
基于深度学习的视觉三维重建研究总结
三维重建意义
三维重建作为环境感知的关键技术之一,可用于自动驾驶、虚拟现实、运动目标监测、行为分析、安防监控和重点人群监护等。现在每个人都在研究识别,但识别只是计算机视觉的一部分。真正意义上的计算机视觉要超越识别,感知三维环境。我们活在三维空间里,要做到交互和感知,就必须将世界恢复到三维。所以,在识别的基础上,计算机视觉下一步必须走向三维重建。本文笔者将带大家初步了解三维重建的相关内容以及算法。
转载来源
作者:知乎号—MoonSmile
地址:https://www.zhihu.com/people/moonsmile-97

港科大教授权龙:计算机视觉下一步将走向三维重建 | CCF-GAIR 2018
三维重建定义
常见的三维重建表达方式




三维重建的分类
近几年代表性论文回顾
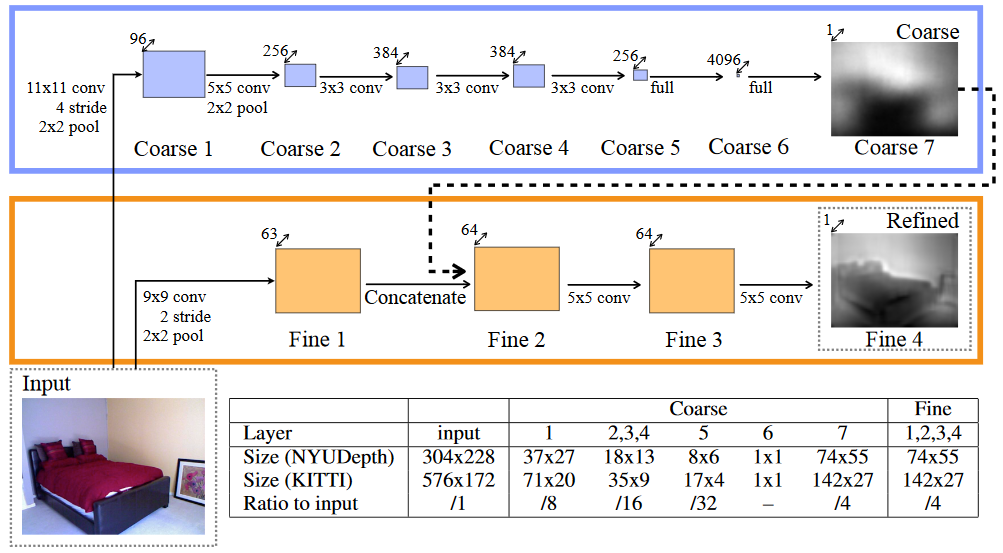
一、从单张图像恢复深度图


二、用体素来做单视图或多视图的三维重建

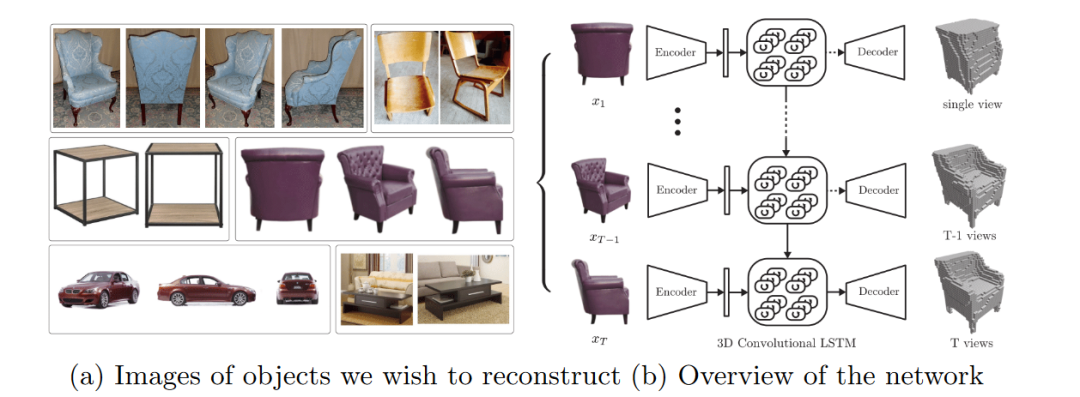
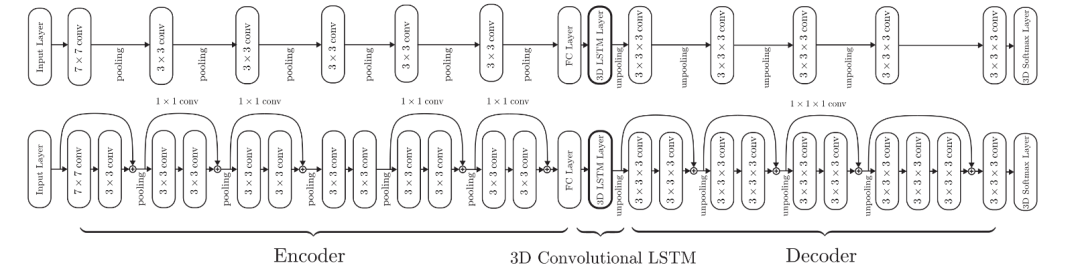
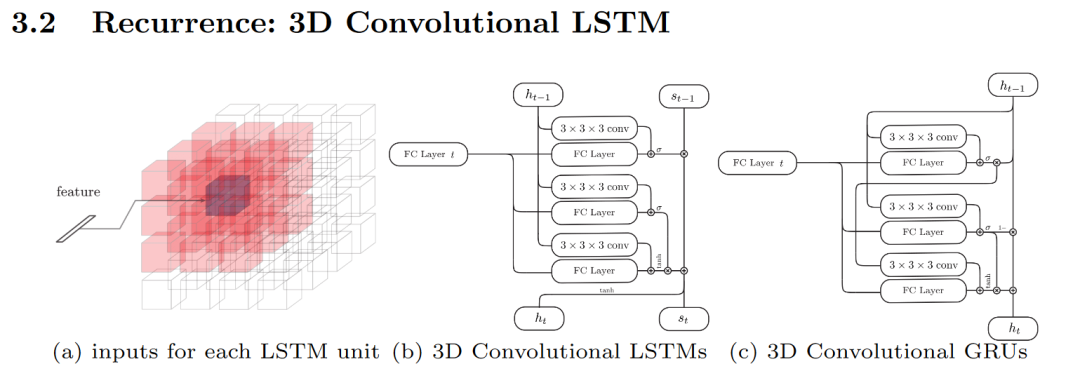




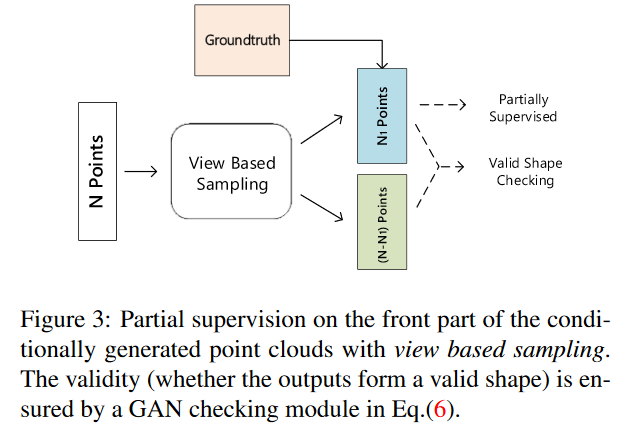
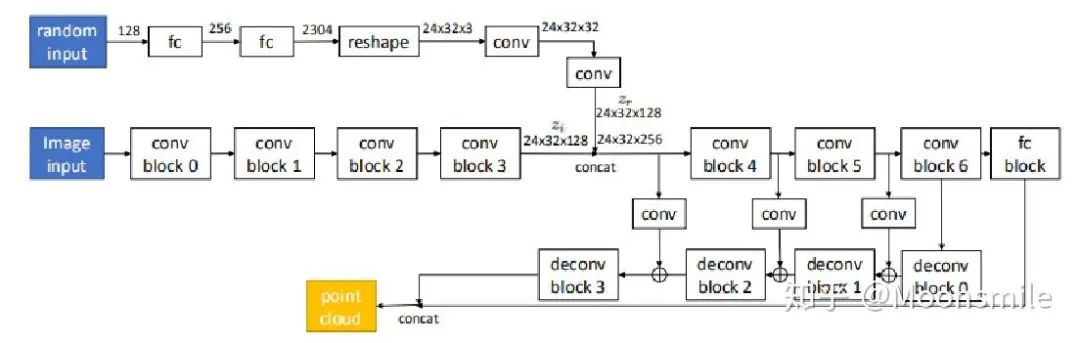
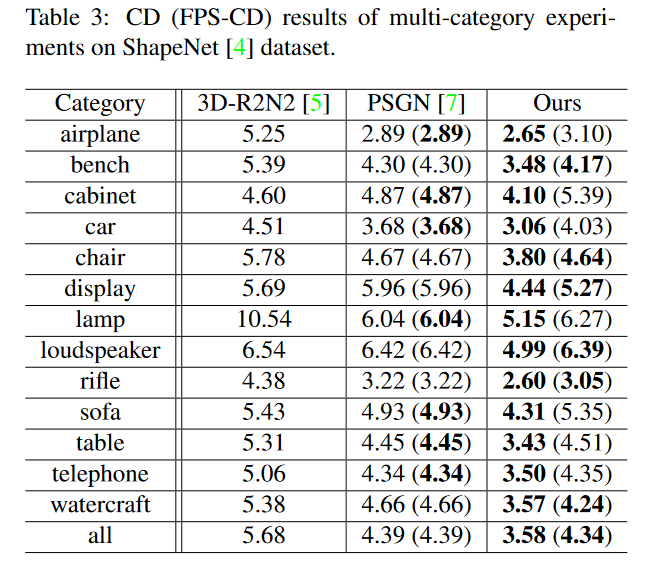
三、用点云来做单张RGB图像的三维重建


