
字体反爬之博X网实战
作者 | 老肥
来源 | 老肥码码码
今天的目标网站是某彩票网站博X网。其主要的反爬技术为字体反爬,话不多说,我们直接开始!
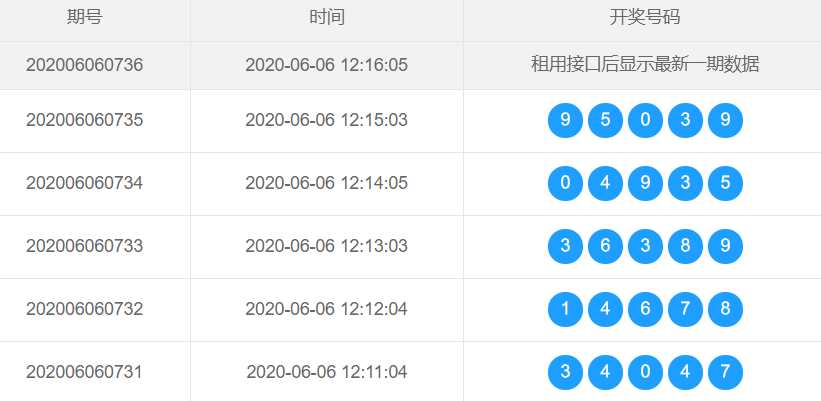
我们想要获取的是具体的开奖号码,此号码是通过蓝色的小球表示的,如何获取呢?
观察NetWork后,我们很容易发现这些号码数据等信息都以json的形式放在下图红色圈出的html页面中。

而这些号码数据是以类似于这种形式表示的(上图中蓝色框部分)。
因此,我们的爬取路线可以分两步走,先设法获取该json数据,继而通过某种方式将数据中的编码转换为正常的数字。
JSON获取
观察该页面的Headers数据,可知为POST请求,其表单数据格式如下图所示,
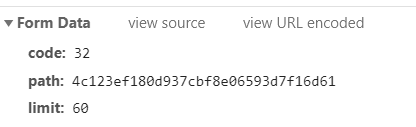
反复刷新页面发现code和limit是固定的参数,而path是不断变化的,因而我们需要找到path参数才能够构造POST请求访问页面并获取数据。
我们复制当前的path参数到搜索框搜索,发现有两个页面包含该path参数。
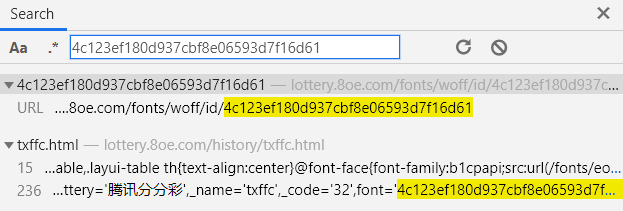
txffc.html这个页面正是我们爬取的目标页面,我们只需要从该页面的网页源代码中通过正则表达式获取该path参数即可,也就是代码中的woff_id。
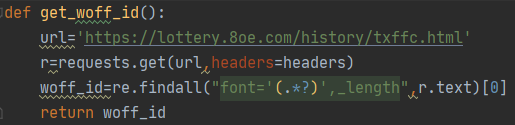
从另外一个页面,我们可以下载对应path的woff字体文件,并借此解码出这些数据,后面会详细讲。
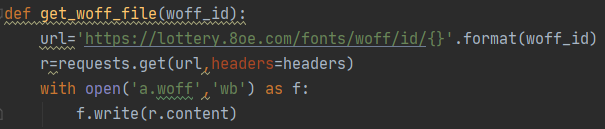
得到path参数之后,我们可以轻松的构建POST请求,并获取到相应的json数据,这里建议选择Headers参数的时候,除了User-Agent,记得将网页请求携带的所有参数带上,以防无法正常获取数据。
字体反爬
上面讲到,根据path我们已经可以获取相应的woff文件,用FontCreator打开看看。
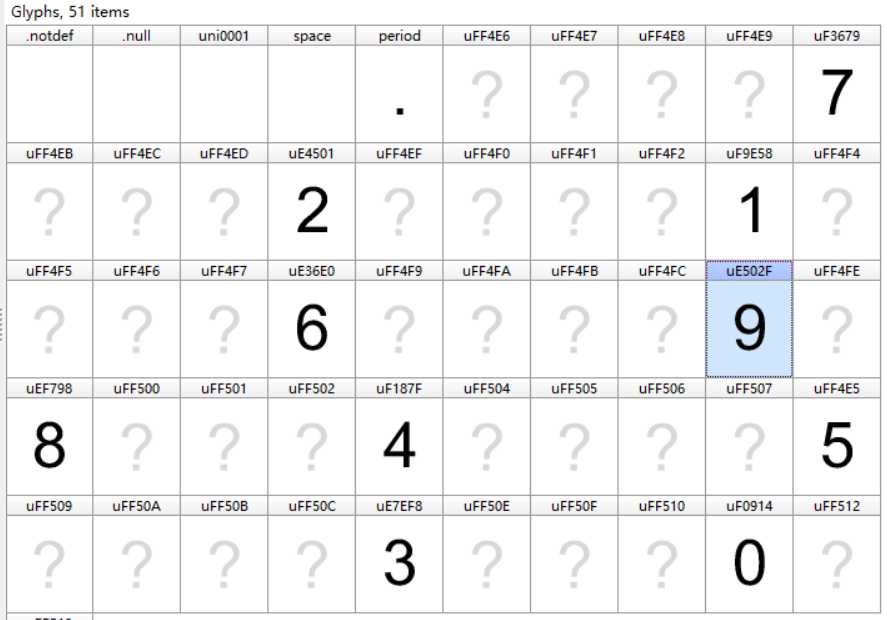
我们可以看到0-9一共十个数字,json数据中的正是通过这样的字体文件转换的。
这里出现了几个难点。
字体文件实时变化,人工的方法只能每爬取一次,根据woff文件做一次转换,来得到想要的数据;
不同时刻字体文件有些出入,比如上图包含很多问号也就是无效的字符,而有些则不包含,比如下图;

这些字体对象的name和code不一致(与猫眼等网站不同),需要构建新的映射关系;

数字9的字体坐标位置并不完全相同。
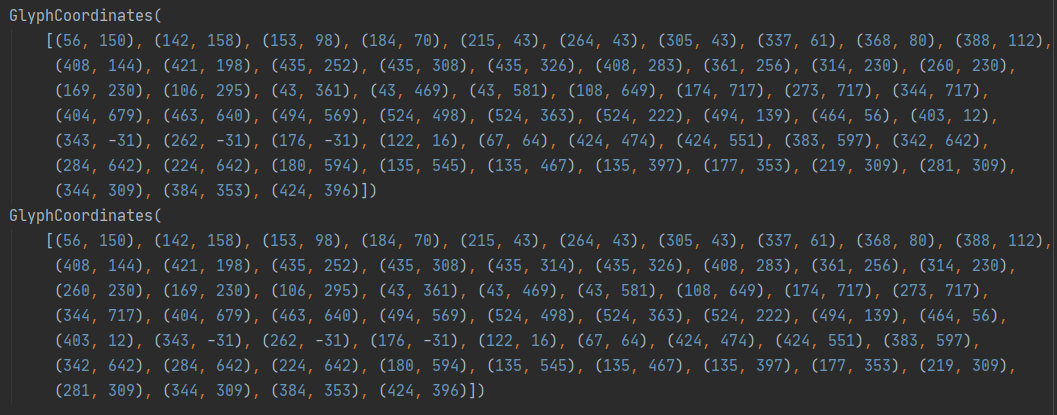
这些问题自然是需要一个一个来解决。首先我们需要一个参照系,人工标识出字体的对应关系(base_dict),从而当新字体文件引入的时候,我们可以根据这个参照获得新的映射关系。
base_dict={'glyph00009': 7, 'glyph00013': 2, 'glyph00018': 1, 'glyph00023': 6, 'glyph00028': 9, 'glyph00030': 8,'glyph00034': 4, 'glyph00039': 5, 'glyph00044': 3, 'glyph00048': 0}
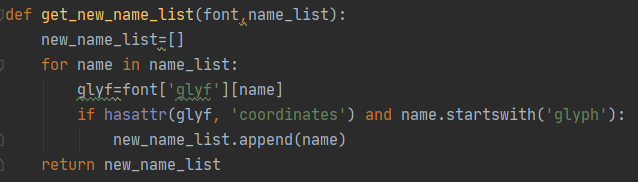
通过get_new_name_list函数来筛选出有效的字体,上述的问号字体是不存在coordinates属性的。
由于该网站不同的字体文件数字9的坐标位置有些许不同,这里采用对比字体前十个坐标来做判断,如果完全相同,则认为对应的字体是相同的数字。
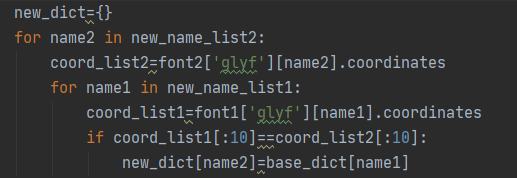
我们由此可以得到新的字典new_dict——它的键为新字体文件的字体对象的name,值为字体对应的数字。
{'glyph00002': 6, 'glyph00003': 1, 'glyph00004': 0, 'glyph00005': 4, 'glyph00006': 7, 'glyph00007': 5, 'glyph00008': 8, 'glyph00009': 9, 'glyph00010': 3, 'glyph00011': 2}
接着为了对应编码与数字,我们需要重新建立新的字体映射表。通过getBestCmap函数,获取对应字体的name与code之间的关系,由此我们可以得到映射表——键为编码,值为数字,需要注意的是由于getBestCmap()会将内容转化为10进制,因此在后面存入字典的时候需要转化为16进制。
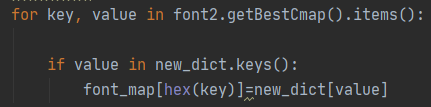
通过该映射表,我们可以轻松将获取地json数据相关部分转换为可读的数字。至此,我们就成功地解决了该网站的字体反爬。关于其他几个经典的字体反爬网站,可以参考专辑里面的文章~
——END——