
【分享送书】畅快!5000字通俗讲透决策树基本原理
导读
在当今这个人工智能时代,似乎人人都或多或少听过机器学习算法;而在众多机器学习算法中,决策树则无疑是最重要的经典算法之一。这里,称其最重要的经典算法是因为以此为基础,诞生了一大批集成算法,包括Random Forest、Adaboost、GBDT、xgboost,lightgbm,其中xgboost和lightgbm更是当先炙手可热的大赛算法;而又称其为之一,则是出于严谨和低调。实际上,决策树算法也是个人最喜爱的算法之一(另一个是Naive Bayes),不仅出于其算法思想直观易懂(相较于SVM而言,简直好太多),更在于其较好的效果和巧妙的设计。似乎每个算法从业人员都会开一讲决策树专题,那么今天本文也来达成这一目标。

本文着眼讲述经典的3类决策树算法原理,行文框架如下:
决策树分类的基本思想:switch-case
从ID3到C4.5,如何作出最优的决策?
信息熵增益
信息熵增益比
CART树,既可分类又能回归
从信息熵到gini指数
从多叉树到二叉树
从分类树到回归树
决策树算法是机器学习中的一种经典算法,更是很多集成算法的基础。虽说是机器学习,但决策树的基本思想非常符合程序员思维:if-else或者switch-case,即如果满足什么条件则怎么怎么样,否则就另外怎么样。所以,决策树学习的过程就是逐步决策的过程,而决策过程本身则可以绘制成一棵树,当然这里的树是指数据结构与算法中的树。
决策树的基本思想很简单,那么执行决策树的训练过程其实无非就是以下几步:
拿什么做决策——最优决策特征选取
什么时候停止——决策树分裂的终止条件
决策结果如何——最终叶子节点的取值
本文围绕决策树的这3个关键环节展开介绍。
首先进入大众视野的决策树是ID3(Iterative Dichotomiser 3,即第三代迭代二叉树),这里称之为第三代,但似乎不存在所谓的第一代或第二代的前置版本;另外,虽然叫二叉树,但ID3算法生成的决策树确是一个十足的多叉树。那么,ID3算法是基本原理是怎样的呢?
如前所述,构建一颗决策树首先要明确如何做出最优决策,具体到机器学习场景,那么就是从众多潜在的特征中选择一个最优的特征进行分裂。所以,这里的问题进一步等价于如何定义“最优”的特征。
在ID3算法中,引入了信息熵原理来反映特征重要性。这里,信息熵既是一个通信学上的概念,而其中的熵则要追溯到物理学。来源于何处并不重要,关键的是信息熵可以用于表征一个事件的不确定程度。这里不确定程度用通信学的角度讲,就是蕴含的信息量。当然,为了使得机器学习的结果尽可能准确,我们当然是希望能尽可能的通过一个个的特征消除这种不确定性,或者说不希望它有太多的信息量。
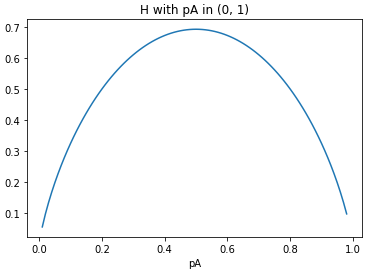
将上述过程进行数学描述,即为:设选取特征F具有K个取值(特征F为离散型特征),则选取特征F参与决策树训练意味着将原来的样本集分裂为K个子集,在每个子集内部独立计算信息熵,进而以特征F分裂后的条件信息熵为:
其中||Fi||为特征F第i个取值的个数,而||F||则为特征F的总数(即样本集总数)。进而,选取特征F训练带来的信息熵增益(即,带来的不确定性降低)可计算为:
