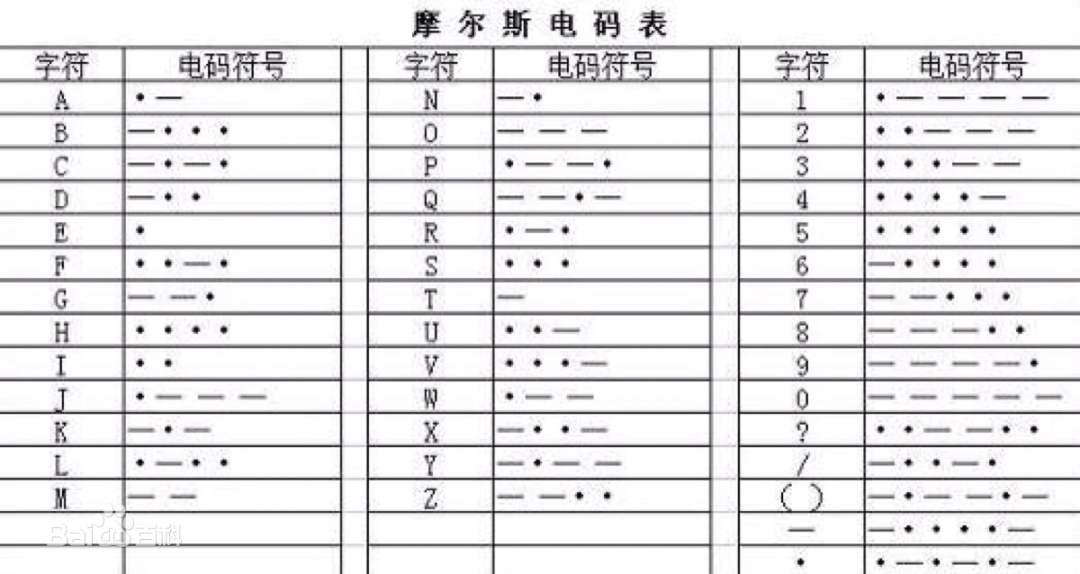
(二)摩尔斯电码——最早期的数字化通信
美国发明家萨缪尔·摩尔斯在1836年发明了摩尔斯电码,开启了电报时代,首条真正投入使用营运的电报线路于1839年在英国最先出现。它是大西方铁路装设在两个车站之间作通讯之用。

摩尔斯电码,是一个使用点(·)和划(-)来表示编码的,根据时间维度的间隔,我们可以通过查表解析:
最早的中文电报,是采用了四位阿拉伯数字作代号,从0001到9999按四位数顺序排列,用四位数字表示最多一万个汉字、字母和符号。
(三)ASCII——开启电脑字符编码的时代
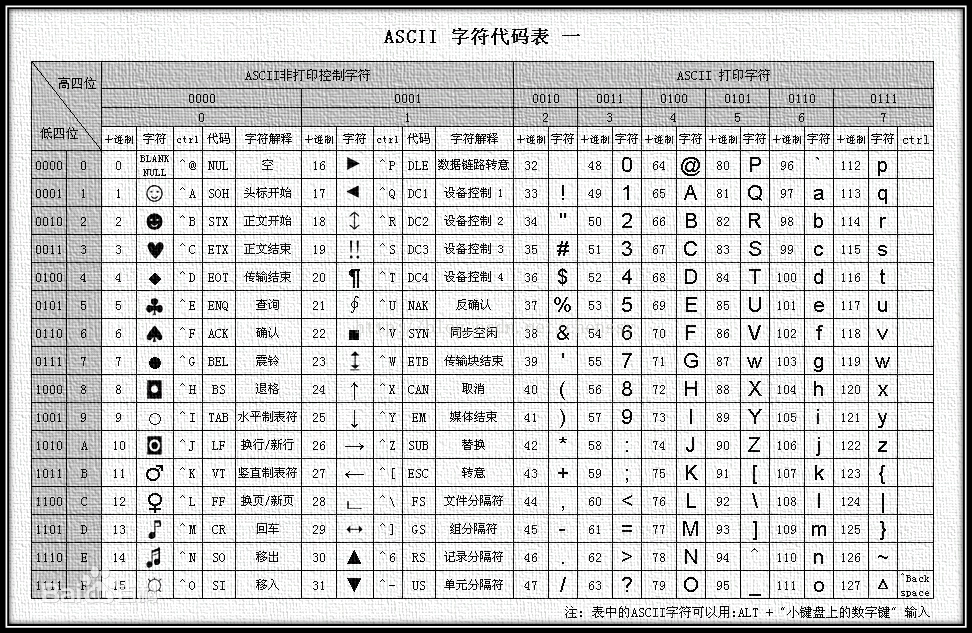
1946年,世界上第一台通用电脑ENIAC诞生,那时候它还是一个电子数值积分计算机,无法进行字符的表示。直到1963年,美国国家标准学会(American National Standard Institute , ANSI )颁布了ASCII编码方案。
我们都知道,在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
ASCII码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。标准ASCII 码也叫基础ASCII码,使用7位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0到9、标点符号,以及在美式英语中使用的特殊控制字符。
三、非英语国家字符编码的混乱时代
(一)ISO/IEC 646-7比特的最后挣扎
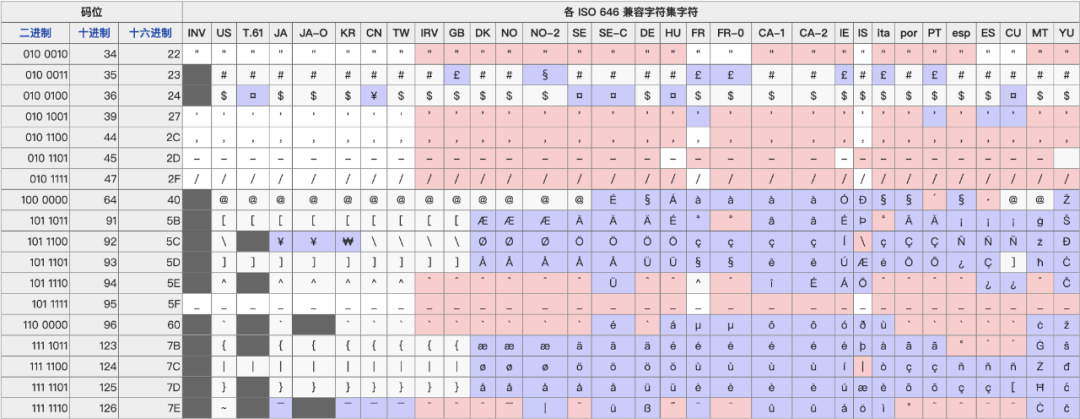
ISO/IEC 646是国际标准化组织(ISO)和国际电工委员会(IEC)于1972年制订的标准。ISO 646除了英语字母和数字部分,为所有国家相同外,有些使用字母的国家,可按照实际需要,把 ISO 646修改,以定出该国的字符标准。
ISO 646为了表示欧洲各种语言的带附加符号(diacritical mark)的变音字母,由于没有码位空间去直接编码这些变音字母,所以用几个标点符号来兼作变音字母的附加符号:
撇号(apostrophe)兼作尖音符(acute accent);
反引号(backquote、backtick、opening quote mark)作为重音符(grave accent);
双引号(double quotation mark)兼做分音符(diaeresis或umlaut);
脱字符(caret)兼做扬抑符(circumflex accent);
代字号(swung dash)兼做颚化符(tilde);
逗号(comma)兼做下加符(cedilla)
可以看到,在7比特的情况下,很多国家的字符都不够用,会将原ASCII字符替换成自己的版本:
(二)ISO 2022-一个兼容ASCII和大字符的8比特方案
很快人们就发现7比特并不能满足大部分拉丁语言,ASCII本质上是由通信领域发展而来,通信领域的协议采用了第8位做校验纠错用途。但是,对于计算机内存来说,校验纠错变得不是必要。因此8位字符编码逐渐出现,用来表示比ASCII码更多的字符。为此,1971年公布的ECMA-35标准,用来规定各种7位或8位字符编码应当遵从的共同规则。随后ECMA-35被采纳为ISO 2022。