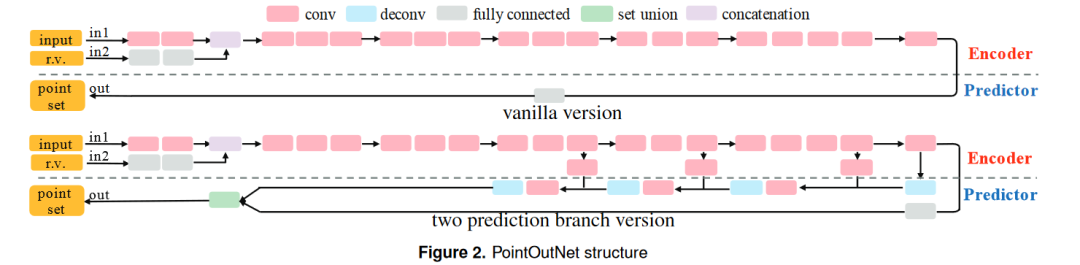
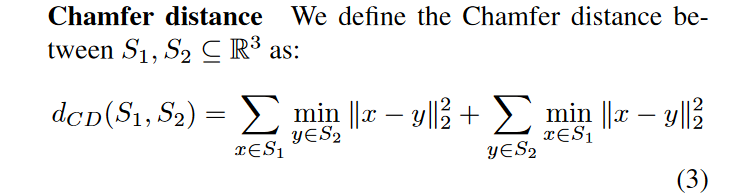
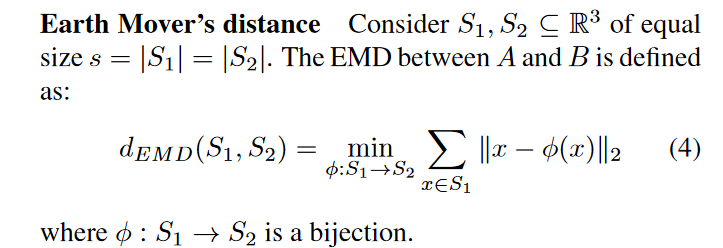
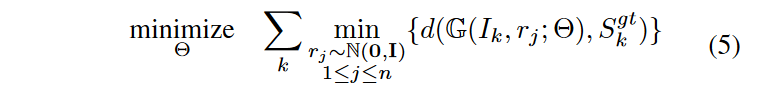
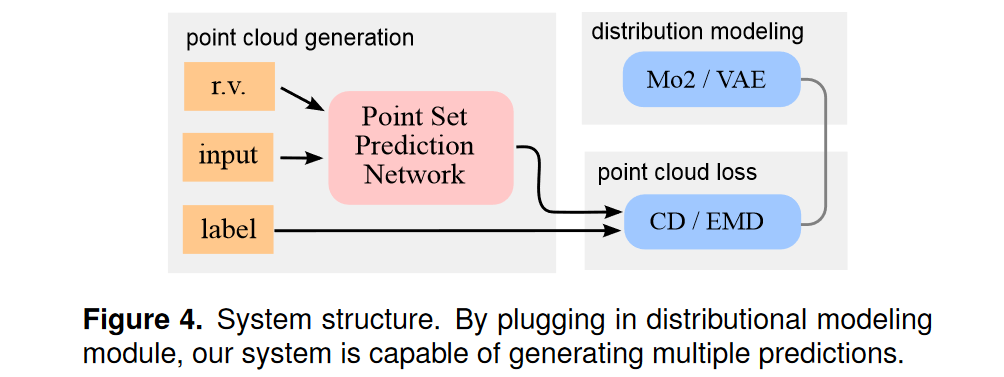

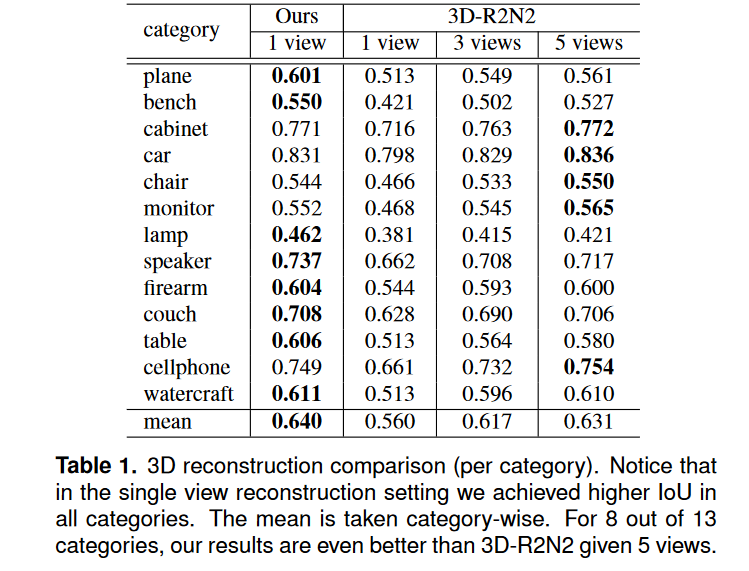
先中场休息一下,简单先分析一下:


四、用三角网格来做单张RGB图像的三维重建

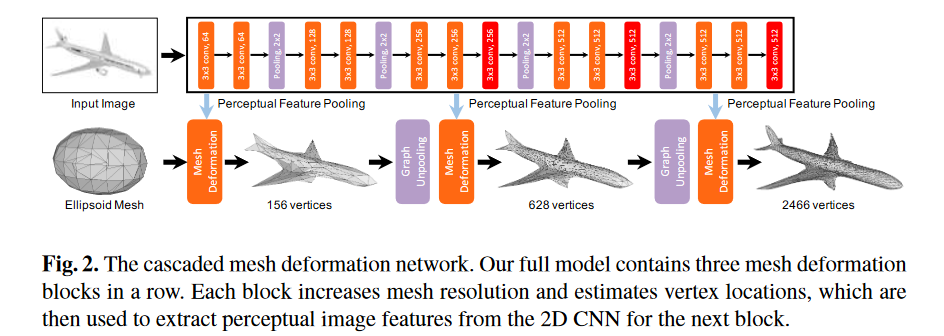
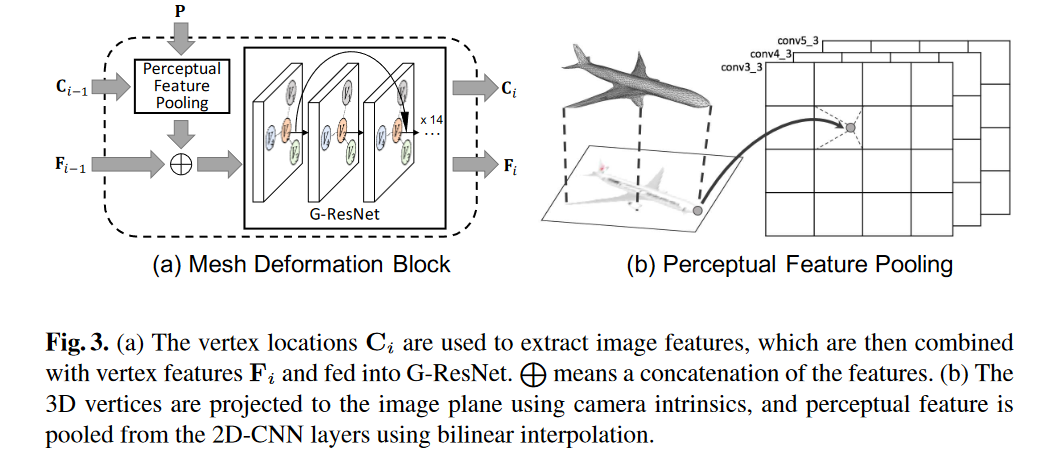
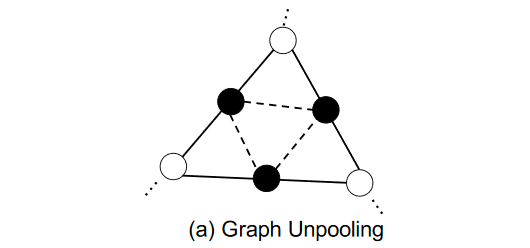