所有特征全部用完;
分裂后的样本子集是纯的,即相应分支上的信息熵为0;
达到预定的决策树分裂深度,即最大深度;
分裂后的样本子集数量少于预定叶子节点样本数时;
分裂带来的信息熵增益小于指定增益阈值时
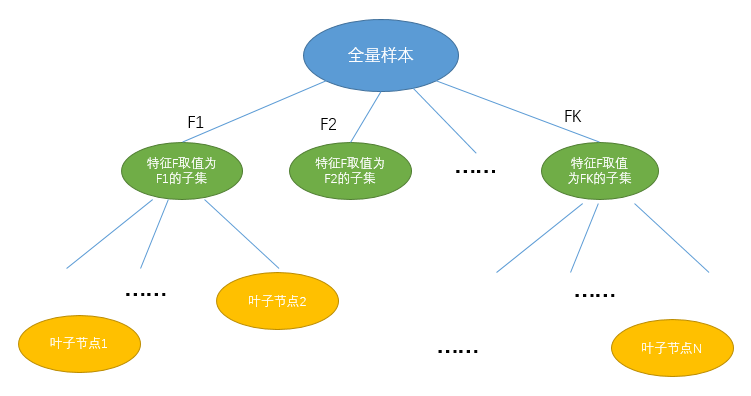
仅支持离散特征,如果是特征连续则首先需要离散化处理;
采用信息熵增益选择最优特征参与训练,在同等条件下,取值种类多的特征比取值种类少的特征更占优势。
针对第二个缺陷,C4.5决策算法给出了解决方案。
2)C4.5决策树算法基本原理
其中,分母部分即为选取特征F自身的信息熵。虽然仅此一处细节改动,但却有效抑制了分裂过程中对取值数目较多特征的偏好,一定程度上保证了决策树训练过程的高效。
另外,C4.5决策树还有其他比较重要的优化设计,例如支持特征缺失值的处理以及增加了剪枝策略等,此处不做展开。
通过以上,我们介绍了决策树的两个经典版本:ID3和C4.5,其中前者作为决策树首个进入大众视野的版本,引入了信息熵原理参与特征的选择和分裂,明确了决策树终止分裂的条件;而C4.5则在ID3的基础上,优化了信息熵增益分裂准则偏好选择取值较多特征的弊端,改用信息熵增益比的准则进行分裂。但同时,C4.5版本决策树仍然存在以下弊端:
仍然仅支持离散特征的训练
生成的决策树是一个多叉树,从计算机的视角来看不如二叉树简单;
无论是信息熵增益还是增益比,都涉及大量的对数计算,计算效率低下;
仍然仅可用于分类任务,对于回归预测无能为力。
对此,一个更高级版本的决策树算法应运而生,CART树,也是当前工业界一直沿用的决策树算法。
特征选取准则由信息熵改用gini指数,并由多叉改为二叉,同时避免了对数运算;
增加MSE准则,用于回归训练任务
可见,从信息熵演变为gini指数是一个自然的迭代思路,但计算效率将会大大提升。这里,补充信息熵与gini指数取值的可视化对比曲线,仍以前述的球赛结果概率为例:
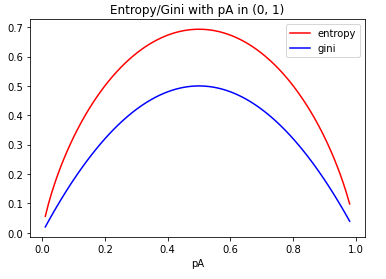
决策树是机器学习中的一个经典算法,主要历经了ID3、C4.5和CART树三大版本,算法原理较为直观易懂,改进迭代的过程也容易理解,尤其是以决策树算法为基础更衍生了众多的集成学习算法。除了本文讲述的基本原理外,决策树的另一大核心就是剪枝策略,这将在后续篇幅中予以阐释。
最后,感谢清华大学出版社为本公众号读者赞助《数据科学实战入门 使用Python和R》一本,截止下周二(3月30日)早9点,公众号后台查看分享最多的前3名读者随机指定一人,中奖读者将在周四或周五推文中公布。
推荐语:本书为没有数据分析和编程经验的读者编写,主题涵盖数据准备、探索性数据分析、准备建模数据、决策树、模型评估、错误分类代价、朴素贝叶斯分类、神经网络、聚类、回归建模、降维和关联规则挖掘。在首先讲解Pyhton和R入门知识的基础上,此后每一章都提供了使用Python和R解决数据科学问题的分步说明和实践演练,读者将一站式学习如何使用Python和R进行数据科学实践。
相关阅读: