
爬虫高级内容,Python如何应对字体反爬
前言
在编写网页爬虫的时候,我们经常会遇到各种反爬,比如js加密、css位置偏移、字体反爬等。最近在学习过程中,我碰到几个网站,都是使用的字体反爬,其大致上可以分为两类:一类是字体文件是静态的,另一类字体文件是动态的变化的。今天,我们探究一下,在爬虫中如何破解字体反爬。
一、如何寻找字体文件
字体文件大致上分两种,一种是以.ttf结尾的,一种是以.woff结尾的,两者相差不大,现在的网站运用的大多是woff文件。如何寻找网页使用的字体文件,可以分两类:
1.第一类 字体URL在网页源代码中
以aHR0cHM6Ly93d3cucmVucmVuY2hlLmNvbS9iai9lcnNob3VjaGUvP3Bsb2dfaWQ9NWI5NzA3MWI1YjVhNWZkYWRkOWZhZDEzMGE0MmJiMDM=网站为例:
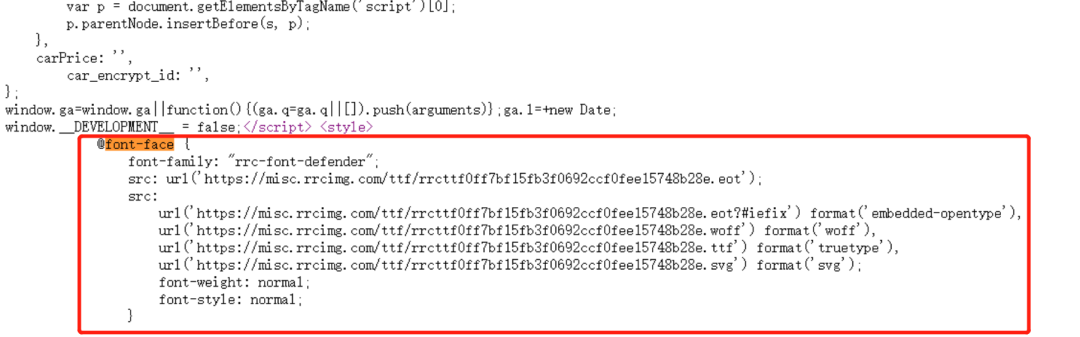
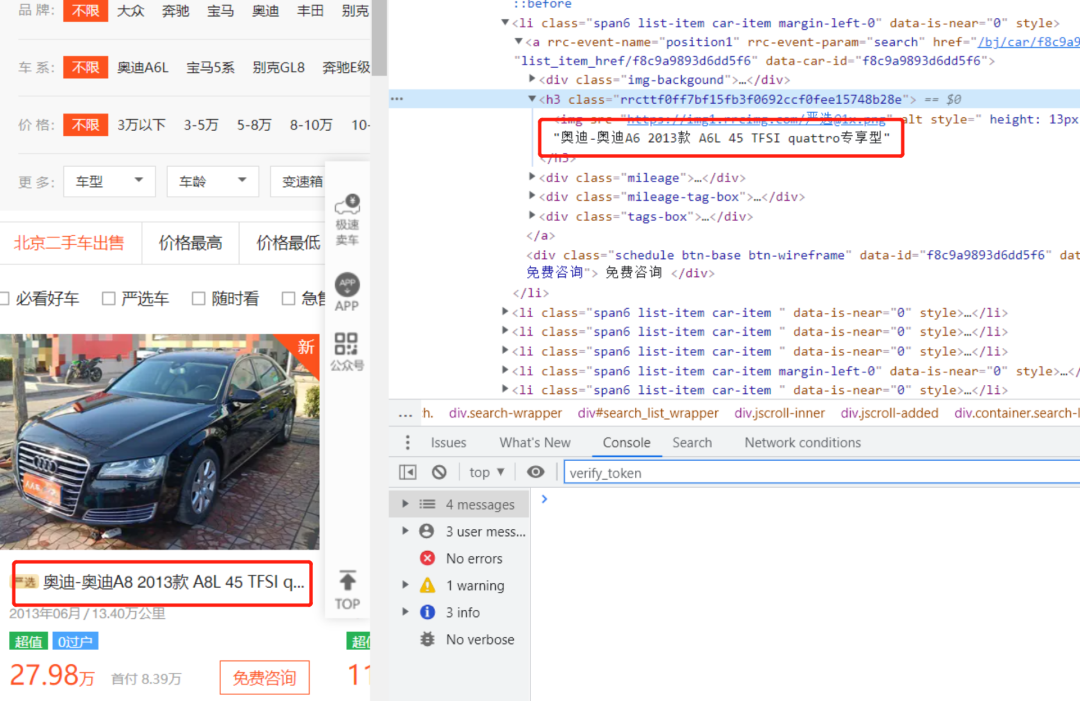 打开网站后,明显能看到,8被替换成了6。这种情况,我们可以尝试在网页源代码中搜索“font-face”,查看字体URL。
打开网站后,明显能看到,8被替换成了6。这种情况,我们可以尝试在网页源代码中搜索“font-face”,查看字体URL。
2.第二类 字体URL不在网页源代码中,由服务器加载
以aHR0cHM6Ly93d3cuZ3VhemkuY29tL2J1eQ==网站为例:
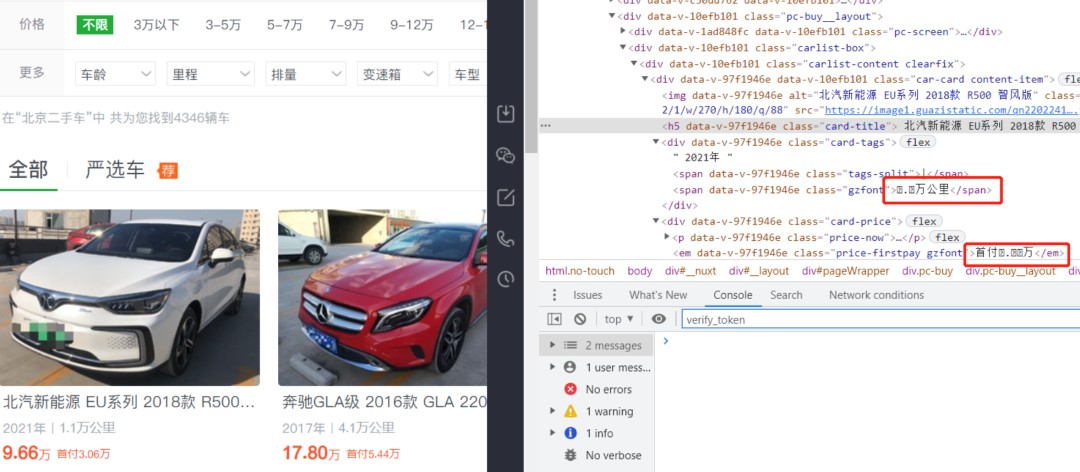 这里可以看到车辆的行使里程数和首付均是字体反爬,按照第一种情况,我们直接在网页源代码中搜索“font-face”
