
视频目标检测大盘点

极市导读
基于视频的目标检测与普通的图片目标检测任务一样,但视频的目标检测有更多的难点和更高的要求。为了便于大家的学习,本文分点讲述了视频目标检测的七个方法,每种方法都附有相关论文链接以及方法的性能结果。>>加入极市CV技术交流群,走在计算机视觉的最前沿
视频目标识别是自主驾驶感知、监控、可穿戴设备和物联网等应用的一项重要任务。由于图像模糊、遮挡或不寻常的目标姿态,使用视频数据进行目标识别比使用静止图像更具挑战性。因为目标的外观可能在某些帧中恶化,通常使用其他帧的特征或检测来增强预测效果。解决这一问题的方法有很多: 如动态规划、跟踪、循环神经网络、有/无光流的特征聚合以跨帧传播高层特征。有些方法采用稀疏方式进行检测或特征聚合,从而大大提高推理速度。主流的多帧无光流特征聚合和 Seq-NMS 后处理结合精度最高,但速度较慢(GPU 上小于10 FPS)。在准确率和速度之间需要权衡: 通常更快的方法准确率较低。所以研究兼具准确率和速度的新方法仍然有很大潜力。
视频目标检测的方法
后处理(Post-Processing) 基于跟踪的方法(Tracking-based Methods) 3D卷积(3D Convolutions) 循环神经网络(Recurrent Neural Networks) 特征传播方法(Feature Propagation Methods) 基于光流的多帧特征聚合(Multi-frame Feature Aggregation with Optical Flow) 无光流的多帧特征聚合(Multi-frame Feature Aggregation without Optical Flow)
后处理(Post-Processing)
后处理方法是通用的过程,可以应用于任何目标检测器的输出,以改善视频中的目标检测。
序列非极大抑制(Seq-NMS)
论文地址: https://arxiv.org/abs/1602.08465
Seq-NMS 基于“轨迹”上其他检测通过动态规划对检测置信度进行修正。在同一视频段它使用附近帧高得分的目标检测来提高分数较低的检测。Seq-NMS 后处理使帧间错误检测或随机跳跃检测的数量大大减少,输出结果稳定,但显著降低了计算速度。此外,推理变为离线(该方法需要对未来的帧进行处理)。性能结果, FGFA(RFCN,ResNet101):76.3 MAP,1.4 FPS;FGFA(RFCN,ResNet101) + Seq-NMS:78.4 MAP,1.1 FPS。
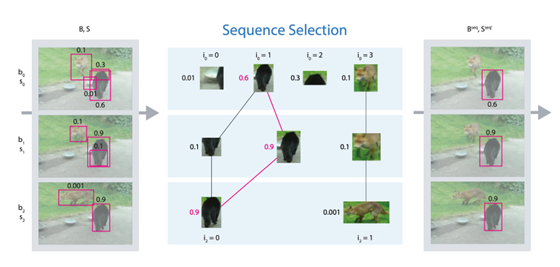
序列框匹配(Seq-Bbox Matching)
论文地址:https://www.researchgate.net/publication/331783655_Improving_Video_Object_Detection_by_Seq-Bbox_Matching
由于相邻帧是相似的,通常包含一定数量的运动目标,多个相邻帧的检测结果被认为是同一个目标的多个检测结果(tubulet)。匹配一个 tubulet 的最后一个边界框和另一个 tubulet 的第一个边界框。对同一个 tubulet 的边界框通过平均分类得分进行重新评分。Tubelet 级边界框链接有助于推理漏检和提高检测召回率。当稀疏地应用于视频帧时,该方法显著地改善了目标检测器的检测结果,同时提高了速度。性能结果, YOLOv3: 68.6 MAP,23 FPS;YOLOv3 + 序列框匹配: 78.2/80.9(在线/离线) MAP,38 FPS。
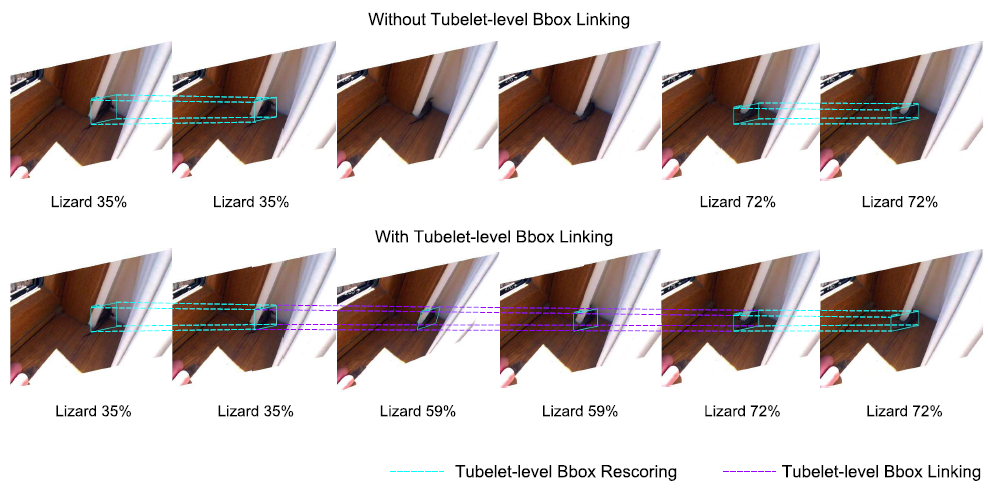
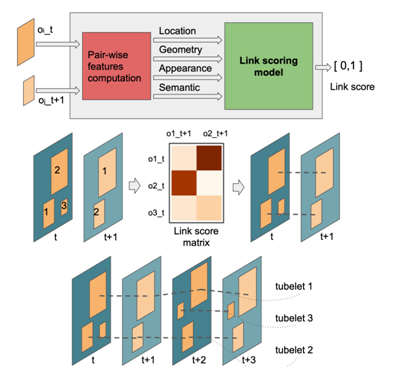
鲁棒高效的后处理(REPP / Robust and Efficient Post-Processing)
论文地址:https://arxiv.org/abs/2009.11050
REPP 通过评估帧之间的检测的相似度来链接检测,并改进它们的分类和定位以抑制假阳性和恢复漏检。对于来自连续帧(t 和 t + 1)的所有可能的检测对,基于它们的位置、几何、外观和语义构建一组特征。这些特征被用来预测链接(相似性)评分。链接在连续的帧之间建立,tubelet在第一对帧之间组成,并且只要在下一个帧中仍然能够找到相应的目标,tubelet就会被扩展。REPP 计算开销很小,但是推理变为离线。性能结果: YOLOv3:68.6 MAP,23 FPS;YOLOv3 + REPP: 75.1 MAP,22 FPS。
基于跟踪的方法(Tracking-based Methods)
通过轨迹条件检测集成目标检测和跟踪(Integrated Object Detection and Tracking with Tracklet-Conditioned Detection)
论文地址:https://arxiv.org/abs/1811.11167
轨迹条件(Tracklet-Conditioned)检测网络在早期阶段将检测和跟踪结合在一起: 不再简单地将检测器和跟踪器分别估计的两组边界框聚合在一起,而是通过基于目标检测器的输出,在先前帧计算的轨迹上生成一组单独的边界框。这样,产生的检测框既与轨迹一致,又具有高检测响应,而不是像后期集成技术中只能选两个中的一个。该模型(使用 R-FCN ResNet101 主干)在 imageenet VID 上在线设置中实现了83.5 MAP。

3D卷积(3D Convolutions)
带有 3D 卷积的卷积神经网络在处理如 MRI 等 3D 图像时已经被证明是非常有用和卓有成效的。与单帧相比,视频中目标检测应用 3D 卷积并没有明显性能提升。
循环神经网络(Recurrent Neural Networks)
带有时间感知特征图的移动视频目标检测(Mobile Video Object Detection with Temporally-Aware Feature Maps)
论文地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Liu_Mobile_Video_Object_CVPR_2018_paper.pdf
该模型将快速的单图像目标检测和卷积 LSTM 层结合起来,创建了一个交织的循环卷积结构。一个高效的瓶颈 LSTM 层相比常规 LSTM 显著降低了计算成本。该模型在线运行,可在低功耗移动设备和嵌入式设备上实时运行,在移动设备上实现了45.1 MAP,14.6 FPS。
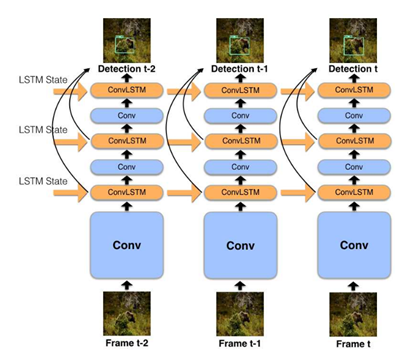
搜寻快和慢: 记忆导向的移动视频目标检测(Looking Fast and Slow: Memory-Guided Mobile Video Object Detection)
论文地址:https://arxiv.org/pdf/1903.10172.pdf
该模型包含两个不同速度和识别能力的特征提取器,分别运行在不同的帧上。这些提取器得到的特征以卷积 LSTM 的形式保持场景的共同视觉记忆,通过融合前一帧的上下文和当前帧的要点(一种丰富的表示)来检测。记忆和要点的组合包含了决定什么时候更新记忆所必需的信息。该模型是在线的,在移动设备上以72.3 FPS 运行,达到59.1 MAP。
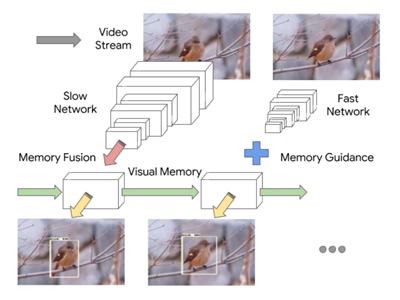
特征传播方法(Feature Propagation Methods)
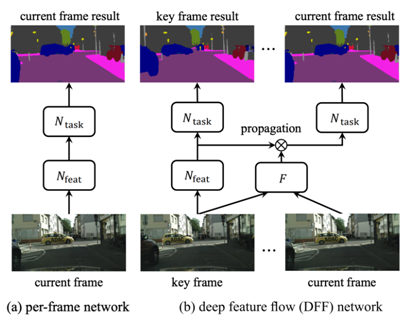
用于视频识别的深度特征流(DFF / Deep Feature Flow for Video Recognition)
论文地址:https://arxiv.org/abs/1611.07715
光流(Optical flow)是目前利用视频目标检测时间维度的研究最多的领域。DFF 只在稀疏关键帧上运行昂贵的卷积子网,并通过流场将其深度特征图传播到其他帧。pipeline 函数是 n 帧的循环。第一帧叫做关键帧。这是使用目标检测器检测的帧。在得到下一个 n-1 帧的光流后,下一个 n-1 帧的检测就是已知的了,并且周期性重复。由于流计算速度相对较快,DFF 可以显著提高速度。该模型(使用 R-FCN ResNet101 主干)在 ImageNet VID 上在线模式得到73 MAP,29 FPS。
基于光流的多帧特征聚合(Multi-frame Feature Aggregation with Optical Flow)
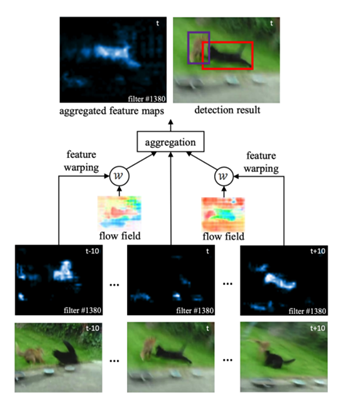
提高视频检测精度的一种方法是多帧特征融合。有不同的实现方法,但所有方法都围绕着一个思想: 密集计算每帧检测,同时特征从相邻帧向当前帧变换,加权平均聚合。因此,当前帧将受益于之前帧,以及一些未来的帧,以获得更好的检测。这种方式可以解决视频帧的运动和目标裁剪问题。
视频目标检测基于流引导的特征聚合(FGFA / Flow-Guided Feature Aggregation for Video Object Detection)
论文地址:https://arxiv.org/abs/1703.10025
