
再见 Seaborn!Altair 数据可视化已超神
数据可视化对于通过将数据转换为视觉效果来揭示数据中隐藏的趋势和模式非常重要。为了可视化任何形式的数据,我们都可能在某个时间点使用过数据透视表和图表,如条形图、直方图、饼图、散点图、折线图、基于地图的图表等。这些很容易理解并帮助我们传达准确的信息。基于详细的数据分析,我们可以决定如何最好地利用手头的数据,帮助我们做出明智的决定。
如果你是数据科学或机器学习初学者,你肯定已经尝试过 Matplotlib 和 Seaborn 来进行数据可视化。毫无疑问,他们都是用于数据分析的两个最常用的强大的开源 Python 数据可视化库。
Seaborn 和 Altair
Seaborn 基于 Matplotlib,并为构建信息统计可视化提供了一个高级接口。但是,有一种替代 Seaborn 的方法。这个库被称为Altair,这是一个为统计数据可视化而构建的开源 Python 库。根据官方文档(https://altair-viz.github.io/),它基于 Vega 和 Vega-lite 语言。使用 Altair,我们可以通过类似于 Seaborn 图的条形图、直方图、散点图和气泡图、网格图和误差图等创建交互式数据可视化。

虽然 Matplotlib 库在语法风格上是命令式的,但 Altair 和 Seaborn 库在方法上都是声明式的,即用户只需要指定要做什么,机器决定它的部分。这使用户可以自由地专注于解释数据,而不是忙于编写正确的语法。这种声明式方法的唯一缺点可能是用户对自定义可视化的控制较少,这对于大多数不熟悉编码部分的用户来说是可以的。
在本文中,我们将 Seaborn 与 Altair 进行比较。为了进行比较,我们将使用这两个库创建相同的可视化集,并得出结论,在易用性、语法、可视化外观和样式以及自定义可视化的能力方面,一个库是否比另一个具有明显优势。本文完整数据和代码,可联系原文作者云朵君获取!
安装 Seaborn 和 Altair
要从 PyPi 安装这些库,请使用以下命令
pip install altair
pip install seaborn
报错与处理
如果你使用的是 Jupyter Notebook,并且首次运行,有如下错误
Error loading script: Script error for "vega-embed" http://requirejs.org/docs/errors.html#scripterror
这就涉及到在 Jupyter Notebook 中显示的问题
经典的 Jupyter Notebook 将通过实时网络连接与 Altair 的默认渲染器一起使用:不需要渲染启用步骤,或者,对于 Jupyter Notebook 中的离线渲染,可以使用 Notebook 渲染器:
alt.renderers.enable('notebook')
如果报错:
NoSuchEntryPoint: No 'notebook' entry point found in group 'altair.vegalite.v4.renderer'
则需要安装:
pip install vega
或者conda中
conda install vega --channel conda-forge
在旧版本的笔记本 (<5.3) 中,需要额外启用扩展:
jupyter nbextension install --sys-prefix --py vega
如果以上方法还不管用(如果你也遇到了同样的问题,并且有了更好的解决方案的,可以联系云朵君,一起学习),那就建议你使用 Jupyter Lab,并设置:
import altair as alt
alt.renderers.enable('mimetype')
正常显示就没有问题了。
导入基本库和数据集
与往常一样,我们导入 Pandas 和 NumPy 库来处理数据集、Matplotlib 和 Seaborn,以及用于构建可视化的新安装库 Altair。
#导入需要的库
import pandas as pd
import numpy as np
import seaborn as sns
Import matplotlib.pyplot as plt
import altair as alt
我们将使用来自 seaborn 数据集库的“mpg”或“miles per gallon”数据集来生成这些不同的图。这个著名的数据集包含各种品牌汽车模型的 398 个样本和 9 个属性。
#导入数据集
df = sns.load_dataset('mpg')
df.shape
>>>(398, 9)
#数据集列名
df.keys()
输出
Index(['mpg', 'cylinders', ‘displacement', ‘horsepower', ‘weight',
'acceleration', ‘model_year', ‘origin', 'name'],
dtype='object')
#检查数据类型
df.dtypes
#检查数据集
df.head()

这个数据集很简单,很好地融合了分类和数字特征。现在绘制图表进行比较。
散点图和气泡图
我们将从简单的散点图和气泡图开始。我们将使用'mpg'和'horsepower'变量。
Seaborn
对于 Seaborn 散点图,可以使用 relplot 命令并将“散点图”作为绘图类型传递
sns.relplot(y='mpg',x='horsepower',data=df,
kind='scatter',size='displacement',
hue='origin',aspect=1.2);
或者可以直接使用 scatterplot 命令。
sns.scatterplot(data=df, x="horsepower", y="mpg",
size="displacement", hue='origin',
legend=True)
Altair
而对于 Altair,使用以下语法
alt.Chart(df).mark_point().encode(alt.Y('mpg'),
alt.X('horsepower'),
alt.Color('origin'),
alt.OpacityValue(0.7),
size='displacement')
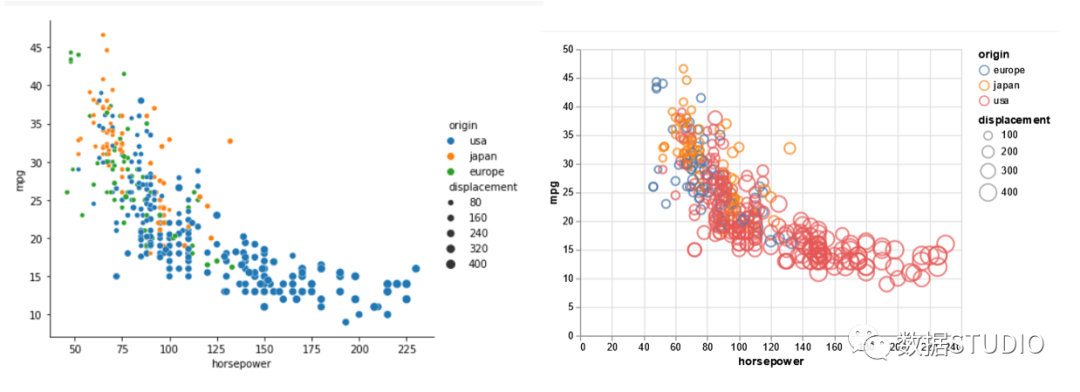
在这两个库中,我们将数据源的 DataFrame 和先前选择的"horsepower"、"mpg"列分别作为 x 和 y 传递。可以使用另一个属性 "origin" 为图例条目着色,并使用两个库的附加变量 "displacement" 控制点的大小。
在 Seaborn 中,我们可以使用 "aspect" 设置来控制绘图的纵横比。但是,在 Altair 中,我们还可以通过传递 0 到 1 之间的值来控制点的不透明度值(1 表示完全不透明)。
要将 Seaborn 中的散点图转换为气泡图,只需为"sizes"传递一个值,该值表示图表中气泡的最小和最大尺寸。对于 Altair,我们只需通过 (filled=True) 来生成气泡图。
sns.scatterplot(data=df, x="horsepower", y="mpg",
size="displacement", hue='origin',
legend=True, sizes=(10, 500))
alt.Chart(df).mark_point(filled=True).encode(
x='horsepower',
y='mpg',
size='displacement',
color='origin'
)
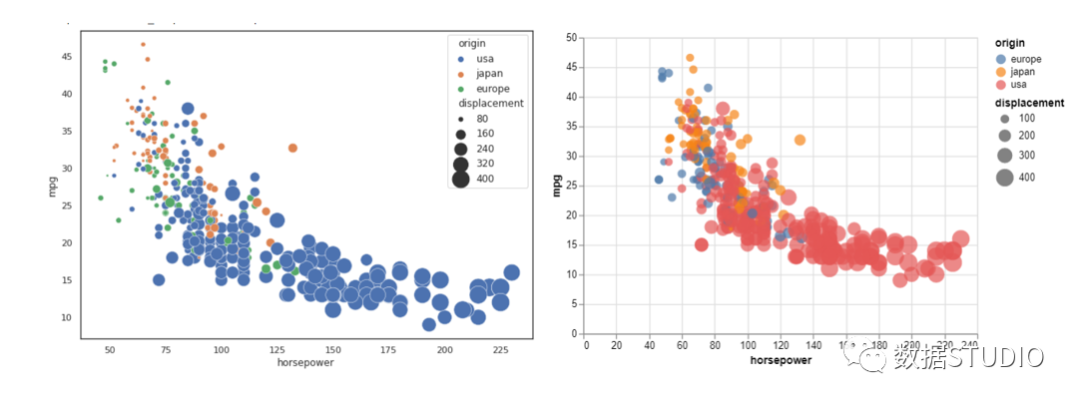
通过以上散点图,我们可以理解"horsepower"和"mpg"变量之间的关系,即"horsepower"较低的车辆似乎具有较高的"mpg"。两个图的语法相似,可以自定义以显示值。
折线图
现在,我们绘制"horsepower"和"mpg"属性的折线图。线图的语法对两者都非常简单。我们将 DataFrame 作为数据传递,上述两个变量为 x 和 y,而 'origin' 作为图例颜色。
Seaborn
sns.lineplot(data=df, x='horsepower',
y='acceleration',hue='origin')
Altair
alt.Chart(df).mark_line().encode(
alt.X('horsepower'),
alt.Y('acceleration'),
alt.Color('origin')
)
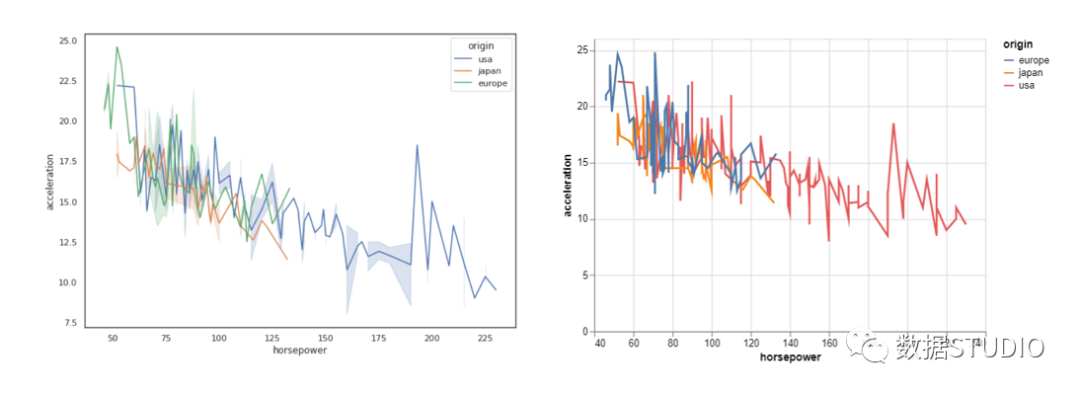
在这里我们可以理解"usa"车辆具有更高的"horsepower"范围,而其他两个"japan"和 "europe" 的"horsepower"范围更窄。同样,这两个图都很好地提供了相同的信息并且看起来同样出色。
条形图和计数图
在下一组可视化中,我们将绘制一个基本的条形图和计数图。这一次,我们还将添加一个图表标题。我们将使用"cylinders"和"mpg"属性作为绘图的 x 和 y。
对于 Seaborn 图,我们将上述两个特征与 Dataframe 一起传递。为了自定义颜色,我们从 Seaborn 的预定义调色板中选择了一个Palette='magma_r'。
sns.catplot(x='cylinders', y='mpg',
hue="origin", kind="bar",
data=df, palette='magma_r')
在 Altair 条形图中,我们传递 df、x 和 y,并根据"origin"特征指定颜色。在这里,我们可以通过在"mark_bar"命令中传递一个值来自定义条形的大小,如下所示。
plot=alt.Chart(df).mark_bar(size=40).encode(
alt.X('cylinders'),
alt.Y('mpg'),
alt.Color('origin')
)
plot.properties(title='cylinders vs mpg')
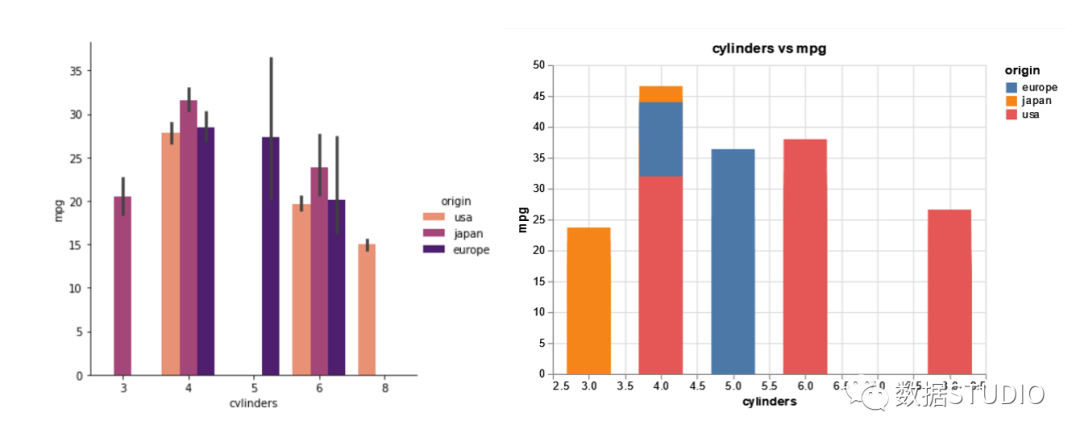
从上面的条形图中,我们可以看到带有 4 个汽缸的车辆对于"mpg"值似乎是最有效的。
这是计数图的语法
Seaborn
我们使用 FacetGrid 命令根据变量"origin"在网格上显示多个图。
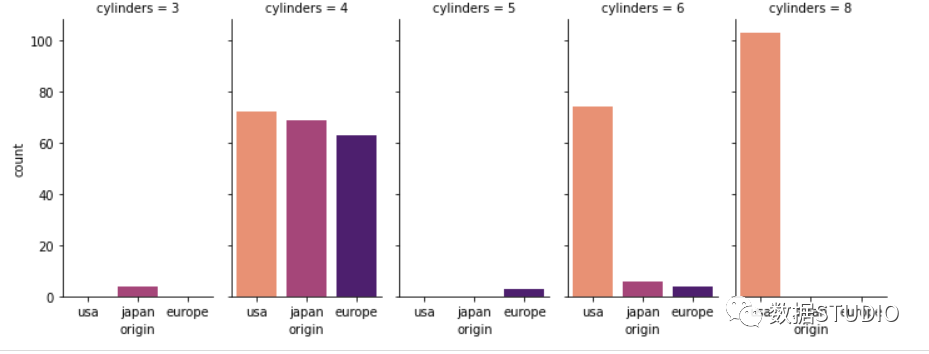
g = sns.FacetGrid(df, col="cylinders",
height=4,aspect=.5,
hue='origin',palette='magma_r')
g.map(sns.countplot, "origin",
order = df['origin'].value_counts().index)
Altair
我们再次使用"mark_bar"命令,但将圆柱列的"count()"作为 y 传递以生成计数图。
alt.Chart(df).mark_bar().encode(
x='origin',
y='count()',
column='cylinders:Q',
color=alt.Color('origin')
).properties(
width=100,
height=100
)
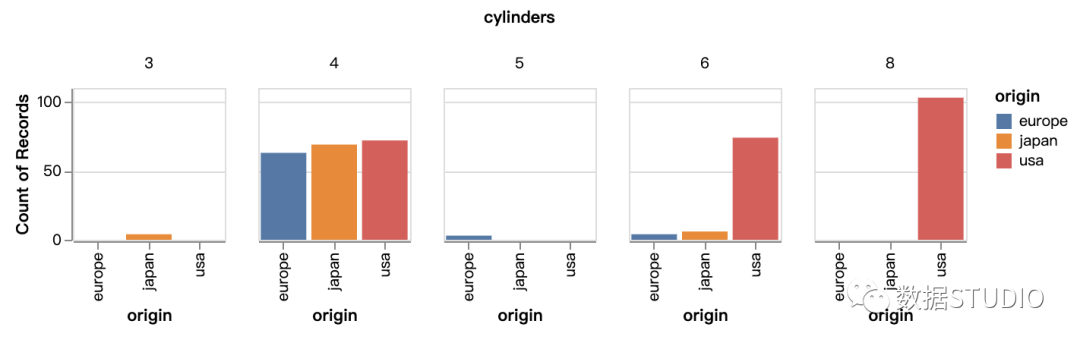
从这两个计数图中,我们可以很容易地理解"japan"有 (3,4,6) 缸车辆,"europe"有 (4,5,6) 缸车辆,"usa"有 (4,6,8) 缸车辆汽缸车。从语法的角度来看,这些库需要数据源的输入 x、y 来绘制。两个库的输出看起来还挺不错的。
接下来尝试更多的图并进行比较。
直方图
在这组可视化中,我们将绘制基本的直方图。在 Seaborn 中,我们使用 distplot 命令并传递数据框的名称,要绘制的列的名称。我们还可以使用"aspect"设置"宽高比"来调整绘图的高度和宽度。
Seaborn
sns.distplot(df, x='model_year', aspect=1.2)
Altair
alt.Chart(df).mark_bar().encode(
alt.X("model_year:Q", bin=True),
y='count()',
).configure_mark(
opacity=0.7,
color='cyan'
)
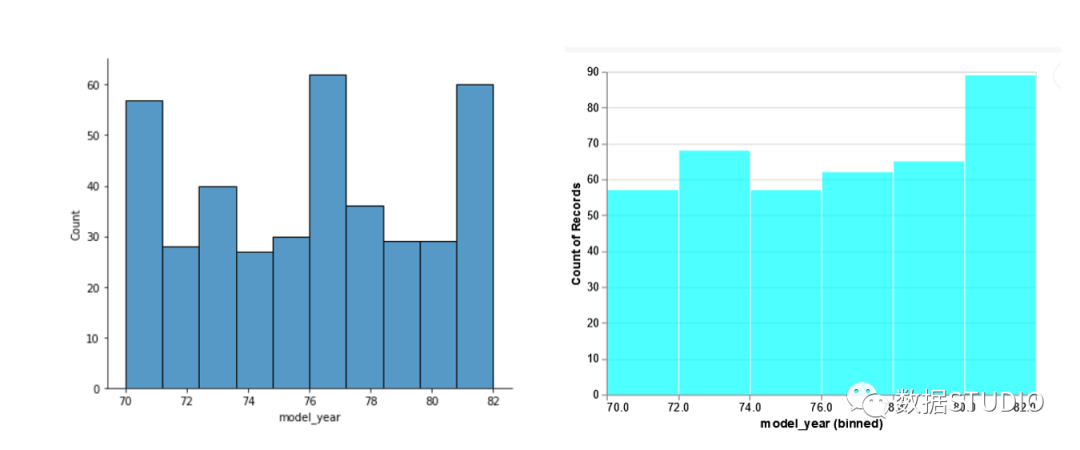
在这组可视化中,两个库的选定默认 bin 不同,因此绘图看起来略有不同。我们可以通过调整 bin 大小在 Seaborn 中获得相同的图。
sns.displot(df, x='model_year',
bins=[70,72,74,76,78,80,82],
aspect=1.2)
现在情节看起来很相似。然而,在这两个图中,我们可以看到最大的车辆数量是在 76 年之后,并且在 82 年尤为突出。此外,我们使用了一个配置命令来修改条的颜色和不透明度,这在 Altair 情节的情况下就像一个主题。
带状图
对于 Seaborn,我们将使用 stripplot 命令并将整个 DataFrame 和变量"cylinders"、"horsepower"分别传递给 x 和 y。
ax = sns.stripplot(data=df, y= ‘horsepower’, x= ‘cylinders’)
对于 Altair 图,我们使用 mark_tick 命令生成具有相同变量的带状图。
alt.Chart(df).mark_tick(filled=True).encode(
x='horsepower:Q',
y='cylinders:O',
color='origin'
)
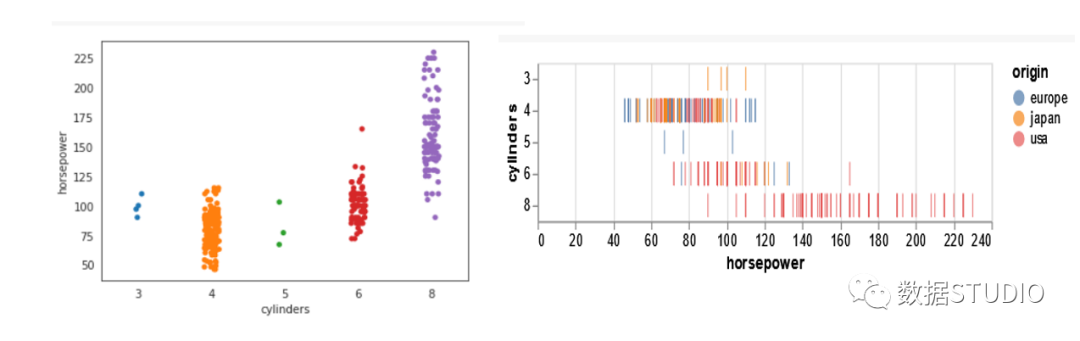
从上面的图中,我们可以清楚地看到不同"origin"的分类变量"cylinders"的散布情况。这两个图表在传达气缸数之间的关系方面似乎同样有效。对于 Altair 图,我们会发现 x 和 y 列在语法中已互换,以避免出现更高和更窄的图。
交互图
我们现在来到这个比较中的最后一组可视化——交互式绘图。
与 Bokeh、Plotly 和 Dash 库相比,Altair 在交互式绘图方面语法更简单。另一方面,Seaborn 不提供与任何图表的交互性。如果你想过滤掉绘图本身内部的数据并专注于绘图中感兴趣的区域/区域,就不建议使用Seaborn。
为了在 Altair 中设置交互式图表,我们定义了一个具有"interval"类型选择的选择,即在图表上的两个值之间。然后我们使用之前定义的选择定义列的活动点。接下来,我们指定要为选择显示的图表类型(绘制在主图表下方)并传递"select"作为显示值的过滤器。
select = alt.selection(type='interval')
values = alt.Chart(df).mark_point().encode(
x='horsepower:Q',
y='mpg:Q',
color=alt.condition(select, 'origin:N', alt.value('lightgray'))
).add_selection(
select
)
bars = alt.Chart(df).mark_bar().encode(
y='origin:N',
color='origin:N',
x='count(origin):Q'
).transform_filter(
select
)
values & bars
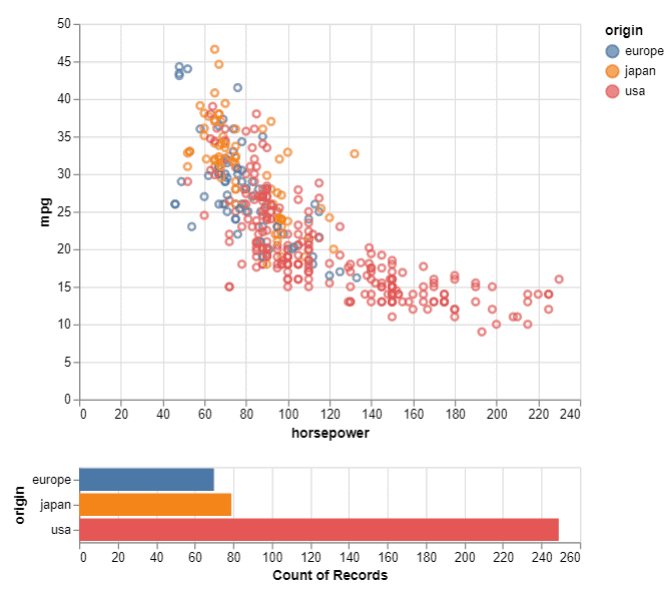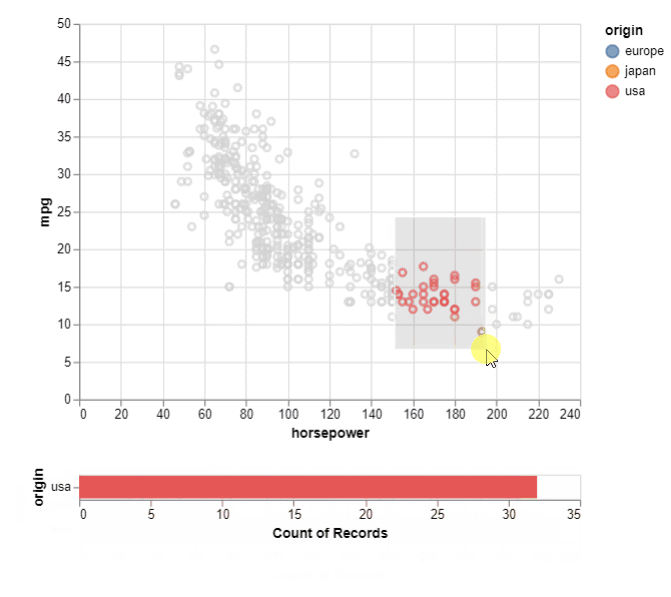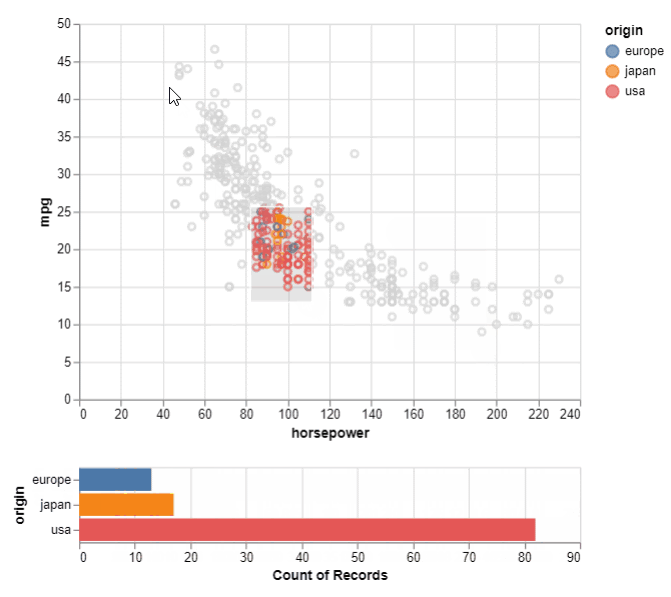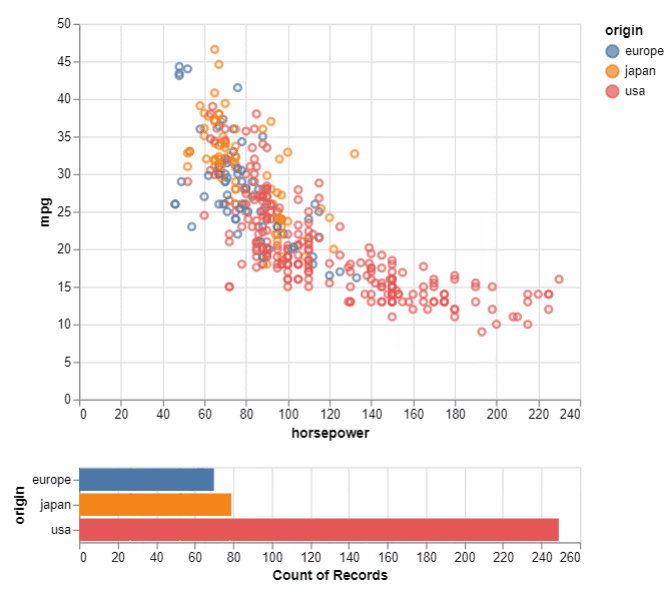
对于交互式绘图,我们可以轻松地可视化所选区域的样本数。当图表的一个区域中有太多样本/点并且我们想要可视化它们的细节以更好地理解基础数据时,这很有用。
Altair 其他要点
饼图和甜甜圈图
可惜的是,Altair 不支持饼图。这是 Seaborn 获胜的一个点,我们可以利用 matplotlib 功能通过 Seaborn 库生成饼图。
绘制网格、主题和自定义绘图大小
这两个库还允许在生成多个绘图、操纵纵横比或图形大小方面自定义绘图,并支持为颜色和背景设置不同的主题以修改图表的外观。
高级绘图
此外,还有其他高级绘图,如棒棒糖或破折号和点图、热图、树状图,可以使用这两个库进行绘制(Seaborn 可能为此需要一些额外的包),但在此比较中这些已被排除在外以保持它简单的。
写在最后
我们绘制了不少 Seaborn 和 Altair 的各种类型的图。数据可视化库——Seaborn 和 Altair 看起来同样强大。
与 Altair 相比,Seaborn 的语法更易于编写和理解;而与 Seaborn 图相比,Altair 中的数据可视化似乎更加美观及引人注目。生成交互式可视化的能力是 Altair 提供的另一个优势。因此,选择其中之一取决于个人喜好和可视化要求。
理想情况下,这两个库都可以自给自足地处理大部分数据可视化需求。如果你需要快速绘制简单的图作为数据分析的一部分,那么请选择 Seaborn。此外,如果你的项目需要饼图,那么 matplotlib 或 Seaborn 是你的首选。如果要获得交互式且外观略微精致的可视化效果,可以选择 Altair。
推荐阅读
推荐阅读