这里可以看到车辆的行使里程数和首付均是字体反爬,按照第一种情况,我们直接在网页源代码中搜索“font-face”
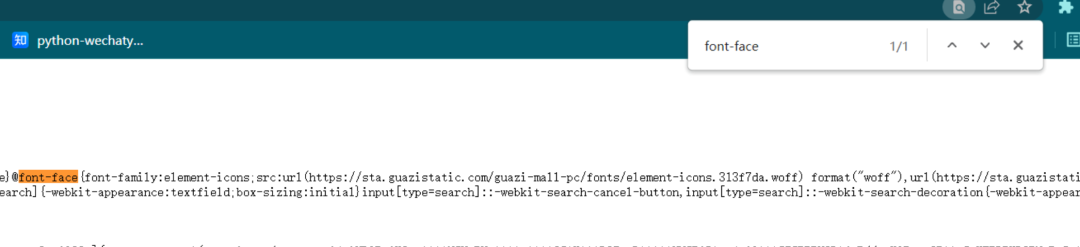 可以看到,也是有woff文件和ttf文件,但这两个文件都是“element-icons”的链接,打开(软件:FontCreator)后也就是一堆图标。
可以看到,也是有woff文件和ttf文件,但这两个文件都是“element-icons”的链接,打开(软件:FontCreator)后也就是一堆图标。
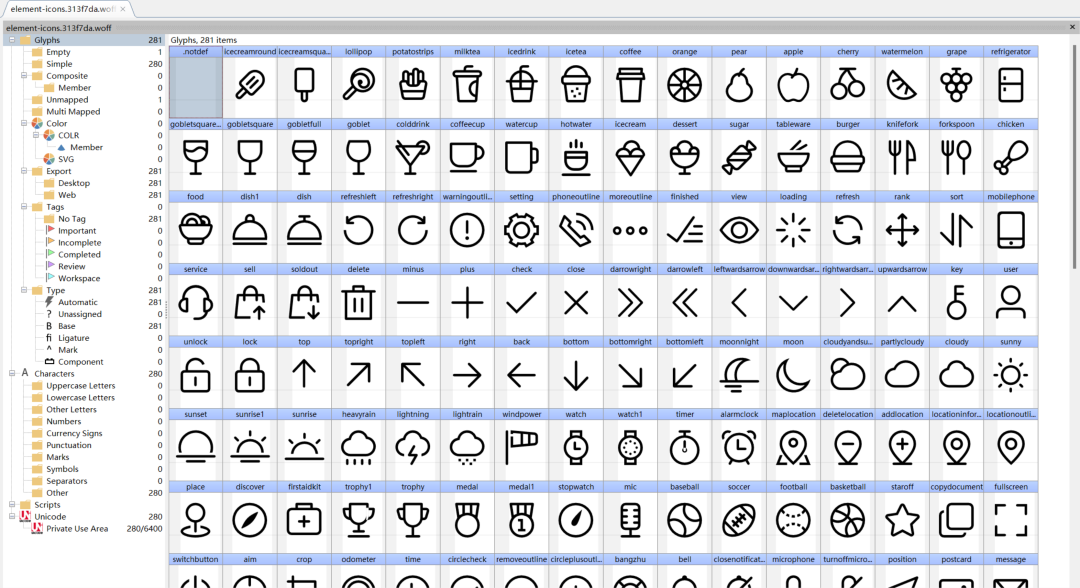 遇到这种的,可以打开浏览器Network,刷新后抓包。
遇到这种的,可以打开浏览器Network,刷新后抓包。
 可以看到这个请求返回的结果中有一个woff文件,打开后观察:
可以看到这个请求返回的结果中有一个woff文件,打开后观察:
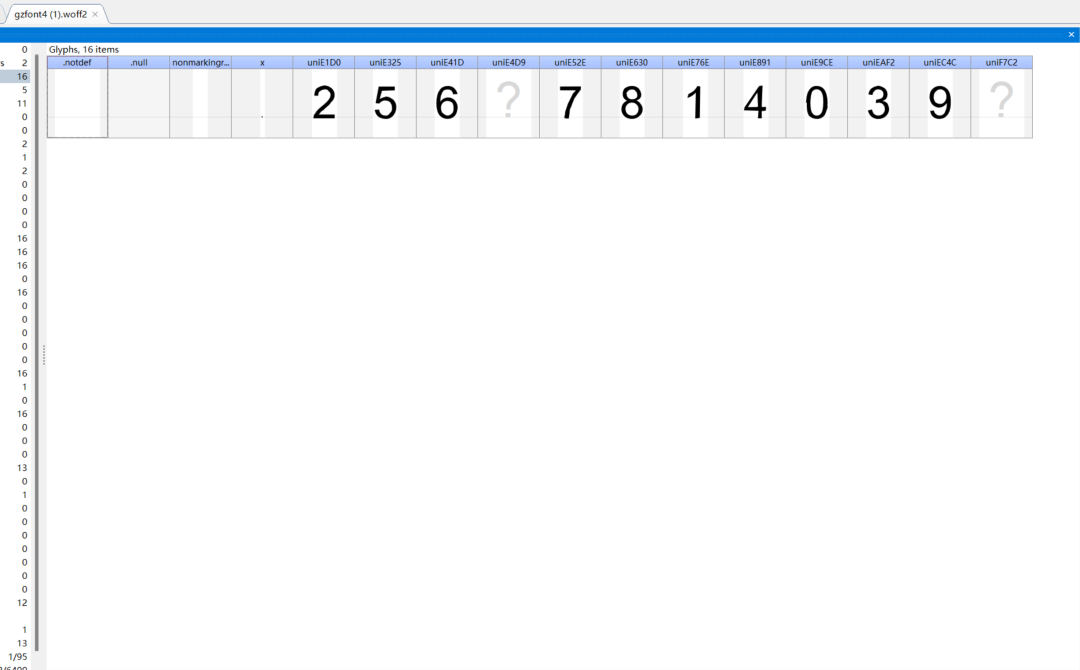
这个正是我们要找的字体文件,当然这个网站要拿到字体URL需要js逆向verify-token这个参数,这里不展开说。
二、如何应对静态字体反爬
还是以aHR0cHM6Ly93d3cucmVucmVuY2hlLmNvbS9iai9lcnNob3VjaGUvP3Bsb2dfaWQ9NWI5NzA3MWI1YjVhNWZkYWRkOWZhZDEzMGE0MmJiMDM=网站为例,经过观察,他的字体是每天更换一次,暂且当作是静态。