ISO 2022兼容7比特的编码空间,0x00-0x1F是留给控制字符,0x20-0x7F表示图形字符。因此,在1个7比特的字符编码空间,图形字符总计为94个(由于空格符占用了0x20码位、Del符占用了0x7F码位)。
对于双字节的7比特编码空间,图形字符可以有94x94即8836个。这个在当时也作为中日韩等以汉字为主要字符集的编码方案。
ISO 2022规定字符集的控制字符可分为两块:C0,C1;打印(图形)字符分为四块:G0,G1,G2,G3。对于7比特编码,字节值0x00-0x1F保留给C0控制字符块;字节值0x20-0x7F用于G0, G1, G2, G3字符块。对于单字节编码的字符集,1个打印(图形)字符块可包含94个或96个字符;对于双字节编码的字符集,1个打印(图形)字符块可包含94x94个字符。使用控制符的转义序列来表示在G0,G1,G2,G3之间的切换。
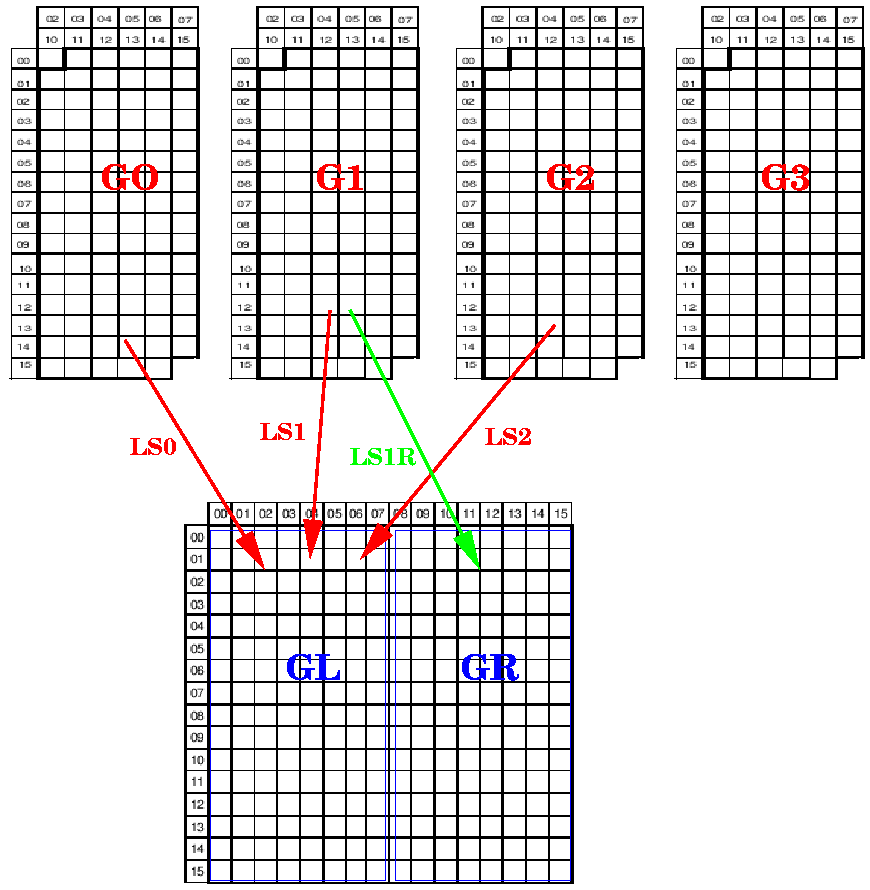
在ISO 2022的规定下,产生了两大方向,一个是以西方拉丁语言为主的8比特字符集方案,另一个是以中日韩等国家为主的双字节8比特编码方案:
ISO/IEC 8859-8比特的拉丁文字符集标准
ASCII收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的附加符号字母,故可以使用ASCII及控制字符以外的区域来储存及表示。
除了使用拉丁字母的语言外,使用西里尔字母的东欧语言、希腊语、泰语、现代阿拉伯语、希伯来语等,都可以使用这个形式来储存及表示。
1982年,ANSI与ECMA合作开启此项工作。1985年,公布了ECMA-94,即后来的ISO/IEC 8859 parts 1, 2, 3, 4。第5、6、7、8、9、10、11、12、13、14、15、16部分分别公布于1988年、1987年、1987年、1987年、1989年、1992年、2001年、1997年(正式宣布放弃研发)、1998年、1998年、1999年、2001年。
ISO 8859是基于ISO 2022标准的基础上,在ISO 2022规定的G0码位区域表示ISO 646的95个可打印字符;在C0与C1的控制字符码位区域,表示ISO 6429定义的控制字符;而在G1码位区域,则是由ISO 8859的16个部分各自定义扩展的可打印字符。因此,ISO 8859完全兼容7位的ASCII码。ISO 8859没有使用ISO 2022中的G2、G3区域,也不再使用ISO 2022定义的用来在不同的字符编码集或在同一个编码集的G0、G1、G2、G3区域间转换的“控制字符转义序列”。
GB2312-基于EUC存储的双字节8比特方案
GB/T 2312,GB/T 2312–80 或 GB/T 2312–1980 是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,通常简称GB(“国标”汉语拼音首字母),又称GB0,由中国国家标准总局于1980年发布,1981年5月1日实施。GB/T 2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB/T 2312。
GB/T 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB/T 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB/T 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现以解决这些问题。
GB/T 2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号,共计94个区。用所在的区和位来表示字符(实际上就是码位),因此称为区位码:
01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
10~15区:空区,留待扩展;
16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
88~94区:空区,留待扩展。
为了避开ASCII字符中的CR0不可显示字符及空格字符,国标码(又称为交换码)规定表示汉字双字节编码范围为(33,33)~(126,126) 。因此,须将“区码”和“位码”分别加上32,作为国标码。以避免与ASCII字符中0~32的不可显示字符和空格字符相冲突。
但是国标码还是和通用的ASCII码有冲突,因此把国标码中的每个字节的最高位都从0换成1,即相当于每个字节都再加上128,从而得到国标码的“机内码”表示,简称“内码”。
在这里内码也就是GB2312的字节表示了,它是遵循EUC存储规范的,也就是在区位都加上0xA0,以避免和ASCII的冲突。

四、大一统时代的纠结与争执
虽然ISO 2022的出现,让各个国家都定义了自己的字符集,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。
尤其是互联网的出现,让统一编码成为更迫切的需求。
但是,有两个组织都想做这件统一的工作:
国际标准化组织(ISO)于1984年创建的ISO/IEC
由Xerox、Apple等软件制造商于1988年组成的统一码联盟
(一)ISO 10646标准-陷入政治旋涡的标准
ISO 10646最开始发布的字符集是UCS-4,它是每个字符用四个八位字节编码,用来存放全世界不同的语言。理论上,UCS-4拥有4294967296个码点,可以支撑全球范围内所有的文字,有人说,这个码点在银河系毁灭的时候都用不完。
但正是由于这个前瞻性的决策,让ISO 10646遇到了推行上的阻碍,当时正处于施乐公司的鼎盛时期,施乐在上世纪80年代初期推广了一种国际字符集(后来发展成为了Unicode),当时施乐联合了一批支持者,包括Joe Becker、Lee Collins(现在在Taligent)、Eric Mader和Dave Opstad(Apple),已经在考虑Unicode,Unicode开发的参与范围扩大到了领先的行业代表社区,包括Bill English(Sun Microsystems)、Asmus Freytag(微软)、Mark Kernigan(隐喻)、Rick McGowan (NeXT)、Isai Scheinberg(IBM)、Karen Smith-Yoshimura (Research Libraries Group)、Ken Whistler(加州大学伯克利分校的语言学家,Metaphor)等等。
于是ISO 10646遭到无比强烈的抵制,当时Unicode采用的是16位的编码形式,支持65536的字符,以美国为首的这些计算机厂商当然不想浪费4个字节去存储一个字符,对他们来说,65536已经足够了,而且他们认为全球的文字都可以映射到这个字符集上。
经过几年的纠结挣扎,ISO标准最终妥协,1993年发布了ISO 10646-1,采用UCS-2,与Unicode保持一致,也成为了Unicode 1.1,这也影响了当时产生的程序语言(比如今天的重点JavaScript,以及老牌的Java语言等)。
