
从操作系统看Docker
Linux 操作系统的内核裁剪不仅是为了提升系统的安全性,而且是为了进一步提升应用系统的性能。如《Linux 内核裁剪框架初探》所述,Linux 的内核裁剪技术并没有得到广泛的应用,对于安全性、应用的性能以及开发效率而言,业界普遍采用的是虚拟化技术——虚拟机和容器。无论哪一种虚拟化技术,本质上都可以看作是操作系统能力的抽象、分拆和组合。
虚拟化技术一瞥
无论是哪一种虚拟化技术,都是在操作系统之上的不同抽象,从而形成了分层的架构。层次越多,调用链也相应地变长,运行时的开销也就越大。
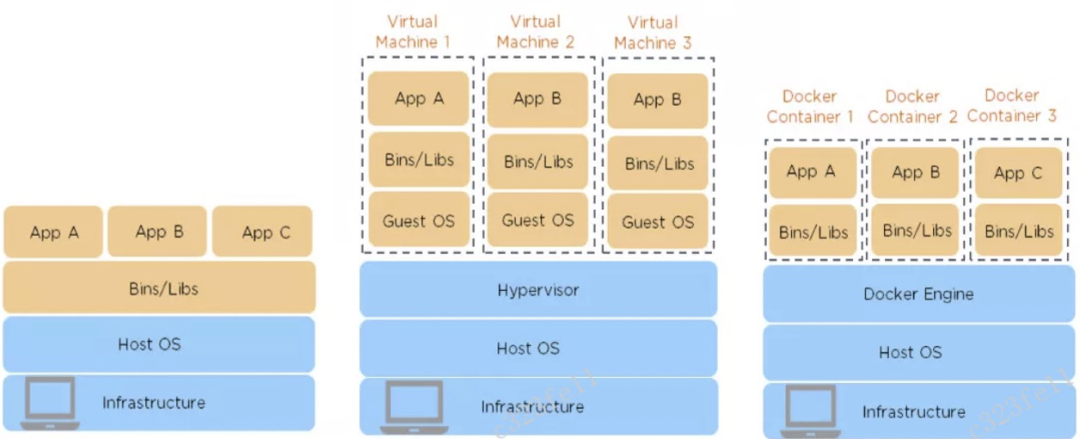
如上图所示,虚拟机中的Hypervisor 这一层是一个常用的硬件虚拟化软件,把操作系统抽象为多个底层的硬件接口,利用这些硬件接口,虚拟机可以实现自己操作系统。Docker则不同, 它构建在原有的操作系统之上,是某种程度的复用。
从部署时间来看,物理机由于涉及到采购和软硬件安装等因素,部署的时间最长,虚拟机则要短很多,Dcoker则是秒级的。
2013年,Docker 对外开源,2014年6月9日正式发布,很快便风靡全球,容器虚拟化技术的发展脉络大致是这样的——
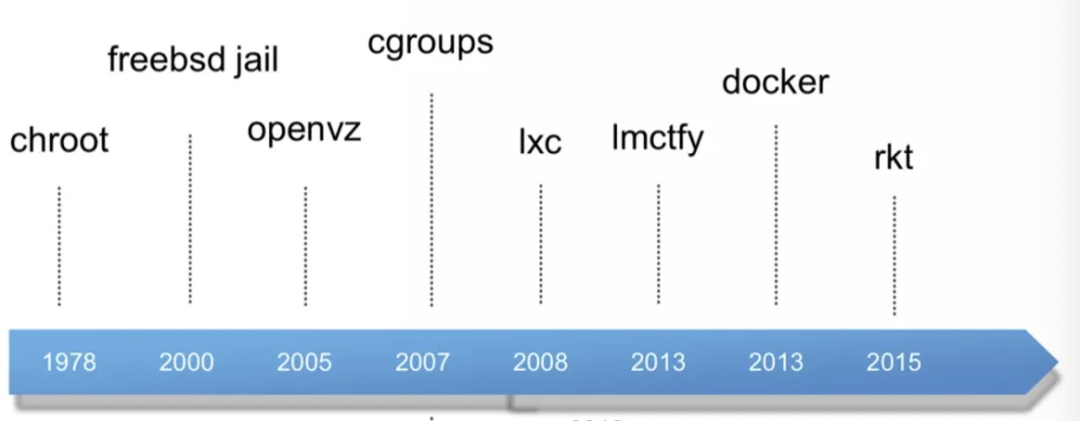
Docker 的 OS 依赖
Docker 构建于操作系统之上,是强依赖于操作系统的虚拟化技术,依赖于Cgroup来管理进程组,依赖于命名空间来实现资源隔离,通过特定的文件系统来使用操作系统自身的文件系统。
Cgroup
Cgroup全称为Linux Control Group,是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。
Cgroup是由Google的工程师在2006年发起的,最早的名称为进程容器(process containers)。在2007年,由于在Linux内核中,容器这个名词有许多不同的意义,进而被重命名为cgroup,并且被合并到2.6.24的内核版本中,后来又添加了很多功能。
Cgroup的主要功能:
限制进程组可以使用的资源数量,例如,可以为进程组设定一个内存使用的上限,一旦进程组使用的内存达到限额再申请内存,就会触发OOM。
进程组的优先级控制,例如,可以使用为某个进程组分配特定的cpu share。
记录进程组使用的资源数量,例如,可以记录某个进程组使用的cpu时间
进程组隔离,例如,可以使不同的进程组使用不同的命名空间,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
进程组控制,例如,将进程组挂起和恢复。
命名空间
Namespace(命名空间) 是 Linux 提供的一种内核级别资源隔离的方法。又称为命名空间,它主要做访问隔离,即同一个命名空间的多个资源(memory, CPU, network, pid)可以相互看到,但是之外的看不到。
目前Linux Namespace 大致有7种,如下表所示:
| 类型 | 系统调用参数 | 隔离资源 |
|---|---|---|
| Mount | CLONE_NEWNS | 系统挂载点 |
| IPC | CLONE_NEWIPC | system V IPC(信号量,消息队列,共享内存等) |
| UTS | CLONE_NEWUTS | 主机名,NIS域名 |
| PID | CLONE_NEWPID | 进程PID |
| Network | CLONE_NEWNET | 网络设备,协议栈,端口 |
| User | CLONE_NEWUSER | 用户和用户组 |
| Cgroup | CLONE_NEWCGROUP | Cgroup 根目录 |
这样, 通过对内核的系统调用,即可实现相应的资源隔离。
多层单一化文件系统
早期的Docker使用AUFS文件系统,是Docker image的基石,可以将分布在不同地方的目录挂载到同一个虚拟文件系统中,只有第一层(第一个文件夹层级)是可写的,其余层是只读的,增加/删除文件时都会转换为写操作写入可写层。AUFS 的 Cow 特性能够允许在多个容器之间共享分层,从而减少物理空间占用。
AUFS本质上仍是堆栈式的联合文件系统。在 Linux启动时,首先加载 bootfs目录,这个目录里面包括 Bootloader和kernel,Bootloader用来加载启动 kernel。当kernel成功加载到内存中后, bootfs就会释放掉, kernel随之开始加载rootfs。rootfs包含的是 Linux系统中标准的 /dev、/proc、/bin、/etc等文件, 是后续kernel启动的基础,因此此时 kernel将 Rootfs加锁,设为 readonly。在只读权限下, kernel进行一系列的检查操作。当kernel确认 rootfs包含的文件正确无误后,将 readonly改为readwrite(可读可写),以后用户就可以按照正确的权限对这些目录进行操作了。
当 Docker虚拟化出来一个容器之后,就相当于有了内存、CPU、硬盘,但没有操作系统。参考 Linux的启动过程,通过 AUFS,将readonly权限的 rootfs添加到 bootfs之上,当rootfs检查完毕之后,再将用户所要使用的文件内容挂载到 rootfs之上,同样是readonly权限。每次挂载一个 FS文件层,每层之间只会挂载增量。这些文件层就是堆栈式文件系统中所保存的数据,AUFS就是用来管理、使用这些文件层的文件系统。
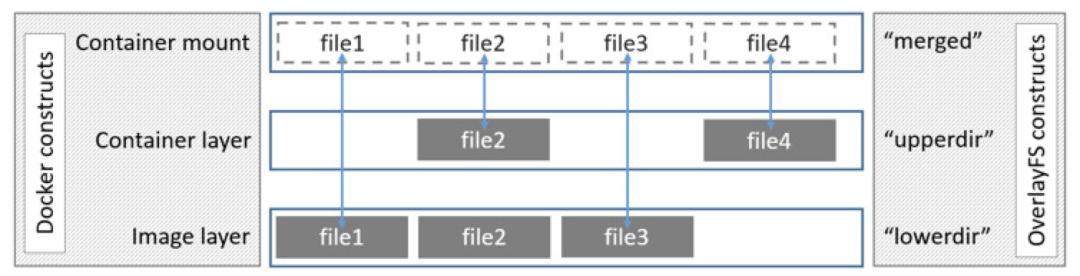
目前,一些Docker开始尝试使用OverlayFS,对比于AUFS,OverlayFS速度更快,实现更简单。OverlayFS也是一种多层单一化的文件系统,它依赖并建立在其它的文件系统之上(例如ext4fs和xfs等等),并不直接参与磁盘空间结构的划分,仅仅将原来底层文件系统中不同的目录进行“合并”,然后向用户呈现,这也就是联合挂载技术。Linux 内核为Docker提供的OverlayFS驱动有两种:overlay和overlay2。而overlay2是相对于overlay的一种改进,在inode利用率方面比overlay更有效。
Docker 的架构模型
目前来说,除了 Linux 系统可以直接运行 Docker之外,其他系统都是基于虚拟机运行的。
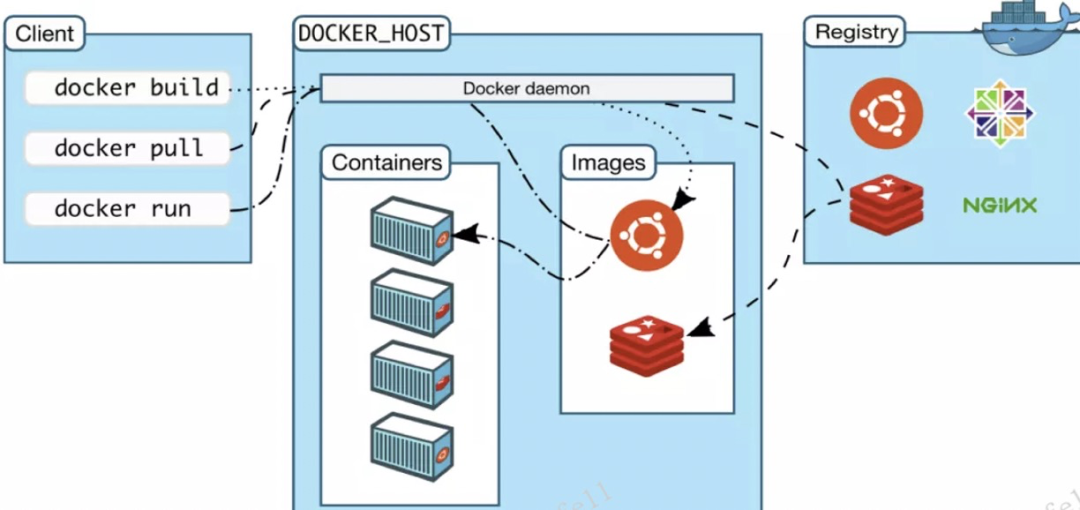
其中,Client是与 Docker 通信的一个组件,也就是客户端。Docker daemon相当于守护进程,也就是 docker 的 Server。Image是镜像,运行起来的镜像就是一个容器。Registry是具体存放镜像的仓库,镜像仓库分为公有仓库(如DockerHub、DockerPool)和私有仓库。有了镜像仓库,用户可以用它来提供上传/下载 镜像的能力,大多数仓库都提供了检索和版本整理能力。
Docker 能够保持容器内部所有的配置和依赖关系始终不变,可以在任何拥有 Docker runtime 的环境快速部署而没有迁移成本,实现了环境的标准化和版本化管理,具有较高的隔离性和安全性。
一句话小结
从操作系统看Docker,Docker 是操作系统能力的抽象重组,或者, 可以看成进程组粒度的可复用内核裁剪,其中以linux 内核中的Cgroup来管理进程组,以命名空间来实现资源隔离,以AUFS或者OverlayFS实现文件系统的挂载,从而,形成了一个通过网络分发的容器环境。
【关联阅读】