霸榜多个CV任务,开源仅两天,微软分层ViT模型收获近2k star
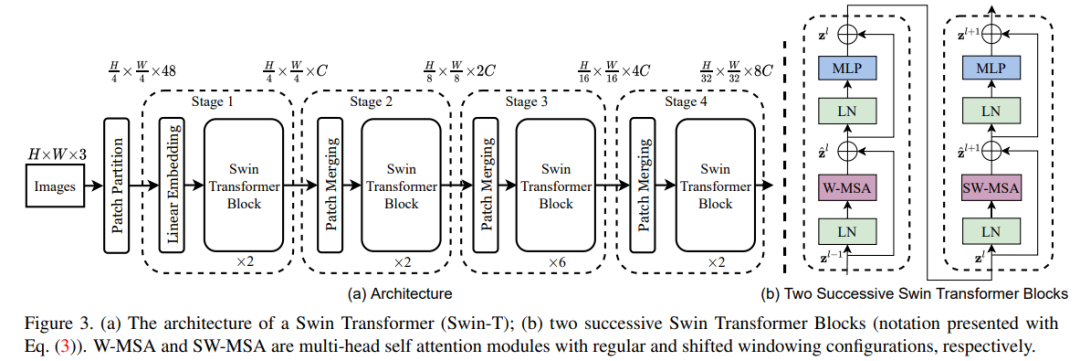
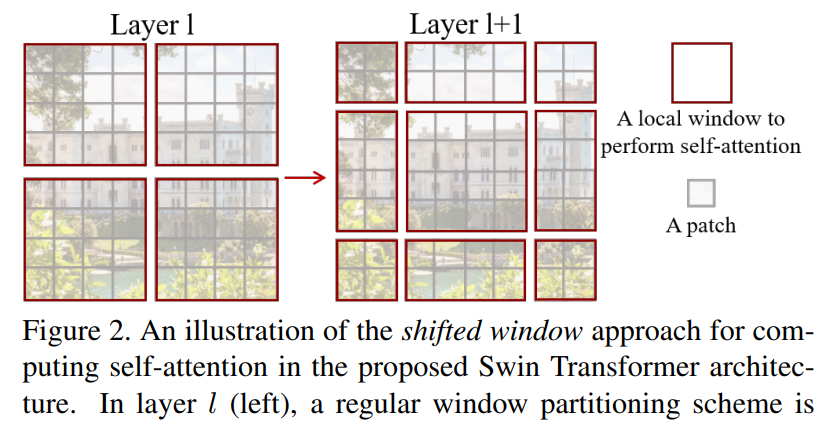
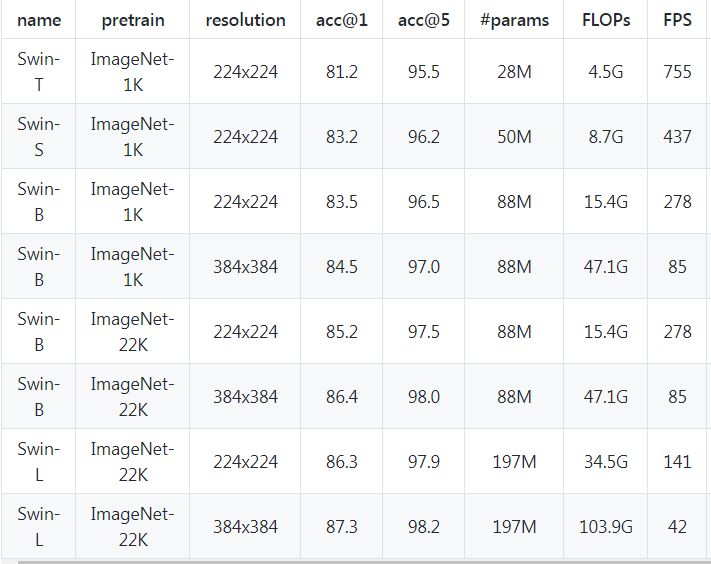
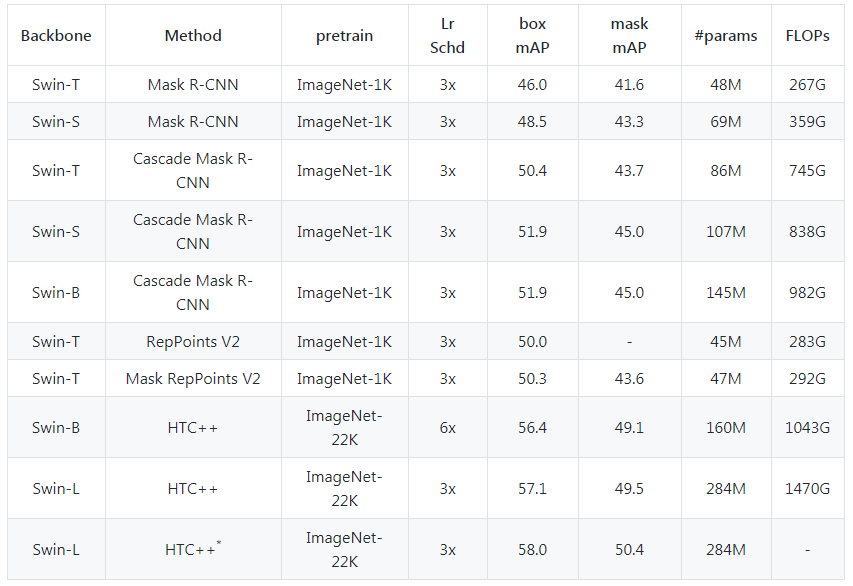
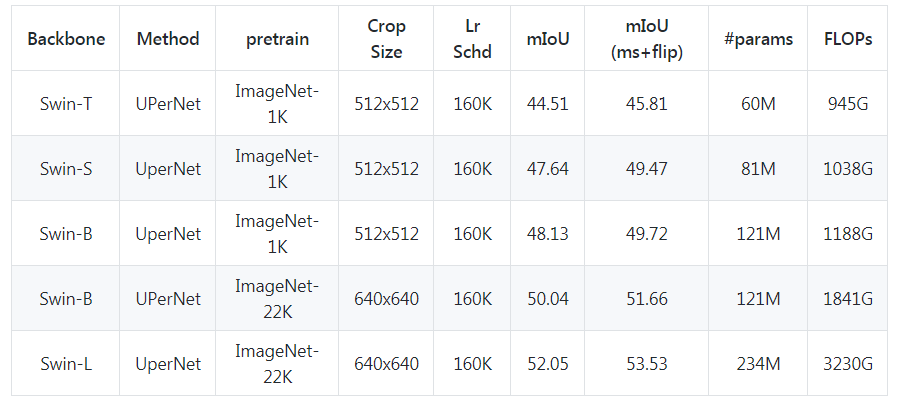
屠榜各大 CV 任务的微软 Swin Transformer,近日开源了代码和预训练模型。


© THE END
转载请联系 机器之心 公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP屠榜各大 CV 任务的微软 Swin Transformer,近日开源了代码和预训练模型。
© THE END
转载请联系 机器之心 公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!