
一文总结微软研究院Transformer霸榜模型三部曲!
【导读】本文将主要介绍微软研究院提出的三大Transformer霸榜模型,分别是:开创Transforer新时代的Swin Transformer, 进阶版的Swin Transformer -- CSwin Transformer, 全新霸榜Transformer架构-- Fcoal Self-attention。这三篇Transformer霸榜模型可谓层层递进,论文研究思路和方法很值得大家学习!下面通过对这三篇论文的进一步分析,来深刻体会一下微软大佬们是如何提出科研idea以及如何改进的!Transformer yyds!
三大霸榜模型的Motivation
1. Swin Transformer
Motivation: 由于CV和NLP任务涉及到的尺度变化不同,通常在NLP任务中的物体scale是标准固定的,而CV任务中的物体尺度变化范围非常大。因此,CV任务比NLP需要更大的分辨率,又因为Transformer是一种基于全局自注意力的计算方式,它的计算复杂度与图像尺度之间呈平方增长关系,这就会导致计算量过于庞大。
为了解决上述问题,Swin Transformer提出了以下两点解决方案:
引入 CNN 中常用的层次化堆叠方式(即金字塔结构)构建分层 Transformer; 引入局部性(locality)思想,对不重叠的窗口区域内进行自注意力计算。因此,相比于传统的ViT,Swin Transfomer的计算复杂度大幅度降低,计算复杂度与输入图像大小呈线性关系。而且Swin Transformer可以随着网络深度加深,逐渐合并图像块来构建层次化Transformer。最后,Swin Transformer的成功恰恰说明了vision transformer在dense prediction任务上的优势(model long-range dependencies)
一句话总结:Swin Transformer首次结合了层级结构以及Locality的思想,首次实现Transformer霸榜多个CV任务,是一种通用性的视觉网络架构,为后面的Transformer一系列的发展起到了很好的基石作用。
2. CSWin Transformer(cross-shape window)是swin Transformer的改进版
主要的motivation为:由于Transformer 中的全局自注意力的计算成本非常高,而且局部自注意力通常也会限制每个token的交互区域。
为了解决上述问题,CSWin提出了一种十字形的滑动窗口来做self-attention,它不仅计算效率非常高,而且能够通过两层计算就可以获得全局的感受野。除此之外,CSWin Transformer还提出了新的position encoding方法:LePE,进一步提高了模型的准确率。在保持跟SwinT相同计算量下,可以提升2个点左右,最终在ADE20k 语义分割数据集上刷到55.2 mIOU!
一句话总结:在减少全局自注意力计算成本的同时,在全局自注意力计算过程中建立了一种更有效的信息交互方式,即十字形滑动窗口模式.
3. Focal Self-attention:
Motivation: Transformer结构在CV和NLP领域都展现出了潜力。相比于CNN,Transformer结构最大的不同就是它的Self-Attention(SA)模块能够进行对全局信息进行建模从而实现内容上的交互(global content-dependent interaction),通过这种方式,Transformer便能够捕获long-range和local-range的依赖关系。但是,SA的计算复杂度与输入数据的大小呈平方关系,计算开销就会很大。因此,在控制一定计算成本的前提下,为了更有效地捕获局部细粒度信息和全局粗粒度信息。本文提出了Focal Self-Attention(FSA),针对每个token以细粒度的方式关注周围较近的token,以粗粒度的方式关注相对较远的token,以此来更有效的捕获和建模short-range和long-range之间的依赖关系。
一句话总结:利用Focal Self-Attention的方式,有效地对局部信息和全局信息之间的依赖关系进行了建模,在全局粗粒度信息与局部细粒度信息间形成了一种良好的交互。(这个过程中,其实增加了一些计算成本!)
网络结构对比
1. Swin Transformer:首次利用Transformer霸榜多个CV任务,实现对CNN的降维打击

论文地址:https://arxiv.org/abs/2103.14030 代码地址:https://github.com/microsoft/Swin-Transformer 

Swin Transformer设计的分层结构如上图所示,网络包括一个patch partition和4个stage:
(1)patch partition:输入图片HxWx3划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4;
(2)stage1:首先是一个patch embedding操作,然后通过一个linear embedding层将划分后的patch特征维度变成C,然后送入Swin Transformer Block.
(3)stage2-stage4,,首先都先有一个patch merging:将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了,特征维度就变成了4C.
(4)每个stage包含相同配置的transformer blocks,stage1到stage4的特征图分辨率分别是原图的1/4, 1/8,1/16,1/32。并且Swin Transformer随着网络深度的加深patch数量会逐渐减少,但是每个patch的感知范围会扩大,这个设计是为了方便Swin Transformer的层级构建,并且能够适应视觉任务的多尺度,比如基于FPN的dense prediction任务。
(5)最后对所有的patch embeddings求平均,即CNN中常用的global average pooling,然后送入一个linear classifier进行分类。
此外,一个Swin Transformer Block由一个带两层MLP的shifted window based MSA组成。在每个MSA模块和每个MLP之前使用LayerNorm(LN)层,并在每个MSA和MLP之后使用残差连接。
2. CSWin Transformer(Swin Transformer的进阶版):一种十字架形注意力的Transformer

论文地址:https://arxiv.org/abs/2107.00652 代码地址:暂未开源
 CSWin Transformer整体结构如上图所示。首先将维度为HxWx3的图片送入CSwin Transformer,先用一个kernel size 为7x7, stride为4的卷积进行下采样(此外,相比SwinT,这里把patchify stem替换成了convolutional stem),FAIR的最新论文Convolutional stem is all you need! 恰好探讨了引起ViT优化不稳定的原因,其中用convoluational stem替换patchify stem后,大约使用5个convolution就可以在SGD优化器上优化,精度不会大幅度下降,并且对于learning rate和weight decay参数不敏感,训练的收敛速度更快。因此,这里不约而同的采取类似操作,大佬们真可谓是惺惺相惜,心心相印呀!(哈哈!)
CSWin Transformer整体结构如上图所示。首先将维度为HxWx3的图片送入CSwin Transformer,先用一个kernel size 为7x7, stride为4的卷积进行下采样(此外,相比SwinT,这里把patchify stem替换成了convolutional stem),FAIR的最新论文Convolutional stem is all you need! 恰好探讨了引起ViT优化不稳定的原因,其中用convoluational stem替换patchify stem后,大约使用5个convolution就可以在SGD优化器上优化,精度不会大幅度下降,并且对于learning rate和weight decay参数不敏感,训练的收敛速度更快。因此,这里不约而同的采取类似操作,大佬们真可谓是惺惺相惜,心心相印呀!(哈哈!)
与此同时,前几天华为诺亚方舟提出的CMT也是将CNN与Transformer进行结合,其中选择将convoluational stem替换patchify stem!(Transformer回归CNN )
)
Stage模块后续所有操作,只是把Transformer Block替换成了CSwin Transformer Block。并且,在每个stage之间的downsample,从merge patch替换成了kernel size为3x3步长为2的卷积(即CNN的下采样操作)
CSWin Transformer Block的结构如右图所示。由两个LN,一个MLP和Cross-Shaped Window Self-Attention组成,还有两个skip connection连接。
1. Cross-Shaped Window Self-Attention