接下来介绍2019年的相关研究
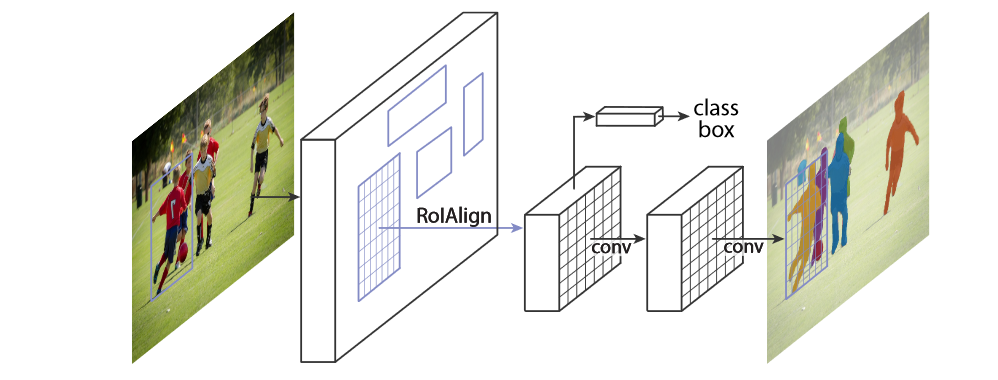

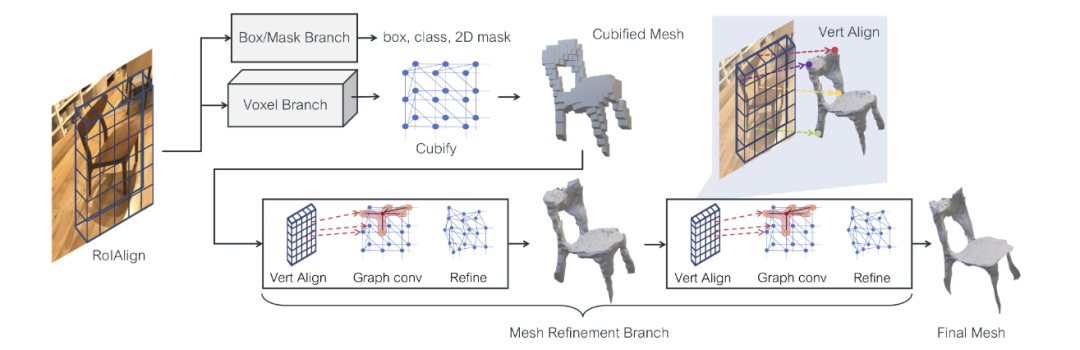
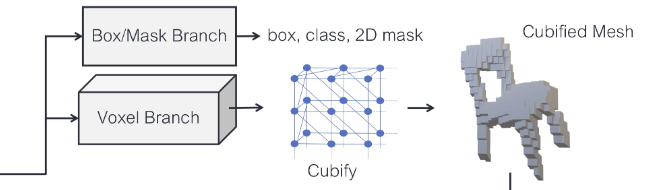
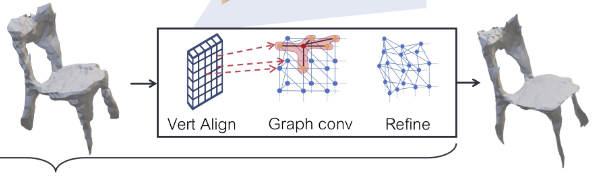
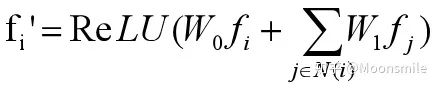
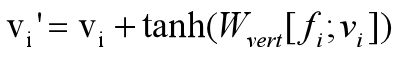



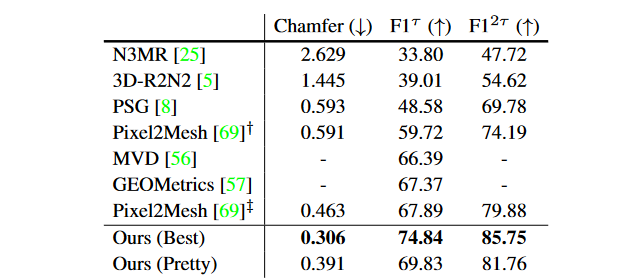
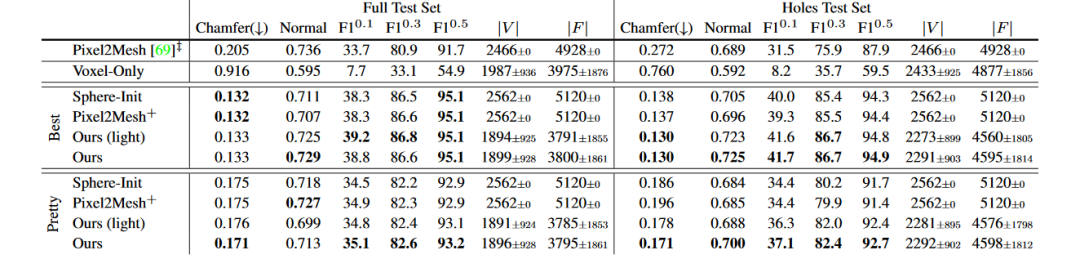
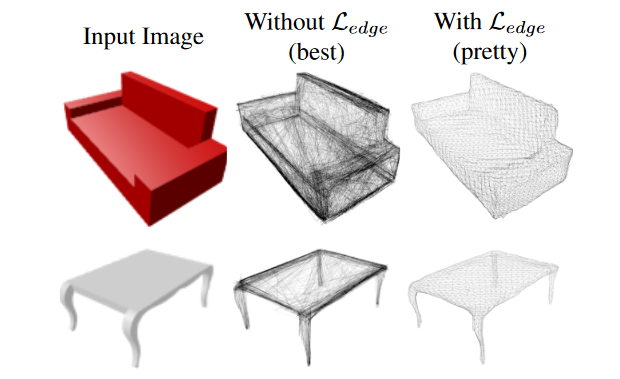





最后介绍一篇论文,也是CVPR 2019的文章


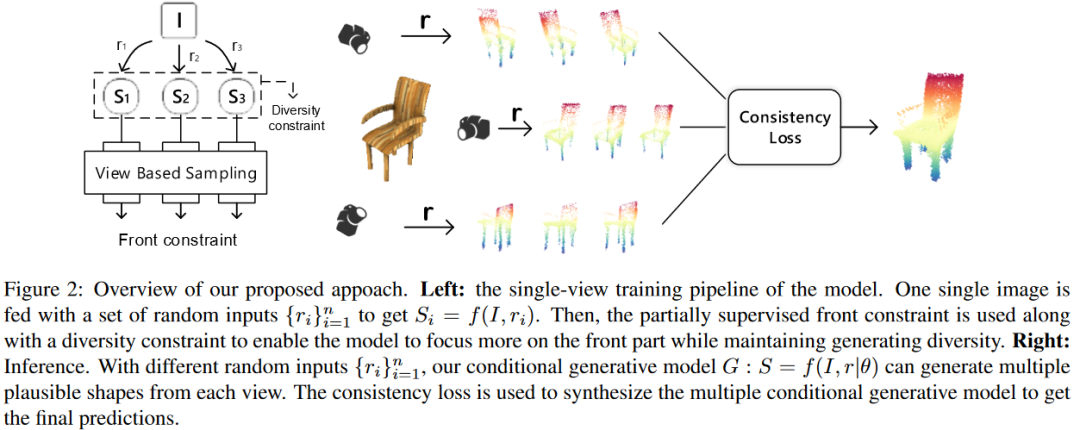
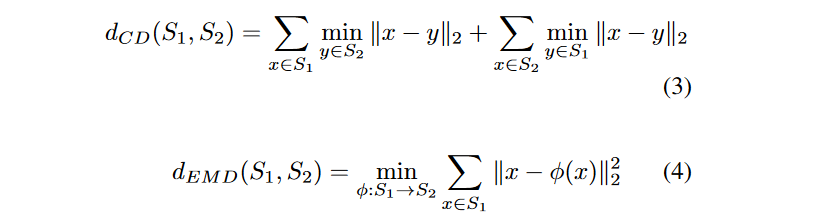
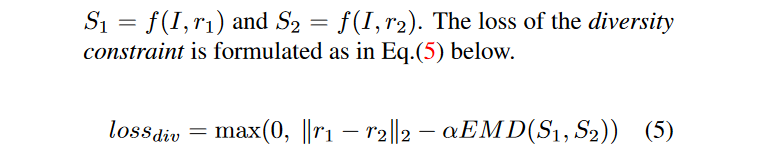
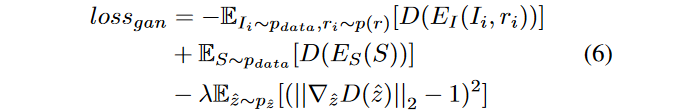




 End
End 声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
评论