1.在网页源代码中搜索字体文件的URL,复制到浏览器中打开,下载字体文件。
2.用FontCreator打开文件,查看字体对应关系,手动建立对应关系字典。
# 字体对应关系
relation_table = {"zero": "0", "one": "2", "two": "1", "four": "3", "three": "4", "five": "8", "seven": "7","nine": "9", "six": "6", "eight": "5"}
这是我学习过程中自己手动建立的对应关系。
3.请求字体链接,获取字体code和name的对应关系,然后遍历,获取网页中反爬文字的真实文字。
def woff_font(font_url):
'''获取字体真实对应关系'''
newmap = {}
resp = session.get(font_url) # 请求字体链接
woff_data = BytesIO(resp.content)
font = TTFont(woff_data) # 读取woff数据
cmap = font.getBestCmap() # 获取字体对应关系
font.close()
for k, v in cmap.items():
value = v
key = str(k - 48) # 获取真实的key
try:
get_real_data = relation_table[value]
except:
get_real_data = ''
if get_real_data != '':
newmap[key] = get_real_data # 将字体真实结果对应
return newmap
4.替换网页中的反爬文字
如果反爬字体是10进制或16进制的建议直接替换网页代码中的字体,如果是数字的,建议逐项替换。替换的方式有用正则表达式的(这里不说,因为我正则写的也不好),也有用列表推导式的,比如:
title = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[1]/h1/text()')).strip() # 获取原始标题
trans_title = "".join([i if not i.isdigit() else font[i] for i in title]) # 替换错误字体,获取真实标题
具体的用法,可以百度。
三、如何应对动态字体反爬
动态字体反爬,就是每请求一次(或一段时间后),字体的映射关系也会改变,因为第二个网站比较麻烦,这个还是以这个网站为例,将时间节点放大,把他看做是动态反爬的。
1.先下载字体文件
2.安装fontTools
安装后用
from fontTools.ttLib import TTFont
font = TTFont(下载的字体文件)
font.saveXML(文件名.xml)
将字体文件另存为xml文件,打开文件后会看到:
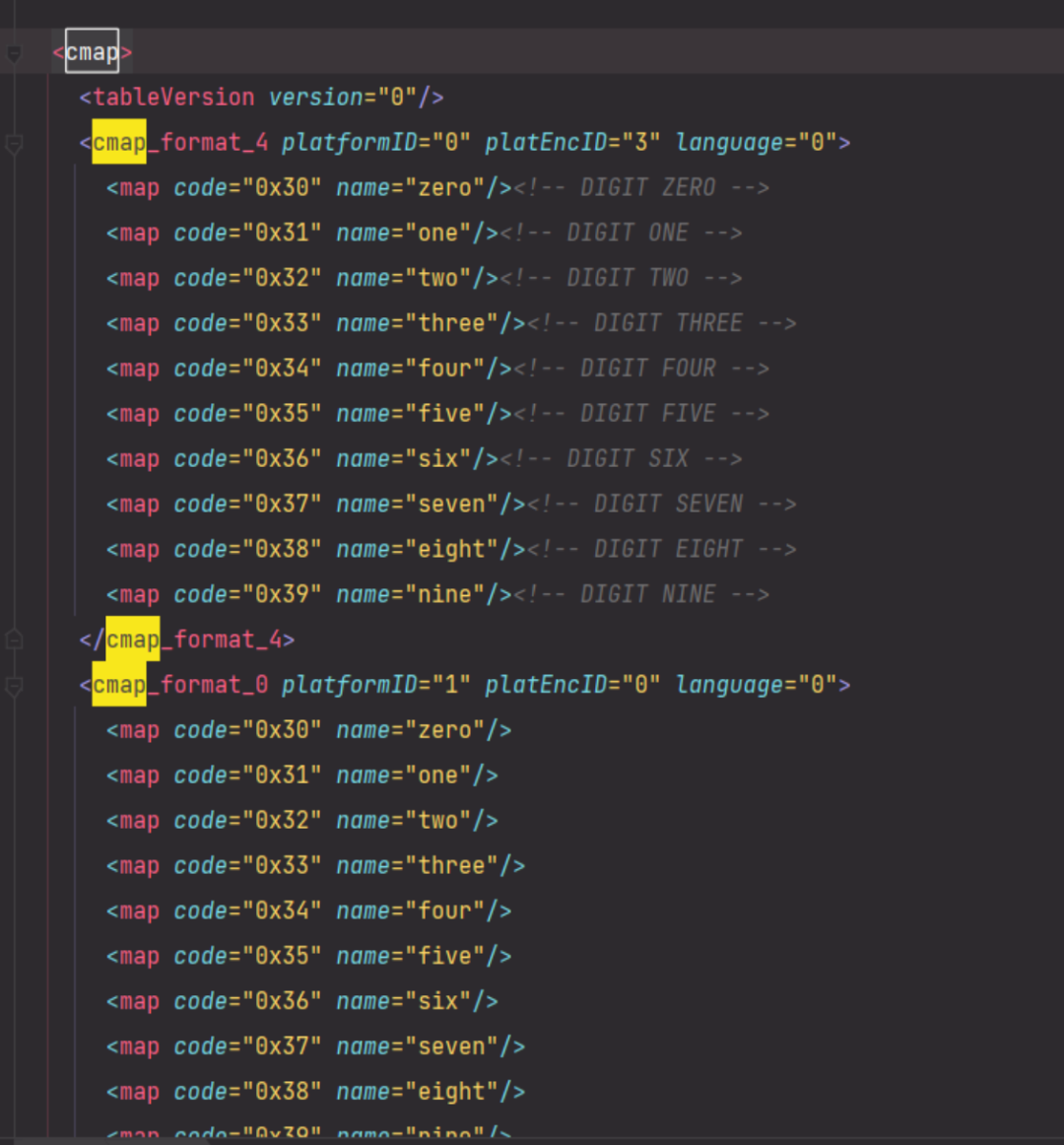 ‘cmap’里存放的是字体code和name的关系
‘cmap’里存放的是字体code和name的关系
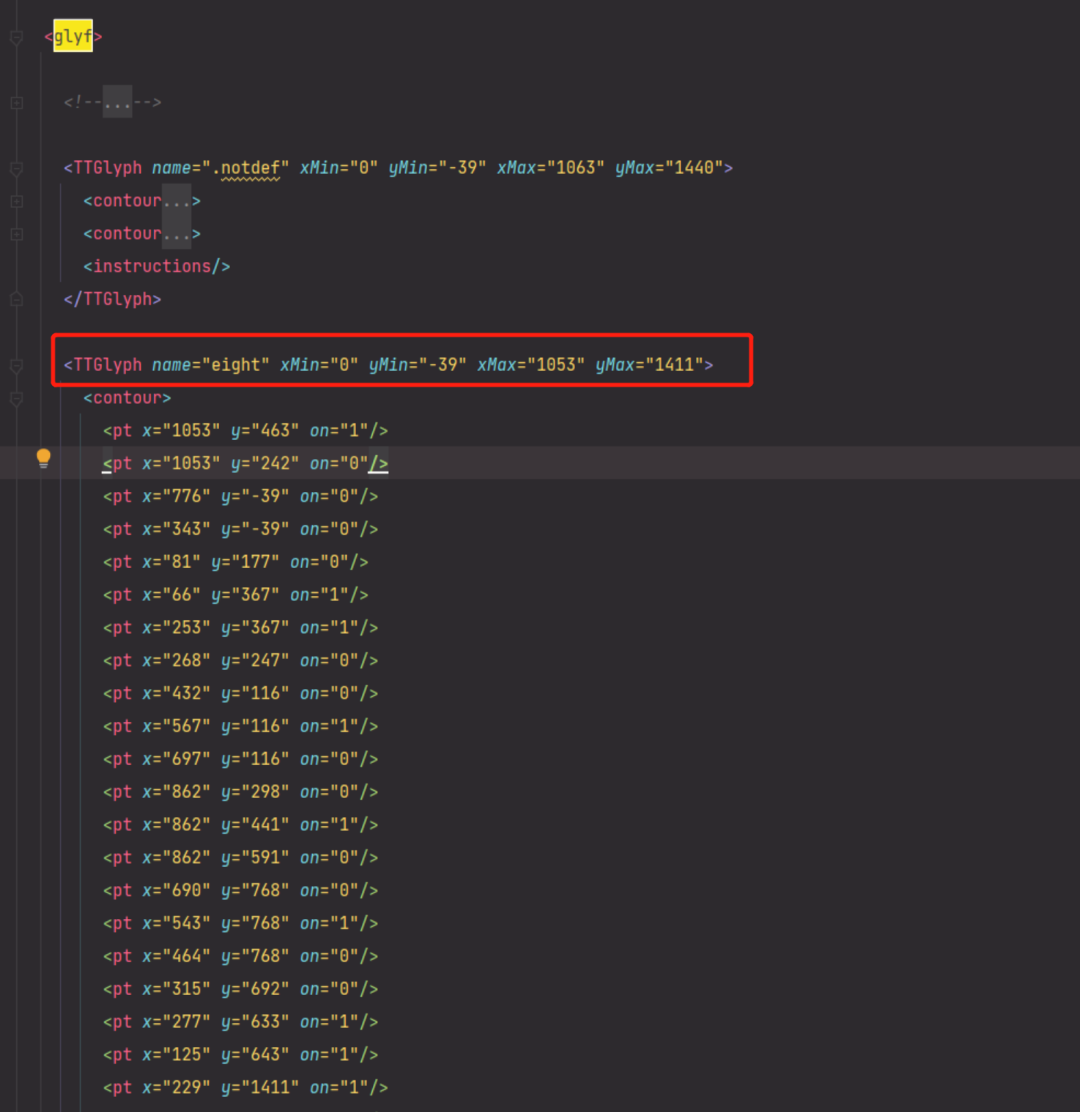
 ‘glyf’里存放的是字体形状和name的关系
‘glyf’里存放的是字体形状和name的关系