从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字体,但ISO 10646一般都尽可能采用Century字体。
(二)Unicode-最终的胜利者
经过角逐,电脑软硬件厂商发起的Unicode最终成为了领域的业界标准。Unicode编码方式与ISO 10646的通用字符集概念相对应。目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示216(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
上述16位统一码字符构成基本多文种平面。最新(但未实际广泛使用)的统一码版本定义了16个辅助平面,两者合起来至少需要占据21位的编码空间,比3字节略少。但事实上辅助平面字符仍然占用4字节编码空间,与UCS-4保持一致。未来版本会扩充到ISO 10646-1实现级别3,即涵盖UCS-4的所有字符。UCS-4是更大而尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示231个字符,完全可以涵盖一切语言所用的符号。
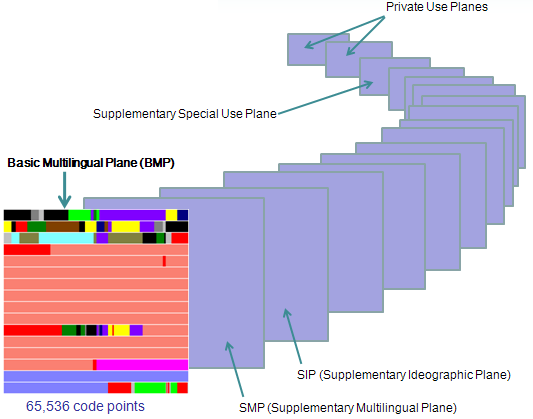
目前的Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536(即216)个代码点。然而目前只用了少数平面。

基本多文种平面(Basic Multilingual Plane, BMP),或称第0平面或0号平面(Plane 0),是Unicode中的一个编码区块。编码从U+0000至U+FFFF。
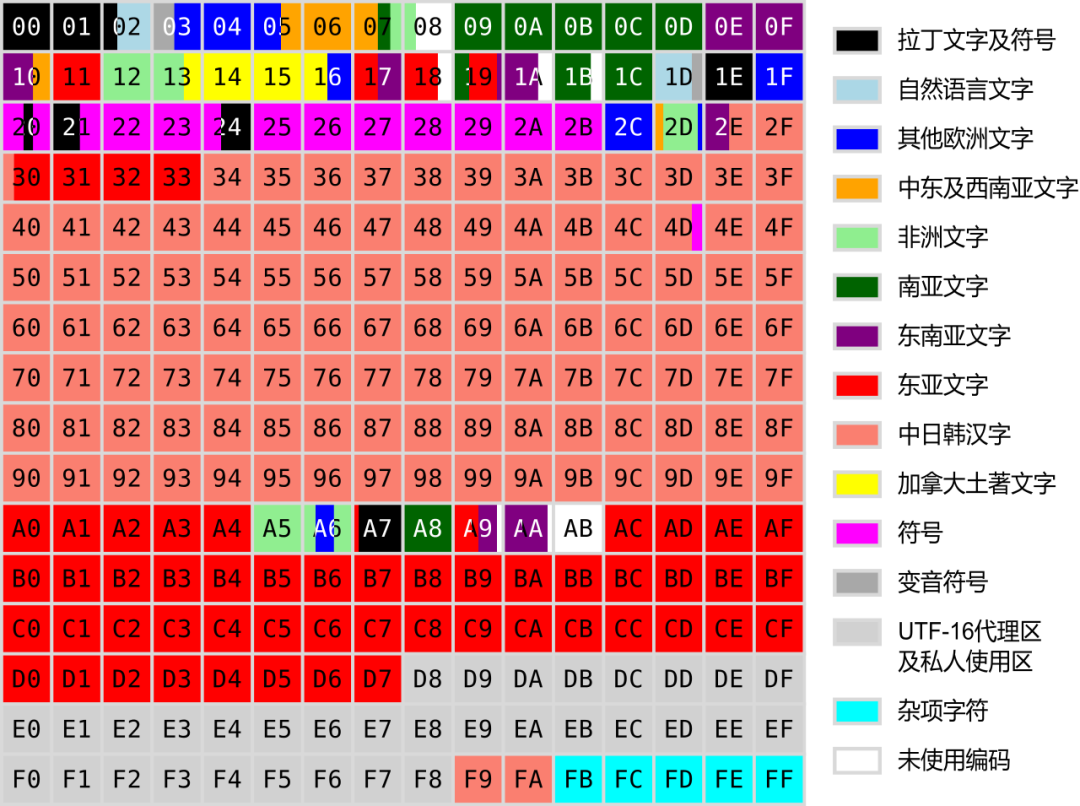
(三)中日韩统一表意文字-汉字的纠结
中日韩统一表意文字(英语:CJK Unified Ideographs),也称统一汉字、统汉码(英语:Unihan),目的是要把分别来自中文、日文、韩文、越南文、壮文、琉球文中,起源相同、本义相同、形状一样或稍异的表意文字,在ISO 10646及Unicode标准赋予相同编码。
1991年,各国希望能以一致的方式处理文字,否决了ISO/IEC 10646的初版草案。基于中国与统一码联盟的提议,ISO 10646和统一码成立了中日韩联合研究小组。中日韩联合研究小组将基于各国的汉字编码,独自定义定规范、制作ISO 10646和统一码的统一汉字编码。年尾,完成了Unified Repertoire and Ordering(URO)。1992年,URO加入ISO 10646的第二版。但是,发现了一些缺失,之后进行了修正。
1993年5月,正式制订最初的“中日韩统一表意文字”,位于U+4E00–U+9FFF这个区域,共20,902个字。还有一个汉字“〇”(码位U+3007),被当成数字放入了符号和标点区。一个月后,制订了统一码1.1。
但是,汉字的统一至今仍然收到不少批评:
合并异体字,虽有助减少收录字数,但在研究学术时,如古籍、历史及文字研究等,部分文献却要将字形不同之字同时并行。已合并的各个字,在这些文献里变得各有各意思。学者若使用Unicode,遇到这种情况,就要用不同电脑字体去显示同一个字码,甚至要自行造字,或舍Unicode而用其他编码。一来查找、转换电脑字体构成不便,二来有损Unicode记录每一个字之用意,三来不能以纯文本交换,四来电脑字体或因授权条款之限,难以交换流传。另外,这亦等于不能以Unicode准确记录文献,不利于文本的电脑化。
不同字形之字合并后,若检索方法以字形为本,会产生混乱,难以检索。例如笔画检字,艸部之“艹头”,中国、日本算作三画,而传统中文为四画,留有“艸”形者则为六画。Unicode同一字码,源于字形不同,就有几种笔画,检索混乱。即使检出字,笔画与显示出来的字形也不相符。因此,批评者认为,Unicode合并异体字并不可取。
但是另一方面,Unicode收录不少幽灵汉字,人们难以找到其出处,它们在实际生活上也极少机会使用,有些甚至是错讹字,或者仅是某一个人的名字用字,那个人不见得是名人,甚至可能已去世,却永久成为标准里的字符,占用了一个码位。比如台湾律师吕秋逺,他名字里的“逺”字,户政人员误听他外公说的台语,把“辵字边”听成“走马边”,变成了

外公又不敢更正。当事人长大后,才确认这是错字,“五千年来从来没人这么写过”。但这字已永久收进Unicode中。又如香港增补字符集里的许多人名用字,都被学者指出乃属讹写,或者是来历不明的自创新字,多部权威字书都没有收录,学者批评把这些字收进字库后将会永久遗害。中文信息界的李祥在其专栏批评当局“解决不了增补字集中上千错字、白字、生造字的读音问题”,呼吁“不要把香港增补字符集与申请ISO强迫联系在一起”。然而,这些人名讹字亦已经收进Unicode中。这构成了收字过多的争议。
也有批评认为Unicode收入大量错讹字及写法高度相似的同一字的不同字形本身就是不应该的。电脑文本本身永远不可能完全无损地记录文献,且文献本身也会因传抄制版等原因略有不同,如果把每个字的各种写法全部编码,会浪费空间。完全无损地研究、记录文献只能通过查看原本或照相复印版来完成,把无损保存转嫁给编码是错误的。
现时Unicode把一些异体字分别编码,带来了检索困难。只要写法稍有不同,就无法检出,令使用户检索字词时,必须反复检索其不同写法,造成重复劳动,对文献研究反而是种妨碍。例如Unicode中将“兒”和“𠒇”字安放在不同的码位里。在检索文献时,检索“兒”字时就找不到“雷庄𠒇”,检索“𠒇”字时就找不到“雷庄兒”,反而造成困扰。
五、Unicode实现方式——UTF的转换
Unicode的实现方式不同于编码方式。一个字符的Unicode编码确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
(一)UTF-32
UTF-32是最简单的一种实现方式,使用32位比特对每个Unicode码位进行编码。UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
UTF-32的主要优点是可以直接由Unicode码位来索引。在编码序列中查找第N个编码是一个常数时间操作。相比之下,其他可变长度编码需要进行循序访问操作才能在编码序列中找到第N个编码。这使得在计算机程序设计中,编码序列中的字符位置可以用一个整数来表示,整数加一即可得到下一个字符的位置,就和ASCII字符串一样简单。
UTF-32的主要缺点是每个码位使用四个字节,空间浪费较多。在大多数文本中,非基本多文种平面的字符非常罕见,这使得UTF-32所需空间接近UTF-16的两倍和UTF-8的四倍(具体取决于文本中ASCII字符的比例)。
关于UTF-32和UCS-4的关系:
