
关于决策树,你一定要知道的知识点!(文末送书)
在现实生活中,我们每天都会面对各种抉择,例如根据商品的特征和价格决定是否购买。
不同于逻辑回归把所有因素加权求和然后通过Sigmoid函数转换成概率进行决策,我们会依次判断各个特征是否满足预设条件,得到最终的决策结果。例如,在购物时,我们会依次判断价格、品牌、口碑等是否满足要求,从而决定是否购买。
决策的流程,如图1所示。
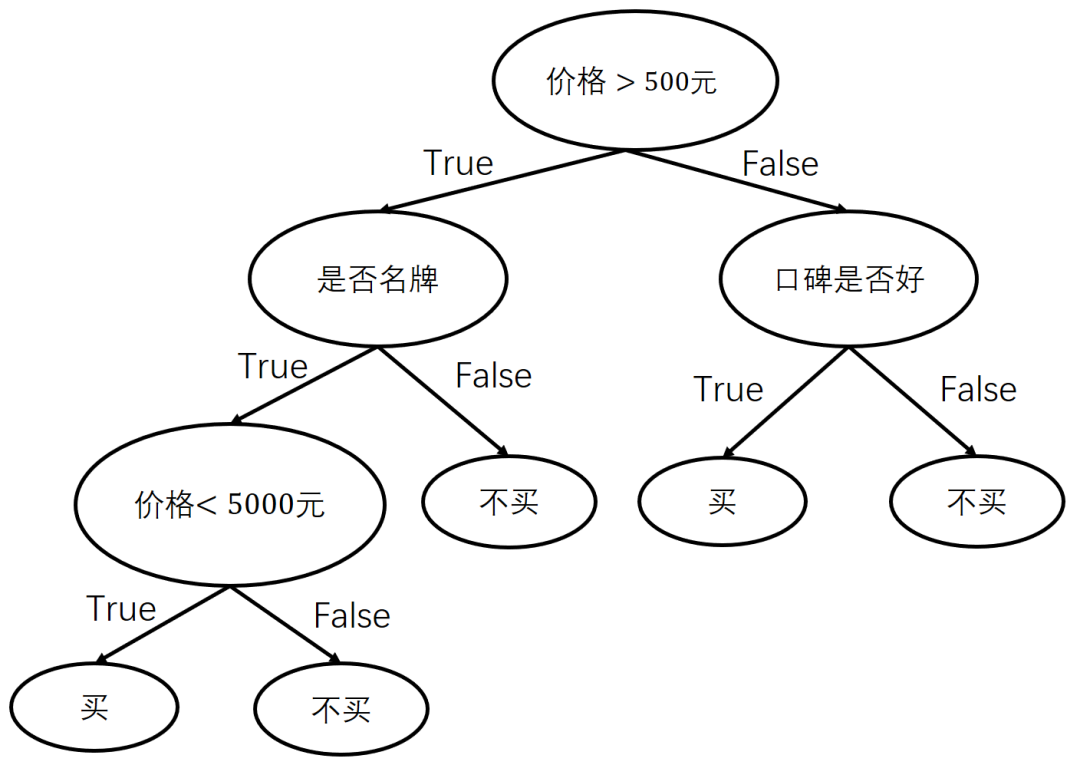
图1
可以看到,决策过程组成了一棵树,这棵树就称为决策树。
在决策树中,非叶子节点选择一个特征进行决策,这个特征称为决策点,叶子节点则表示最终的决策结果。
在上例中,我们只是根据经验主观建立了一棵决策树,这棵决策树在数据量和特征维度较小且逻辑简单时是可以使用的。
然而,在数据量和特征维度较大时,仅凭主观观察建立决策树显然是不可行的。在实际应用中,训练集中的样本往往有上万个,样本的特征通常有上百维,该怎么处理呢?