3.手动建立字体形状和name的关系
只需手动建立一次。
f_font = TTFont("rrcttf3d6e374d48fb2cd14247257d4ae76674.woff") # 读取分析的字体文件
f_font_glyf = f_font['glyf'] # 获取分析文件中的字体关系
# 建立基础的字体和字体形状的对应关系
base_font_map = {
0: f_font_glyf['zero'],
1: f_font_glyf['two'],
2: f_font_glyf['one'],
3: f_font_glyf['four'],
4: f_font_glyf['three'],
5: f_font_glyf['eight'],
6: f_font_glyf['six'],
7: f_font_glyf['seven'],
8: f_font_glyf['five'],
9: f_font_glyf['nine'],
}
4.请求网页中的字体URL,获取code和name,形状和name的关系
resp = session.get(font_url) # 请求字体链接
woff_data = BytesIO(resp.content) # 保存字体数据
font = TTFont(woff_data) # 读取woff数据
glyf = font['glyf'] # 获取请求到的字体形状
code_name_map = font.getBestCmap() # 获取请求到的字体code和name的对应关系
font.close()
5.根据形状相同,肯定字体相同的原则,获取真实对应关系
for code, name in code_name_map.items():
codestr = str(code - 48) # 根据分析结果需要减去48
current_shape = glyf[name] # 根据name获取字体形状
for number, shape in base_font_map.items(): # 遍历基础字体形状对应关系
if shape == current_shape: # 判断,如果两个字体形状相等
newmap[codestr] = str(number) # 将字体编码和字体添加到字典
6.完整代码
def woff_font(font_url):
newmap = {}
f_font = TTFont("rrcttf3d6e374d48fb2cd14247257d4ae76674.woff") # 读取分析的字体文件
f_font_glyf = f_font['glyf'] # 获取分析文件中的字体关系
# 建立基础的字体和字体形状的对应关系
base_font_map = {
0: f_font_glyf['zero'],
1: f_font_glyf['two'],
2: f_font_glyf['one'],
3: f_font_glyf['four'],
4: f_font_glyf['three'],
5: f_font_glyf['eight'],
6: f_font_glyf['six'],
7: f_font_glyf['seven'],
8: f_font_glyf['five'],
9: f_font_glyf['nine'],
}