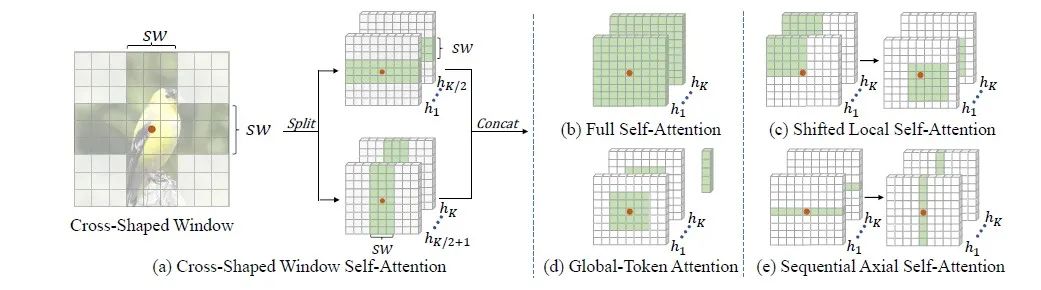
红色点表示query,绿色区域表示key,图(b)是一个query点和global区域的key做相关性计算,图(c)是一个query点和local区域的key做相关性计算,通过串联shifted local区域关联更多的区域,图(d)一个query点和local区域的key做相关性计算,图(e)一个query点和横向区域的key做相关性计算,通过串联纵向区域关联更多的区域。不同于之前的设计,cross-shaped window self-attention将multi-head平均split成两个部分,一部分做横条纹self-attention,另一部分做纵条纹self-attention,然后将输出进行concat。例如图(a),维度为HxWxC的feature map同linearly projected到K个head(每个head的feature map通道数为C/K),然后平均split成两部分,一部分是到,另一部分是到,假设条纹的宽度为sw,将每个head的feature map根据sw划分成不重叠的横条纹(或者纵条纹),记作,其中,并行计算出所有横纵条纹的self-attention,最后将输出concat起来。CSWin Self-Attention随着stage的加深,增加sw宽度来关联更多的区域。
2. Locally-Enhanced Positional Encoding
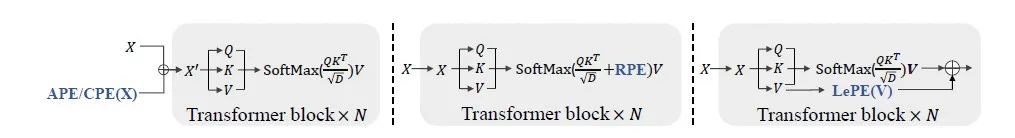
因为self-attention是没有位置信息的,之前的vision transoformer通过引入positional encoding来得到位置信息。比如APE和CPE直接将位置信息添加到self-attention的input token,然后送入vision transformer中,RPE直接将位置信息嵌入到transformer block的相关性计算中,本文提出的LePE直接通过深度卷积学习出value的位置信息,用残差的方式相加,非常方便的嵌入到transformer block中,公式如下:
3. 超越Swin,CSwin,微软推出新作:Focal Self-attention for Local-Global Interactions in Vision Transformers再度霸榜三大视觉任务!

论文地址:https://arxiv.org/abs/2107.00641 代码地址:暂未开源

 本文的模型结构如上图所示,首先将图片分成4x4的patch。然后进入Patch Embedding层,Patch Embedding层为卷积核和步长都为4的卷积。在进入N个Focal Transformer层,在每个stage中,特征的大小减半,通道维度变为原来的两倍。对于图像分类任务,我们取最后一阶段输出结果的平均值,然后将其发送到分类层。对于目标检测,最后3个或所有4个阶段的特征映射被送入检测器头部,模型大小可以通过改变输入特征维数d和每一阶段Focal Transformer 层数来设置。
本文的模型结构如上图所示,首先将图片分成4x4的patch。然后进入Patch Embedding层,Patch Embedding层为卷积核和步长都为4的卷积。在进入N个Focal Transformer层,在每个stage中,特征的大小减半,通道维度变为原来的两倍。对于图像分类任务,我们取最后一阶段输出结果的平均值,然后将其发送到分类层。对于目标检测,最后3个或所有4个阶段的特征映射被送入检测器头部,模型大小可以通过改变输入特征维数d和每一阶段Focal Transformer 层数来设置。
由于,标准的自注意力可以捕获short-range和long-range级别的细粒度信息并进行交互,但是,在处理高分辨率的物体上,它的计算成本较高。因此。本文提出了Focal self-attention,每个标记以细粒度关注最近的周围标记,但以粗粒度关注远离的标记,利用这种方式可以高效且有效地捕获short-range和long-range的视觉依赖关系.
 如上图所示,这是focal self-attention在每个窗口操作的示例。每一个最精细的方形单元格都代表一个视觉标记,要么来自原始特征图,要么来自压缩后的特征图。假设我们有一个大小为的输入特征映射。我们首先将它划分为 的windows,每个窗口大小为。以中间的蓝色窗口作为query,我们在多个不同细粒度级别上提取其周边标记作为key和value。在第一层中,我们提取了最接近蓝色窗口的令牌。然后在第二层,我们扩展了关注区域,并将周围的大小的子窗口集合起来,从而得到集合令牌。在第三个层次上,我们参加更大的区域,包括整个特性图和池个子窗口。最后,将这三个级别的令牌连接起来,计算蓝色窗口中的个令牌(查询)的键和值。
如上图所示,这是focal self-attention在每个窗口操作的示例。每一个最精细的方形单元格都代表一个视觉标记,要么来自原始特征图,要么来自压缩后的特征图。假设我们有一个大小为的输入特征映射。我们首先将它划分为 的windows,每个窗口大小为。以中间的蓝色窗口作为query,我们在多个不同细粒度级别上提取其周边标记作为key和value。在第一层中,我们提取了最接近蓝色窗口的令牌。然后在第二层,我们扩展了关注区域,并将周围的大小的子窗口集合起来,从而得到集合令牌。在第三个层次上,我们参加更大的区域,包括整个特性图和池个子窗口。最后,将这三个级别的令牌连接起来,计算蓝色窗口中的个令牌(查询)的键和值。
Window-wise attention
Focal Self-Attention的结构如上图所示,首先定义三个名词:
Focal levels :可以表示FSA中对特征关注的细粒度程度。level L的下标越小,对特征关注也就越精细。 Focal window size :作者将token划分成了多个sub-window,focal window size指的是每个sub-window的大小。 Focal region size :focal region size是横向和纵向的sub-window数量。
Sub-window pooling功能:这一步的作用是用来聚合信息的,因为前面也说到了,Self-Attention是对所有的token信息都进行细粒度的关注,导致计算量非常大。所以作者就想到,能不能只对query token周围的信息进行细粒度关注,远离的query token的信息进行粗粒度的关注。那么,如何来表示这个粗粒度呢,作者就提出了sub-window pooling这个方法,将多个token的信息进行聚合,以此来减少计算量。那么,聚合的token数越多,后期attention计算需要的计算量也就越小,当然,关注的程度也就更加粗粒度。
计算流程:每个focal level中,首先将token划分成多个的sub-window,然后用一个线性层进行pooling操作:
pooling后的特征提供了细粒度或者粗粒度的信息。比如,level 1的,所以pooling并没有对特征进行降采样,所以处理之后的特征是细粒度的;同理level 2和level 3,特征分别缩小到了原来的1/2和1/4,因此越远离query token的特征,信息表示就越是粗粒度的。此外,由于通常是比较小的,所以这一步的参数几乎是可以忽略不计的。
Attention computation功能:在上一步中,我们用sub-window pooling进行了信息聚合操作,以此来获得不同细粒度的特征。接下来,我们就需要对这些不同细粒度的信息进行attention的计算。具体的步骤其实和标准的Self-Attention很像,主要不同之处有两点1)引入了相对位置编码,来获取相对位置信息;2)每个query和所有细粒度的key和value都进行了attention的计算,因此本文方法的计算量其实还是不算小的。计算流程:经过sub-window pooling之后,就获得不同细粒度和感受野的特征表示。接下来这一步,我们需要对local和global的特征进行attention计算。首先,我们通过三个线性层计算当前level的Q和所有level的K、V:
接着,我们将当前level的Q和所有level的K、V进行带相对位置编码的Self-Attention
这里:
模型复杂度分析
1. Swin Transformer的模型复杂度:
Window Attention
window attention可用来来降低计算量,首先将特征图分成互不重叠的window,每个window包含相邻的个patchs,每个window内部单独做self-attention,这可看成是一种local attention方法。对于一个包含个patchs的图像来说,基于window的attention方法(W-MSA)和原始的MSA计算复杂度对比如下:
进一步,由于window attention是一种local attention,每个stage采用相同的window attention,那么信息交换只存在每个window内部。用CNN的话语说,那么感受野是没有发生变化的,此时只有当进入下一个stage后,感受野才增大2倍。论文中提出的解决方案是采用shifted window来建立windows间的信息交互。具体如下图所示:
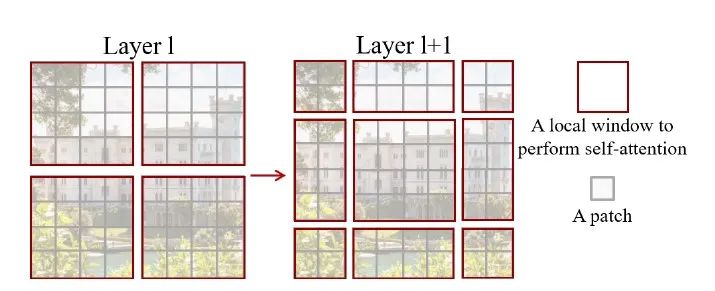
上图中红色区域是window,灰色区域是patch。W-MSA将输入图片划分成不重合的windows,然后在不同的window内进行self-attention计算。假设一个图片有hxw的patches,每个window包含MxM个patches,复杂度计算如下:
, 需要 ,计算需要 ,与V相乘需要,然后得到的需要乘以需要,所以MSA总共需要:而在Windows内做Self-attention,计算需要个windows且每个复杂度为,那么总共计算复杂度为:,同理与 相乘需要,所以W-MSA总共需要
2. CSwin Transformer模型复杂度:
自我注意力计算公式如下:
4个linear projection需要 ,横条纹的self-attention的需要 ,与V相乘需要,纵条纹同理,需要 ,与V相乘需要 。
总的复杂度为:
由于横纵两个方向的并行计算和sw宽度的灵活性,CSWin Transformer可以在不增加计算量的情况下,大幅度提升精度。
3. Fcoal Self-attention 模型复杂度:
对于输入特征图,在focal level 1我们有大小的sub-windows, pooling 操作如上计算得到复杂度为:,进而整个sub-windows的复杂度为:,最后对于整个focal level层,总计的复杂度为:,它是独立于每个Focal level子窗口大小。
对于注意力部分,对于一个query 大小的window,它的复杂度为,则对于整个feature map复杂度就变为:,因此最终Focal self-attention的计算复杂度为:,特别当时,我们可以使得这一层中的所有query(包括边缘query和中心点query)都有全局感受野。
总结
Swin Transformer的最大贡献是提出了一个可以广泛应用到所有计算机视觉领域的backbone,并且大多数在CNN网络中常见的超参数在Swin Transformer中也是可以人工调整的,例如可以调整的网络块数,每一块的层数,输入图像的大小等等。该网络架构的设计非常巧妙,是一个非常精彩的将Transformer应用到图像领域的结构,值得每个AI领域的人前去学习!
CSwin Transformer则是Swin Transformer的进阶!主要创新点在于:提出了一种“Cross-Shaped Windows”计算自注意力的方式,在形成十字形窗口的水平和垂直条纹中并行计算自注意力,每个条纹通过将输入特征分成相等的条纹获得宽度。(其实在CVPR2019年的CCNet[1]就提出过的类似的思想。感兴趣的朋友可以去看看)
Focal self-attention,主要提出了一种如何将局部细粒度信息和全局粗粒度信息进行有效交互的新机制。即:以细粒度的方式关注离自己近的token,以粗粒度的方式关注离自己远的token,从而高效且有效地捕获short-range和long-range之间的视觉依赖关系。但是FSA引入了额外的显存占用和计算量,因此虽然性能上得到了不错的提升,但是对于高分辨率图像的预测任务,依旧不是非常友好。这是继VOLO、CoAtNet之后又一篇在局部信息建模上做出来的文章,这也说明了局部信息建模对于图像理解任务是非常重要的。
参考链接
Huang, Zilong, et al. "Ccnet: Criss-cross attention for semantic segmentation." https://zhuanlan.zhihu.com/p/386502255 https://zhuanlan.zhihu.com/p/360513527 https://zhuanlan.zhihu.com/p/387746569