在实际建立决策树的过程中,每次选择特征都有一套科学的方法。下面就详细讲解如何科学地建立决策树。
不难发现,建立决策树的关键在于选取决策点时使用的判断条件是否合理。每个决策点都要有区分类别的能力。例如,在电商场景中,将发货的快递公司作为决策点的选取条件就是一个很差的选择,其原因在于快递公司和购买行为没有必然联系,而将商品价格作为决策点的选取条件就是合理的,毕竟大部分消费者对商品价格比较敏感。
一个好的决策点可以把所有数据(例如商品)分为两部分(左子树和右子树),各部分数据所对应的类别应尽可能相同(例如购买或不购买),即两棵子树中的数据类别应尽可能“纯”(这种决策点有较高的区分度)。
和逻辑回归类似,用已知数据(例如用户的购买记录、商品信息)求解决策树的形状和每个决策点使用的划分条件,就是决策树的训练过程。
首先看一下如何量化数据的纯度。假设在一组数据中有P和N两类样本,它们的数量分别为

N类样本出现的概率为
我们可以直观地发现:当数据只有一个类别( )时,数据最混乱。
可以使用基尼(Gini)系数来量化数据的混乱程度。基尼系数的计算公式如下。
可见,基尼系数越小,数据就越纯(
基尼系数和概率

图2
决策树有一些常用的构建方法,在这里我们详细讲解一下最为流行的CART树。
CART树是一棵二叉树,它不仅能完成分类任务,还能完成数值预测类的回归任务。
下面先介绍分类树,再介绍回归树。在构建CART树时,可以使用基尼系数来度量决策条件的合理性。
假设有 。和逻辑回归中特征 ),也可以从集合中“多选一”(例如学历, )。
决策树的构建(训练)过程是一个不断生成决策点的过程,每次生成的决策点都要尽可能把训练样本中的两类数据分开。
例如, ,将训练数据分成两类(如果某个样本在划分条件上有特征缺失,就随机分配该样本),如图3所示。
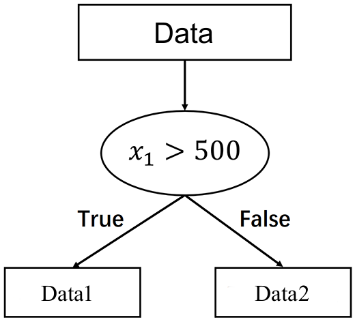
图3
Gini1就越小。同理, 。
此次划分的基尼系数为
若 ”作为划分条件,将数据划分为“ ”“ ”两部分,并计算基尼系数 。
遍历所有维度( )中可能的划分条件,对每种划分方法均可计算相应的基尼系数,例如 、 、 、 、 、 。以最小基尼系数所对应的特征和划分条件为决策点,数据将被划分为两堆。
但是,决策树是不停生长的,仅划分一次是不够的,需要再使用同样的方法对每个子堆(Data 1、Data 2)进行划分,最终生成CART树,步骤如下。
算法的输入为训练集 、基尼系数的阈值、样本数量的阈值,输出为决策树 。算法从根节点开始,用训练集递归建立CART树。
1. 当前节点的数据集为
。如果样本数量小于阈值、基尼系数小于阈值或没有特征,则返回决策子树,当前节点停止递归。 2. 在当前节点的数据上计算各个特征的各个划分条件对划分后的数据的基尼系数。当维度过高且每维所对应的可取值比较多时(例如,价格的值为
3. 在计算出来的各个特征的各个特征值对数据集
的基尼系数中,选择基尼系数最小的特征 和对应的划分条件,例如“ ”。通过划分条件把数据集划分成 和 两部分,同时分别建立当前节点的左节点和右节点,左节点的数据集为 ,右节点的数据集为 。 4. 对
和 递归调用以上步骤,生成决策树。
这就是决策树的训练过程。
在第1步中,判断样本数量和基尼系数是为了控制生成的决策树的深度,避免不停地递归。不停地递归会导致划分条件过细,从而造成过拟合。
决策树建立后,每个叶子节点里都有一堆数据。可以将这堆数据的类别比例作为叶子节点的输出。
决策树在复杂度上和其他模型有所不同。例如,在逻辑回归中,当特征维度不变时,模型的复杂度就确定了。但是,在决策树中,模型会根据训练数据不断分裂,决策树越深,模型就越复杂。
可以看出,数据决定了决策树的复杂度,且当数据本身线性不可分时,决策树会非常深,模型会非常复杂。
所以,在决策树中,需要设置终止条件,以防模型被数据带到极端复杂的情况中。在决策树中,终止条件的严格程度相当于逻辑回归中正则项的强度。
训练完成后,我们可以得到一棵决策树,如图4所示。
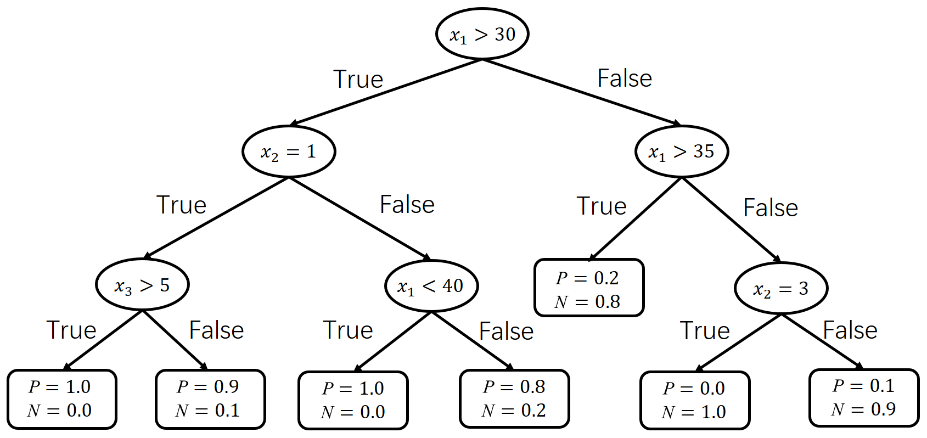
图4
在使用决策树时,用数据 。决策树对输入
决策树理解起来比较简单,其本质就是以基尼系数来量化划分条件的分类效果,自动探寻最佳划分条件。
下面我们把决策树和逻辑回归进行对比。为了方便对比,假设决策树的特征为2维且均为连续特征。决策树的分类效果图可以理解为如图5所示的形式。
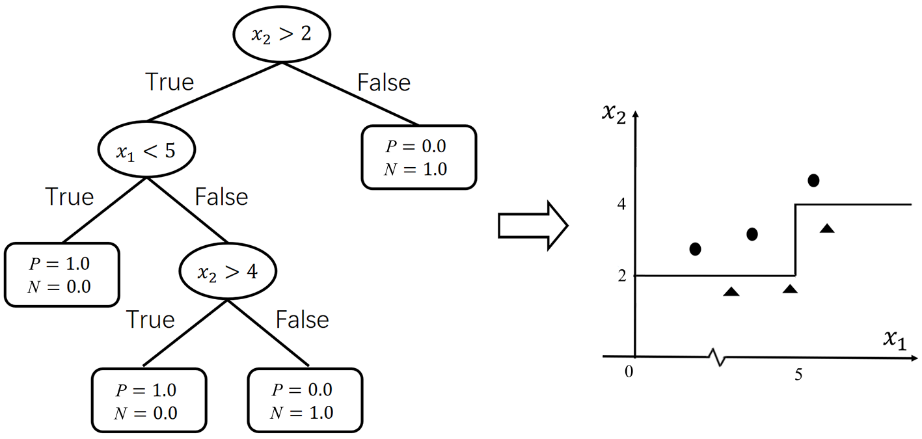
图5
可见,决策树分类的几何意义和逻辑回归一样,都是在平面上画直线。相比逻辑回归的分类线是一条直线,决策树的分类线是平面上与坐标轴平行的多条直线(一个判断条件对应于一条直线,这些直线共同组成了分类线)。多条直线可以组合成非线性的形式,以处理线性不可分的情况,如图6所示。
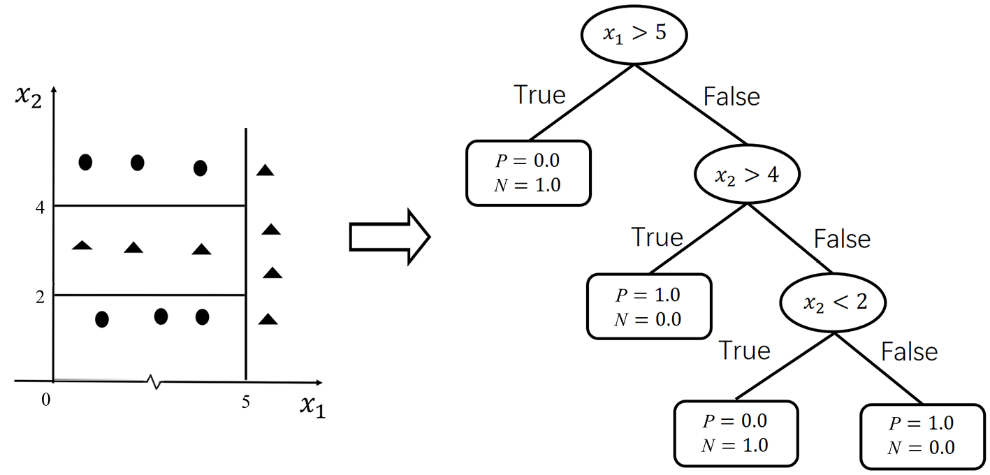
图6
虽然决策树在训练时需要遍历所有可能的类别划分方法,速度比较慢,但是在预测阶段,决策树只需进行一些逻辑判断和比较,速度非常快,故适合在对时间要求较高的场景中使用。
决策树不仅可以用在分类中,还可以用在回归中(预测连续的值而非类别概率)。用在分类中的决策树称为分类树,用在回归的中决策树称为回归树。在回归任务中,学习目标不再是分类,而是一个连续值
例如,当 中有
如果
同理,可以求出 。
对于划分条件
回归树除了使用方差代替基尼系数来度量数据的纯度,其他均与分类树一致,叶子节点输出的值为该节点所有样本目标值的平均值。
本文摘自《速通机器学习》一书!


▊《速通机器学习》
卢菁 著
轻松有趣的机器学习知识点读本
通过14个轻松有趣的专题,帮助初学者掌握机器学习的相关概念,帮助求职者快速梳理和回顾机器学习知识
本书从传统的机器学习,如线性回归、逻辑回归、朴素贝叶斯、支持向量机、集成学习,到前沿的深度学习和神经网络,如DNN、CNN、BERT、ResNet等,对人工智能技术进行零基础讲解,内容涵盖数学原理、公式推导、图表展示、企业应用案例。
本书面向初中级读者,能帮助读者迅速掌握机器学习技术的相关概念及原理。本书内容结合作者多年的科研工作经验,理论和实践并重,对科研、学习、面试等均有帮助。
 福利来了
福利来了