
盘点目标检测中的特征融合技巧(根据YOLO v4总结)
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
特征融合分类
Feature Pyramid Network(FPN)
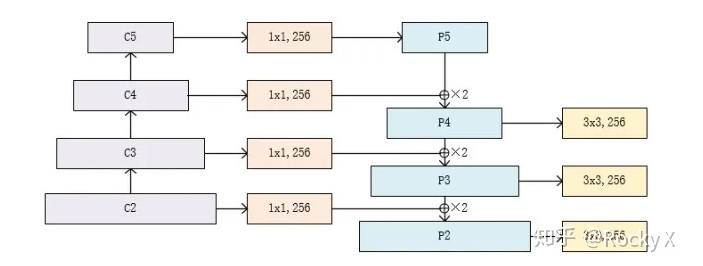
import torch.nn as nnimport torch.nn.functional as Fimport mathclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_planes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.bottleneck = nn.Sequential(nn.Conv2d(in_planes, planes, 1, bias=False),nn.BatchNorm2d(planes),nn.ReLU(inplace=True),nn.Conv2d(planes, planes, 3, stride, 1, bias=False),nn.BatchNorm2d(planes),nn.ReLU(inplace=True),nn.Conv2d(planes, self.expansion * planes, 1, bias=False),nn.BatchNorm2d(self.expansion * planes),)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xout = self.bottleneck(x)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass FPN(nn.Module):def __init__(self, layers):super(FPN, self).__init__()self.inplanes = 64self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(3, 2, 1)self.layer1 = self._make_layer(64, layers[0])self.layer2 = self._make_layer(128, layers[1], 2)self.layer3 = self._make_layer(256, layers[2], 2)self.layer4 = self._make_layer(512, layers[3], 2)self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)self.latlayer2 = nn.Conv2d( 512, 256, 1, 1, 0)self.latlayer3 = nn.Conv2d( 256, 256, 1, 1, 0)def _make_layer(self, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != Bottleneck.expansion * planes:downsample = nn.Sequential(nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),nn.BatchNorm2d(Bottleneck.expansion * planes))layers = []layers.append(Bottleneck(self.inplanes, planes, stride, downsample))self.inplanes = planes * Bottleneck.expansionfor i in range(1, blocks):layers.append(Bottleneck(self.inplanes, planes))return nn.Sequential(*layers)def _upsample_add(self, x, y):_,_,H,W = y.shapereturn F.upsample(x, size=(H,W), mode='bilinear') + ydef forward(self, x):c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))c2 = self.layer1(c1)c3 = self.layer2(c2)c4 = self.layer3(c3)c5 = self.layer4(c4)p5 = self.toplayer(c5)p4 = self._upsample_add(p5, self.latlayer1(c4))p3 = self._upsample_add(p4, self.latlayer2(c3))p2 = self._upsample_add(p3, self.latlayer3(c2))p4 = self.smooth1(p4)p3 = self.smooth2(p3)p2 = self.smooth3(p2)return p2, p3, p4, p5
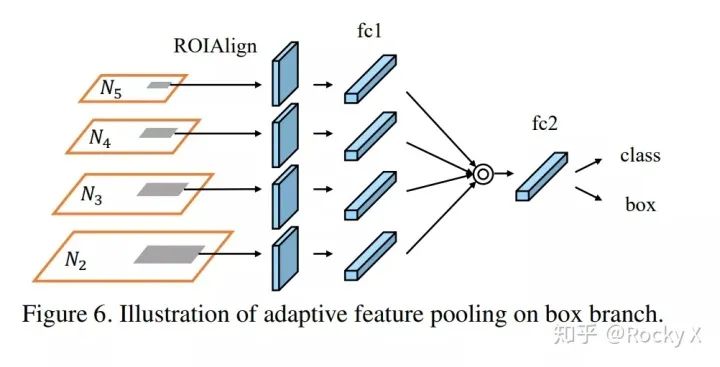
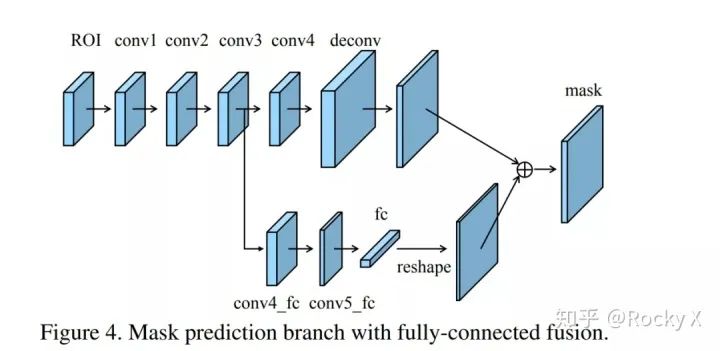
PANet(Path Aggregation Network)
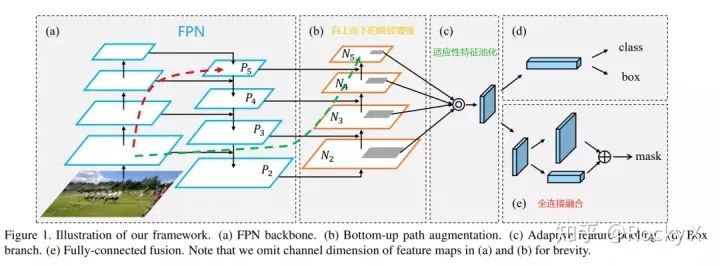
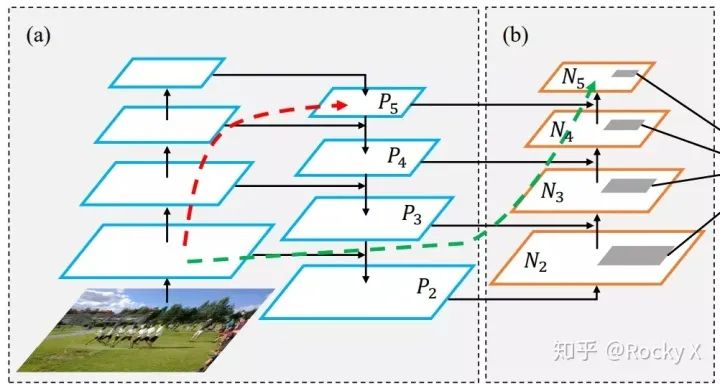
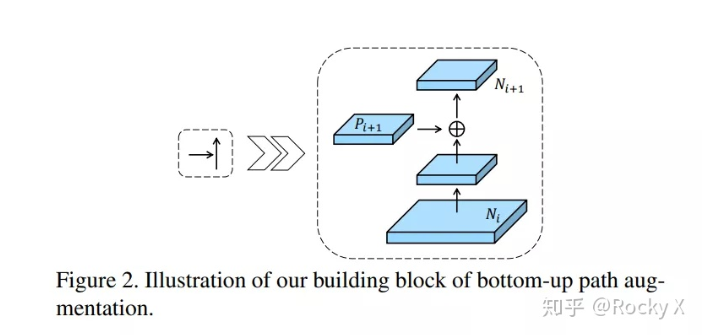
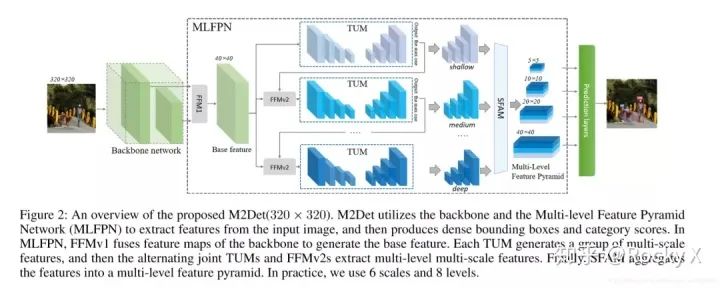
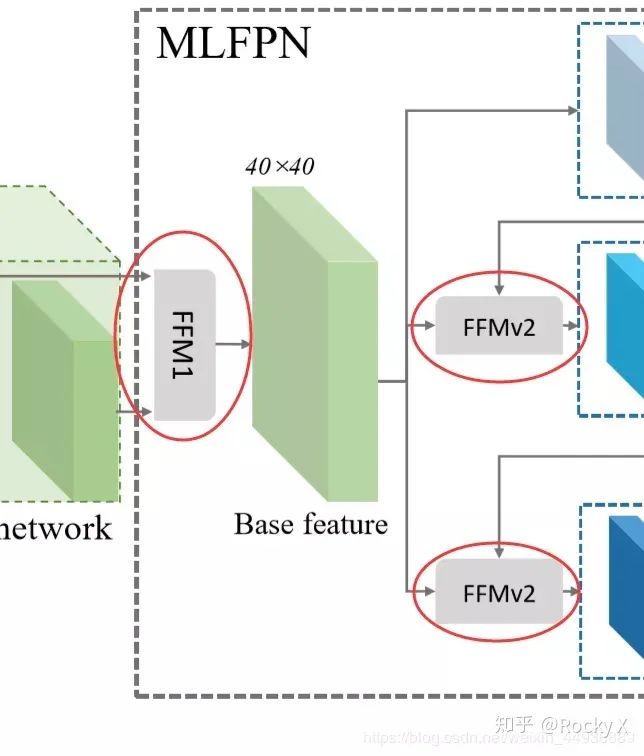
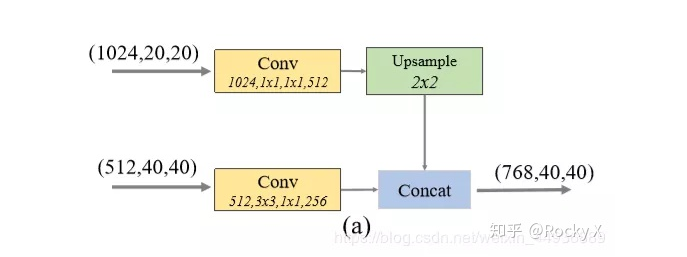
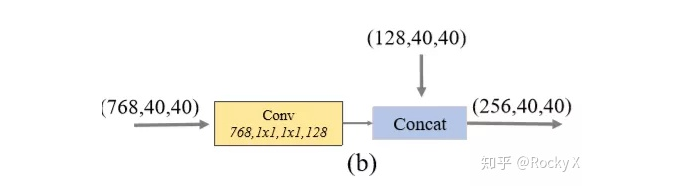
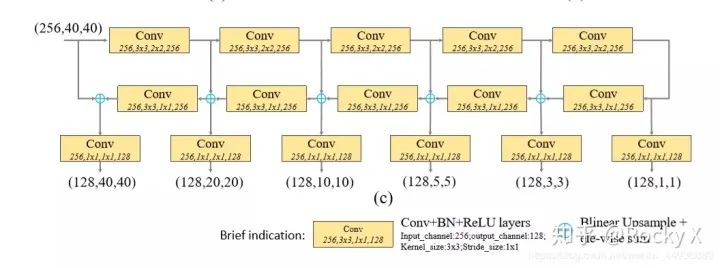
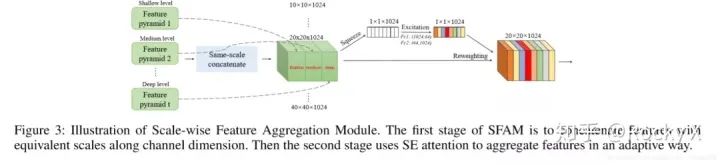
MLFPN
ASFF:自适应特征融合方式
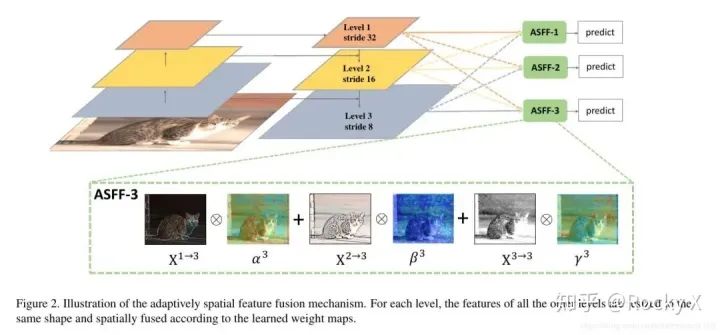
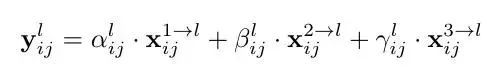
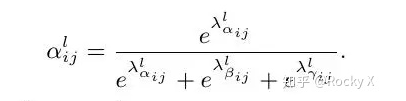
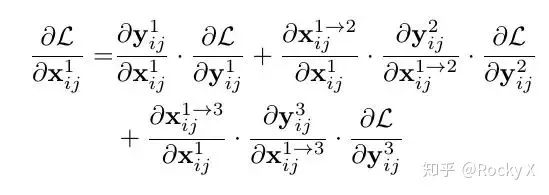
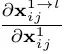
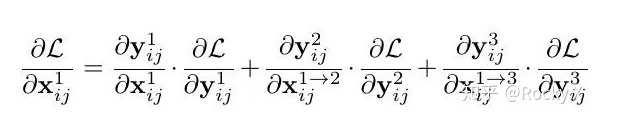
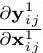
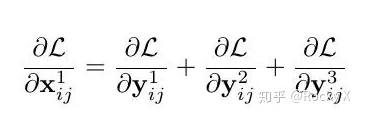
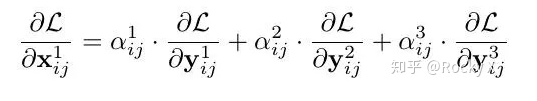
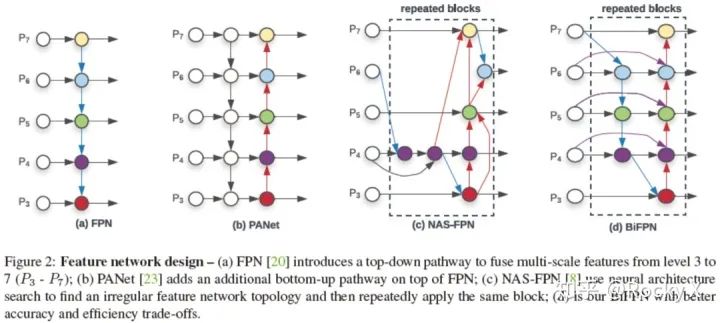
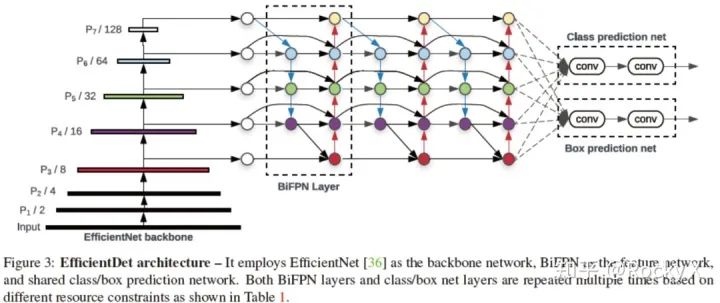
Bi-FPN
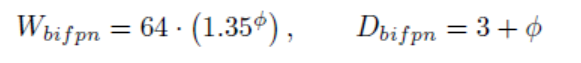

评论