2003年11月,由于UTF-16编码形式的限制,RFC 3629标准将Unicode限制为仅支持U+10FFFF以内的码位(另外U+D800到U+DFFF范围内也被保留使用。虽然在之前的ISO标准(1998年的Unicode 2.1)中0xE00000到0xFFFFFF和0x60000000到0x7FFFFFFF这些区域被分配给“保留私人使用”,但这些区域也在后续版本中被删除。在 ISO/IEC JTC 1/SC 2 WG2申明中规定UCS-4将来所有的字符分配将被限制在Unicode范围内,所以UTF-32和UCS4能表示的字符是相同的。
(二)UTF-16
把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
很多人会把UTF-16误认为是定长的2字节表示,实际上是跟UCS-2的混淆:
UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支持UCS-2编码,那其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
我们看一下UTF-16是怎样映射到非基本平面的:
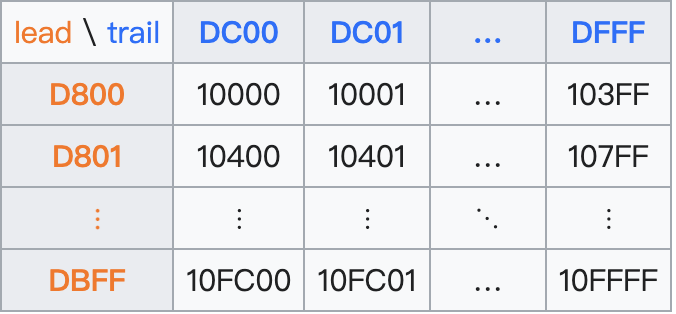
辅助平面(Supplementary Planes)中的码位,在UTF-16中被编码为一对16比特长的码元(即32位,4字节),称作代理对(Surrogate Pair),具体方法是:
码位减去 0x10000,得到的值的范围为20比特长的0...0xFFFFF。
高位的10比特的值(值的范围为0...0x3FF)被加上0xD800得到第一个码元或称作高位代理(high surrogate),值的范围是 0xD800...0xDBFF。由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。
低位的10比特的值(值的范围也是 0...0x3FF)被加上 0xDC00 得到第二个码元或称作低位代理(low surrogate),现在值的范围是 0xDC00...0xDFFF。由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
上述算法可理解为:辅助平面中的码位从U+10000到U+10FFFF,共计FFFFF个,即220=1,048,576个,需要20位来表示。如果用两个16位长的整数组成的序列来表示,第一个整数(称为前导代理)要容纳上述20位的前10位,第二个整数(称为后尾代理)容纳上述20位的后10位。还要能根据16位整数的值直接判明属于前导整数代理的值的范围(210=1024),还是后尾整数代理的值的范围(也是210=1024)。因此,需要在基本多语言平面中保留不对应于Unicode字符的2048个码位,就足以容纳前导代理与后尾代理所需要的编码空间。这对于基本多语言平面总计65536个码位来说,仅占3.125%。
注意:Unicode标准规定U+D800...U+DFFF的值不对应于任何字符。这才让UTF-16代理对的实现变成了可能。
UTF-16的使用在历史上真的非常广泛:
UTF-16 用于所有当前支持的Microsoft Windows版本(至少包括自Windows CE/2000/XP/2003/Vista/7以来的所有版本)(包括Windows 10)的OS API中的文本。在Windows XP中,U+FFFF以上的代码点不包含在随Windows提供的任何欧洲语言字体中。较旧的Windows NT系统(Windows 2000之前)仅支持UCS-2。文件和网络数据往往是 UTF-16、UTF-8和传统字节编码的混合。
Python语言环境从2.0版本开始官方只在内部使用UCS-2,但UTF-8解码器到“Unicode”会产生正确的UTF-16。从Python 2.2开始,支持使用UTF-32的“宽”Unicode 版本;这些主要用于Linux。Python 3.3不再使用 UTF-16,而是从ASCII/Latin-1、UCS-2和UTF-32中选择为给定字符串提供最紧凑表示的编码。
Java最初使用UCS-2,并在J2SE 5.0中添加了UTF-16补充字符支持。
JavaScript可能使用UCS-2或UTF-16。从ES2015开始,字符串方法和正则表达式标志已添加到语言中,允许从与编码无关的角度处理字符串。
PHP语言和MySQL也支持UCS-2。
Swift 5,Apple的首选应用程序语言,从UTF-16切换到UTF-8作为首选编码。
(三)UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
UTF-8的编码规则非常简单,通过前导位来区分Unicode的不同区间:

它的可变范围在1-6个字节之间。另外,UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以“10”开始,使文字处理器能够较快地找出每个字符的开始位置。
在Mac中,默认文件就是UTF-8编码,MySQL字符编码集中有两套UTF-8编码实现:“utf8”和“utf8mb4”,其中“utf8”是一个字最多占据3字节空间的编码实现;而“utf8mb4”则是一个字最多占据4字节空间的编码实现,也就是UTF-8的完整实现。这是由于MySQL在4.1版本开始支持UTF-8编码(当时参考UTF-8草案版本为RFC 2279)时,为2003年,并且在同年9月限制了其实现的UTF-8编码的空间占用最多为3字节,而UTF-8正式形成标准化文档(RFC 3629)是其之后。限制UTF-8编码实现的编码空间占用一般被认为是考虑到数据库文件设计的兼容性和读取最优化,但实际上并没有达到目的,而且在UTF-8编码开始出现需要存入非基本多文种平面的Unicode字符(例如emoji字符)时导致无法存入(由于3字节的实现只能存入基本多文种平面内的字符)。直到2010年在5.5版本推出“utf8mb4”来代替、“utf8”重命名为“utf8mb3”并调整“utf8”为“utf8mb3”的别名,并不建议使用旧“utf8”编码,以此修正遗留问题。

六、关于 JavaScript 到底采用什么字符编码
在ECMAScript5.1规范中:
A conforming implementation of this International standard shall interpret characters in conformance with the Unicode Standard, Version 3.0 or later and ISO/IEC 10646-1 with either UCS-2 or UTF-16 as the adopted encoding form, implementation level 3. If the adopted ISO/IEC 10646-1 subset is not otherwise specified, it is presumed to be the BMP subset, collection 300. If the adopted encoding form is not otherwise specified, it is presumed to be the UTF-16 encoding form.
可以看到,JavaScript引擎可以在内部自由使用UCS-2或UTF-16。目前大多数引擎实现都是UTF-16。
这就可以解释开头提到的问题,为什么在JS里,❤是一个长度,😂是两个长度,很简单:
'❤'对应的Unicode为U+2764
'😂'对应的Unicode为U+1f602
'吉'对应的Unicode为U+5409
'𠮷'对应的Unicode为U+20bb7
所以,'❤'和'吉'都在Unicode的BMP内,而'😂'和'𠮷'都在扩展平面,受到UCS-2的影响,JavaScript的length实现,并没有识别出扩展平面外的字符。
在引擎内部,其实扩展平面的字符基本都是UTF-16表示,以'😂'为例,我们来推算一下:
'😂'对应的Unicode为U+1f602,将它表示为代理对:
码位减去0x10000,得到0xf602
高位的10比特的值加上0xD800,得到高位代理0xd83d,计算过程如下:
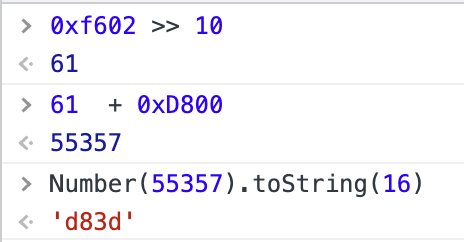
低位的10比特的值加上0xDC00,得到低位代理0xde02,计算过程如下:

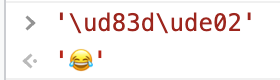
最后,我们验证下代理对(0xd83d,0xde02):
所以现在不难理解JavaScript为什么会有这样的表现了,实际上TC39就针对这个问题探讨过:

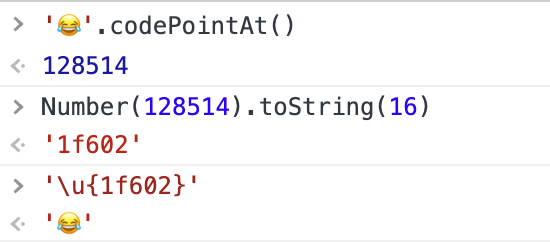
所以ES6提供了访问Unicode码点的方法:
顺便提一下,新一代的编程语言,已经采用utf-8来实现字符串了(我始终觉得代理对就是一个蹩脚的方式去兼容当时ucs-2的不足):
Golang采用utf-8实现string
Rust采用utf-8实现string,utf-32实现char
回到Acorn的实现,其实就是在将非基本平面的字符,往后解析出它的码元,但实现方式不是很直观,有兴趣的同学可以用数学知识去推算一下,我这里给出更直观的实现版本(MDN):
/*! http://mths.be/codepointat v0.1.0 by @mathias */if (!String.prototype.codePointAt) {(function() {; // 严格模式,needed to support `apply`/`call` with `undefined`/`null`var codePointAt = function(position) {if (this == null) {throw TypeError();}var string = String(this);var size = string.length;// 变成整数var index = position ? Number(position) : 0;if (index != index) { // better `isNaN`index = 0;}// 边界if (index < 0 || index >= size) {return undefined;}// 第一个编码单元var first = string.charCodeAt(index);var second;if ( // 检查是否开始 surrogate pairfirst >= 0xD800 && first <= 0xDBFF && // high surrogatesize > index + 1 // 下一个编码单元) {second = string.charCodeAt(index + 1);if (second >= 0xDC00 && second <= 0xDFFF) { // low surrogate// http://mathiasbynens.be/notes/javascript-encoding#surrogate-formulaereturn (first - 0xD800) * 0x400 + second - 0xDC00 + 0x10000;}}return first;};if (Object.defineProperty) {Object.defineProperty(String.prototype, 'codePointAt', {'value': codePointAt,'configurable': true,'writable': true});} else {String.prototype.codePointAt = codePointAt;}}());}
最直观的核心换算:
C = (H - 0xD800) * 0x400 + L - 0xDC00 + 0x10000七、写在最后
字符编码实际上牵扯到各个国家的文化、政治、统一等问题,已经不纯粹是一个技术问题,因此在历史的过程中会产生各种包袱和技术债,也导致了我们在编程中会遇到各种神奇的问题。
每个程序员都应该了解一下字符编码,有了基础概念之后我们对编程语言、字符处理能有更深入的理解。本文我花了大量时间进行资料查阅和考证,希望能够给大家带来一些帮助,多多交流!
参考资料:
作者简介

孟健
腾讯高级工程师
2016年加入腾讯,先后负责厘米秀、腾讯课堂的研发工作,现为在线教育部研发效能负责人,腾讯课堂开发负责人。同时担任公司Teflow OTeam、Orange-CI Oteam的PMC,负责公司前端工程化、DevOps方向的建设工作。项目方面,主导腾讯课堂支付架构设计,涉及七大支付方式及九大营销工具,帮助课堂支付业务外网事故率降0。另外,是公司内部效能平台Thanos的作者,该平台通过流程模板引擎、冲突锁机制、完整的操作记录等核心技术支撑数百人的日常研发和部署工作。在知乎、掘金等均有高质量高赞回答及文章输出,是开源框架Vue.js的Contributor之一。
推荐阅读
