
从零开始深度学习Pytorch笔记(11)—— DataLoader类
 前文传送门:从零开始深度学习Pytorch笔记(1)——安装Pytorch从零开始深度学习Pytorch笔记(2)——张量的创建(上)从零开始深度学习Pytorch笔记(3)——张量的创建(下)从零开始深度学习Pytorch笔记(4)——张量的拼接与切分从零开始深度学习Pytorch笔记(5)——张量的索引与变换从零开始深度学习Pytorch笔记(6)——张量的数学运算从零开始深度学习Pytorch笔记(7)—— 使用Pytorch实现线性回归从零开始深度学习Pytorch笔记(8)—— 计算图与自动求导(上)
前文传送门:从零开始深度学习Pytorch笔记(1)——安装Pytorch从零开始深度学习Pytorch笔记(2)——张量的创建(上)从零开始深度学习Pytorch笔记(3)——张量的创建(下)从零开始深度学习Pytorch笔记(4)——张量的拼接与切分从零开始深度学习Pytorch笔记(5)——张量的索引与变换从零开始深度学习Pytorch笔记(6)——张量的数学运算从零开始深度学习Pytorch笔记(7)—— 使用Pytorch实现线性回归从零开始深度学习Pytorch笔记(8)—— 计算图与自动求导(上)
从零开始深度学习Pytorch笔记(9)—— 计算图与自动求导(下)从零开始深度学习Pytorch笔记(10)—— Dataset类
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)其中的参数含义为:dataset:加载的数据集(Dataset对象)batch_size:batch的大小shuffle::是否将数据打乱sampler:样本抽样num_workers:使用多进程加载的进程数,0代表不使用多进程collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last如果为True会将多出来不足一个batch的数据丢弃我们给出一个简单的DataLoader的例子:
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 20, 20)
y = torch.linspace(20, 1, 20)
torch_dataset = Data.TensorDataset(x, y)#创建Dataset
loader = Data.DataLoader(
dataset=torch_dataset,#数据
batch_size=BATCH_SIZE,#批次的大小
shuffle=True,#打乱数据
num_workers=2,#多进程
)
for epoch in range(3):#三个epoch
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
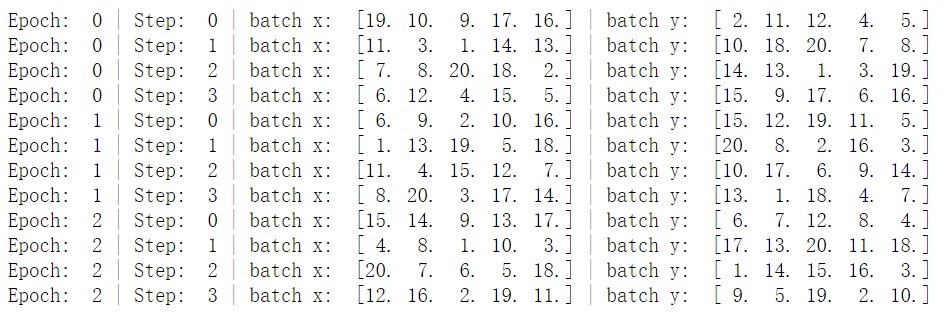 其中的一个epoch为将所有训练集训练一次的意思,而一个batch指的是将一批训练数据交给模型训练的意思。例如以上代码的batchsize为5,训练集一共20条数据,所以一个epoch分为4个batch(因为20/5=4)。在深度学习中,所有训练集并不是只有一次加入模型训练,所以会有多个epoch的情况。我们把batchsize改为4,并且把数据打乱设置为False,再看看结果:
其中的一个epoch为将所有训练集训练一次的意思,而一个batch指的是将一批训练数据交给模型训练的意思。例如以上代码的batchsize为5,训练集一共20条数据,所以一个epoch分为4个batch(因为20/5=4)。在深度学习中,所有训练集并不是只有一次加入模型训练,所以会有多个epoch的情况。我们把batchsize改为4,并且把数据打乱设置为False,再看看结果:import torch
import torch.utils.data as Data
BATCH_SIZE = 4
x = torch.linspace(1, 20, 20)
y = torch.linspace(20, 1, 20)
torch_dataset = Data.TensorDataset(x, y)#创建Dataset
loader = Data.DataLoader(
dataset=torch_dataset,#数据
batch_size=BATCH_SIZE,#批次的大小
shuffle=False,#打乱数据
num_workers=2,#多进程
)
for epoch in range(3):#三个epoch
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
 我们可以看到数据的batchsize变为了4,并且数据的输出是有序的,而深度学习中为了避免数据分布的干扰,一般都会讲数据打乱输入模型中!
我们可以看到数据的batchsize变为了4,并且数据的输出是有序的,而深度学习中为了避免数据分布的干扰,一般都会讲数据打乱输入模型中!欢迎关注公众号学习之后的深度学习连载部分~
历史文章推荐阅读:
从零开始学自然语言处理(四)—— 做 NLP 任务文本 id 化与预训练词向量初始化方法
从零开始学自然语言处理(三)——手把手带你实现word2vec(skip-gram)
从零开始学自然语言处理(二)——手把手带你用代码实现word2vec
从零开始学自然语言处理(一)—— jieba 分词
一文详解NLP语料构建技巧你不知道的Python环境管理技巧,超级好用!
Python快速安装库的靠谱办法你只会用Python的pip安装包?别错过这些好用功能!
扫码下图关注我们不会让你失望!

 喜欢记得点再看哦,证明你来看过~
喜欢记得点再看哦,证明你来看过~评论