流引导的特征聚合使用光流聚合附近帧的特征图,附近帧通过估计流对齐得很好。结构是一个端到端的框架,它利用了特性层面上的时间一致性。FGFA(R-FCN ResNet101 主干) 在 ImageNet VID 上在线模式达到了76.3 MAP,1.4 FPS。
迈向高性能视频目标检测(THP / Towards High Performance Video Object Detection)
论文地址:https://arxiv.org/abs/1711.11577
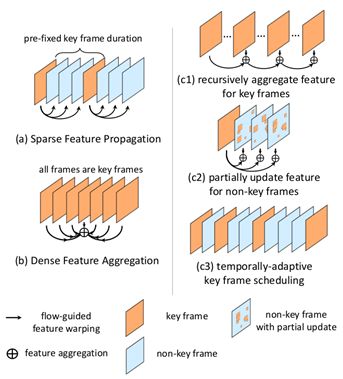
THP 采用统一的方法,基于多帧特征端到端学习和交叉帧运动原则。该算法采用光流和稀疏递归特征聚合的方法保持聚合后的特征质量。此外,它通过只在稀疏关键帧上操作来减少计算量。在传播的特征质量较差的情况下,采用空间自适应部分特征更新算法对非关键帧进行特征重计算。在端到端训练中学习特征质量,进一步提高识别准确率。时间自适应关键帧调度算法根据预测的特征质量预测关键帧的使用情况,从而提高关键帧的使用效率。THP(R-FCN Deformable ResNet101 主干) 在ImageNet VID 在线模式达到了77.8 MAP,22.9 FPS。
无光流的多帧特征聚合(Multi-frame Feature Aggregation without Optical Flow)
视频目标检测记忆增强的全局-本地聚合(MEGA / Memory Enhanced Global-Local Aggregation for Video Object Detection)
论文地址:https://arxiv.org/abs/2003.12063
MEGA 通过有效地整合全局和局部信息,增强了关键帧的候选框特征。该算法重用了在检测前帧过程中获得的预计算特征,这些特征通过全局信息增强,并缓存在远程记忆模块中。这就是当前帧和以前帧之间循环连接的构建方式。MEGA(使用 R-FCN ressnet101 主干)在 ImageNet VID上达到了82.9 MAP,8.7 FPS; 具有 Seq-NMS 和 R-FCN ResNeXt101 主干的 MEGA 可以达到85.4 MAP。

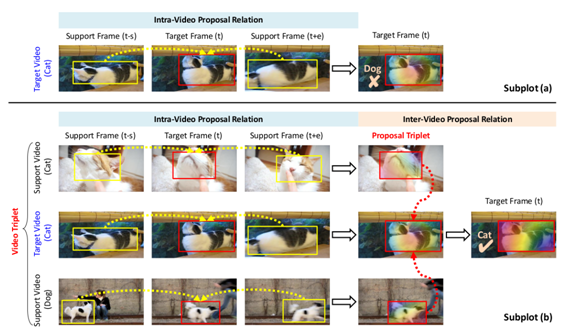
为视频目标检测挖掘视频间提议关系(HVRNet / Mining Inter-Video Proposal Relations for Video Object Detection)
论文地址:https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/3764_ECCV_2020_paper.php
HVR-Net 通过在一个多层次的三元组选择方案中利用视频内部和视频间上下文增强视频目标检测。根据 CNN 特征的余弦相似度,这个三元组包括一个目标视频,同一类别中最不相似的视频,以及不同类别中最相似的视频。对于三元组中每个视频,它的采样帧被输入到 Faster RCNN 的 RPN 和 ROI 层。这为每帧生成了目标提议(proposal)的特征向量,这些特征向量聚合在一起以增强目标帧中的提议。视频内部增强的提议主要包含每个视频中的目标语义,而忽略视频之间的目标变化。为了建立这种变化的模型,根据内部视频增强的特征,从视频三元组中选择难的提议三元组。对于每个提议三元组,来自支持视频的提议将被聚合,以提高目标视频中提议的质量。每个提议特征进一步利用视频间的依赖性,以解决视频中的目标混淆。HVRNet (使用 R-FCN ResNet101 主干) 在 ImageNet VID上可以达到83.2 MAP; 拥有 Seq-NMS 和 R-FCN ResNeXt101 主干的 HVRNet 可以得到 state-of-the-art 85.5 MAP。
比较表
mAP @0.5 on Imagenet VID
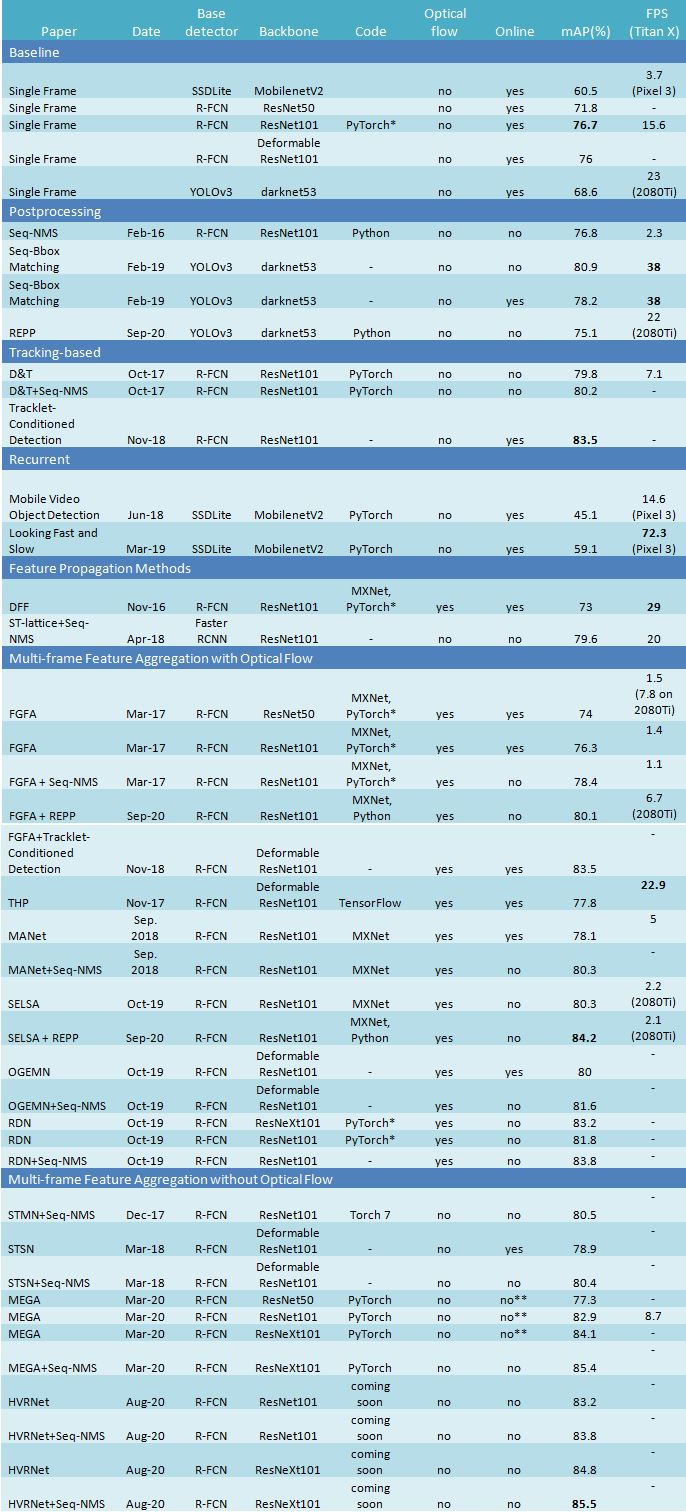
* 在 MEGA 项目内的实现
** 该方法通过一些小的改动可以在线运行
参考资料
Seq-NMS: https://arxiv.org/abs/1602.08465 (Python 源码:https://github.com/lrghust/Seq-NMS) Seq-Bbox Matching: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=2ahUKEwjWwNWa95_iAhUMyoUKHR-GAJwQFjABegQIBBAC&url=http%3A%2F%2Fwww.insticc.org%2FPrimoris%2FResources%2FPaperPdf.ashx%3FidPaper%3D72600&usg=AOvVaw1dTqzUoybpNRVkCdkA1xg0 REPP: https://arxiv.org/abs/2009.11050 (Python 源码:https://github.com/AlbertoSabater/Robust-and-efficient-post-processing-for-video-object-detection) D&T: https://arxiv.org/abs/1710.03958 (PyTorch 源码:https://github.com/Feynman27/pytorch-detect-to-track) Tracklet-Conditioned Detection: https://arxiv.org/abs/1811.11167 Mobile Video Object Detection: https://arxiv.org/abs/1711.06368 (PyTorch 源码:https://github.com/vikrant7/mobile-vod-bottleneck-lstm) Looking Fast and Slow: https://arxiv.org/abs/1903.10172 (PyTorch 源码:https://github.com/vikrant7/pytorch-looking-fast-and-slow) ST-lattice: https://arxiv.org/abs/1804.05472 FGFA: https://arxiv.org/abs/1703.10025 (MXNet 源码:https://github.com/msracver/Flow-Guided-Feature-Aggregation, PyTorch* 源码:https://github.com/Scalsol/mega.pytorch) THP: https://arxiv.org/abs/1711.11577 (TensorFlow 源码:https://github.com/stanlee321/LightFlow-TensorFlow) MANet: http://openaccess.thecvf.com/content_ECCV_2018/html/Shiyao_Wang_Fully_Motion-Aware_Network_ECCV_2018_paper.html (MXNet 源码:https://github.com/wangshy31/MANet_for_Video_Object_Detection) SELSA: https://arxiv.org/abs/1907.06390 (MXNet 源码:https://github.com/happywu/Sequence-Level-Semantics-Aggregation) OGEMN: https://www.semanticscholar.org/paper/Object-Guided-External-Memory-Network-for-Video-Deng-Hua/d998d202fde50839b0bc3bbdc4324e3054b87919 RDN: https://arxiv.org/abs/1908.09511 (PyTorch* 源码:https://github.com/Scalsol/mega.pytorch) STMN: https://arxiv.org/abs/1712.06317 (Torch 7 源码:http://fanyix.cs.ucdavis.edu/project/stmn/project.html) STSN: https://arxiv.org/abs/1803.05549 MEGA: https://arxiv.org/abs/2003.12063 (PyTorch 源码:https://github.com/Scalsol/mega.pytorch) HVRNet: https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/3764_ECCV_2020_paper.php (即将开源: https://github.com/youthHan/HVRNet)
来源:
https://blog.usejournal.com/the-ultimate-guide-to-video-object-detection-2ecf9459f180
推荐阅读