resp = session.get(font_url) # 请求字体链接
woff_data = BytesIO(resp.content) # 保存字体数据
font = TTFont(woff_data) # 读取woff数据
glyf = font['glyf'] # 获取请求到的字体形状
code_name_map = font.getBestCmap() # 获取请求到的字体code和name的对应关系
font.close()
for code, name in code_name_map.items():
codestr = str(code - 48) # 根据分析结果需要减去48
current_shape = glyf[name] # 根据name获取字体形状
for number, shape in base_font_map.items(): # 遍历基础字体形状对应关系
if shape == current_shape: # 判断,如果两个字体形状相等
newmap[codestr] = str(number) # 将字体编码和字体添加到字典
return newmap
7.结果验证
当我在写这篇分享的时候,该网站的字体早已经换了,但是建立关系的时候我还用的是之前的文件,可见返回的结果也是没有问题的。



四、总结
静态字体反爬不用多说,面对动态反爬,一开始我也有点懵,后来在翻阅了一些资料和别人的启发后才弄明白,其实就是利用形状一样,字体肯定也一样的对应关系去破解。这是我学习过程中的一点经验总结,有不足之处还请各位指正,谢谢。
最后,推荐蚂蚁老师的视频套餐课程,包含爬虫部分,给我很大的帮助: