
【从零开始学深度学习编译器】十二,MLIR Toy Tutorials学习笔记一
❝本笔记由学习MLIR Tutorials总结而成,欢迎批评指正。
Chapter1: Toy语言和AST
MLIR提供了一种Toy语言来说明MLIR的定义和执行的流程。Toy语言是一种基于张量的语言,我们可以使用它来定义函数,执行一些数学计算以及输出结果。下面要介绍的例子中限制Tensor的维度是<=2的,并且Toy语言中唯一的数据类型是64位浮点类型,对应C语言中的"double"。另外Values是不可以重写的,即每个操作都会返回一个新分配的值,并自动管理释放。直接看下面这个例子:
def main() {
# Define a variable `a` with shape <2, 3>, initialized with the literal value.
# The shape is inferred from the supplied literal.
var a = [[1, 2, 3], [4, 5, 6]];
# b is identical to a, the literal tensor is implicitly reshaped: defining new
# variables is the way to reshape tensors (element count must match).
var b<2, 3> = [1, 2, 3, 4, 5, 6];
# transpose() and print() are the only builtin, the following will transpose
# a and b and perform an element-wise multiplication before printing the result.
print(transpose(a) * transpose(b));
}
类型检查是通过类型推断静态执行的。Toy语言只需在必要时指定Tensor形状的类型声明。下面定义了一个multiply_transpose函数,注意这个函数里面参数a和b的形状我们预先都是不知道的,只有调用这个函数时我们才知道,可以关注一下下面例子中的shape变化。
# User defined generic function that operates on unknown shaped arguments.
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
# Define a variable `a` with shape <2, 3>, initialized with the literal value.
var a = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
# This call will specialize `multiply_transpose` with <2, 3> for both
# arguments and deduce a return type of <3, 2> in initialization of `c`.
var c = multiply_transpose(a, b);
# A second call to `multiply_transpose` with <2, 3> for both arguments will
# reuse the previously specialized and inferred version and return <3, 2>.
var d = multiply_transpose(b, a);
# A new call with <3, 2> (instead of <2, 3>) for both dimensions will
# trigger another specialization of `multiply_transpose`.
var e = multiply_transpose(b, c);
# Finally, calling into `multiply_transpose` with incompatible shape will
# trigger a shape inference error.
var f = multiply_transpose(transpose(a), c);
}
然后我们可以使用下面的命令来产生这个Toy语言程序的AST:
cd llvm-project/build/bin
./toyc-ch1 ../../mlir/test/Examples/Toy/Ch1/ast.toy --emit=ast
前提是要构建好llvm-project工程,构建过程按照https://mlir.llvm.org/getting_started/ 这里的方法操作即可,这里再列一下完整过程:
$ git clone https://github.com/llvm/llvm-project.git
$ mkdir llvm-project/build
$ cd llvm-project/build
$ cmake -G "Unix Makefiles" ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="host" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON
$ cmake --build . --target check-mlir
上面Toy程序产生的AST长下面这样:
Module:
Function
Proto 'multiply_transpose' @../../mlir/test/Examples/Toy/Ch1/ast.toy:4:1
Params: [a, b]
Block {
Return
BinOp: * @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:25
Call 'transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:10
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:20
]
Call 'transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:25
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:35
]
} // Block
Function
Proto 'main' @../../mlir/test/Examples/Toy/Ch1/ast.toy:8:1
Params: []
Block {
VarDecl a<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:11:3
Literal: <2, 3>[ <3>[ 1.000000e+00, 2.000000e+00, 3.000000e+00], <3>[ 4.000000e+00, 5.000000e+00, 6.000000e+00]] @../../mlir/test/Examples/Toy/Ch1/ast.toy:11:11
VarDecl b<2, 3> @../../mlir/test/Examples/Toy/Ch1/ast.toy:15:3
Literal: <6>[ 1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00] @../../mlir/test/Examples/Toy/Ch1/ast.toy:15:17
VarDecl c<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:3
Call 'multiply_transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:11
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:30
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:33
]
VarDecl d<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:3
Call 'multiply_transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:11
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:30
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:33
]
VarDecl e<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:3
Call 'multiply_transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:11
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:30
var: c @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:33
]
VarDecl f<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:3
Call 'multiply_transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:11
Call 'transpose' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:30
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:40
]
var: c @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:44
]
} // Block
AST的解析具体实现在mlir/examples/toy/Ch1/include/toy/Parser.h和mlir/examples/toy/Ch1/include/toy/Lexer.h中,感兴趣的读者可以看一下。我对这一块并不熟悉,就暂时不深入下去了,但这个AST看起来还是比较直观的,首先有两个Function对应了Toy程序里面的multiply_transpose和main,Params表示函数的输入参数,Proto表示这个函数在ast.toy文件中的行数和列数,BinOp表示transpose(a) * transpose(b)中的*是二元Op,并列出了左值和右值。其它的以此类推也比较好理解。
第一章就是简单介绍了一下Toy语言的几个特点以及Toy示例程序产生的AST长什么样子,如果对AST的解析感兴趣可以去查看代码实现。
Chapter2. 生成初级MLIR
MLIR 被设计成完全可扩展的基础框架,没有封闭的属性集、操作和类型。MLIR 通过Dialect(https://mlir.llvm.org/docs/LangRef/#dialects)的概念来支持这种可扩展性。Dialect在一个特定的namespace下为抽象提供了分组机制。
在MLIR里面,Operation是抽象和计算的核心单元,在许多方面与 LLVM 指定类似。具有特定于应用程序的语义,并且可以用于表示 LLVM 中的所有核心的 IR 结构:指令、globals(类似function)和模块。下面展示一个Toy语言产生的的transpose Operation。
%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
结构拆分解释:
%t_tensor:这个Operation定义的结果的名字,前面的%是避免冲突,见https://mlir.llvm.org/docs/LangRef/#identifiers-and-keywords 。一个Operation可以定义0或者多个结果(在Toy语言中,只有单结果的Operation),它们是SSA值。该名称在解析期间使用,但不是持久的(例如,它不会在 SSA 值的内存表示中进行跟踪)。"toy.transpose":Operation的名字。它应该是一个唯一的字符串,Dialect 的命名空间前缀为“.”。这可以理解为Toy Dialect 中的transpose Operation。(%tensor):零个或多个输入操作数(或参数)的列表,它们是由其它操作定义或引用块参数的 SSA 值。{ inplace = true }:零个或多个属性的字典,这些属性是始终为常量的特殊操作数。在这里,我们定义了一个名为“inplace”的布尔属性,它的常量值为 true。(tensor<2x3xf64>) -> tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。<2x3xf64>号中间的内容描述了张量的尺寸2x3和张量中存储的数据类型f64,中间使用x连接。loc("example/file/path":12:1):此操作的源代码中的位置。
了解了MLIR指令的基本结构后,我们把目光放到Chapter2要做什么事情上?即生成初级MLIR。我们执行下面的命令为Chapter2测试例子中的codegen.toy产生MLIR。
./toyc-ch2 ../../mlir/test/Examples/Toy/Ch2/codegen.toy -emit=mlir -mlir-print-debuginfo
其中codegen.toy的内容为:
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
var d = multiply_transpose(b, a);
print(d);
}
产生的MLIR为:
module {
func @multiply_transpose(%arg0: tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1), %arg1: tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1)) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:10)
%1 = toy.transpose(%arg1 : tensor<*xf64>) to tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:25)
%2 = toy.mul %0, %1 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:25)
toy.return %2 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:3)
} loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1)
func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":9:17)
%1 = toy.reshape(%0 : tensor<2x3xf64>) to tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":9:3)
%2 = toy.constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":10:17)
%3 = toy.reshape(%2 : tensor<6xf64>) to tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":10:3)
%4 = toy.generic_call @multiply_transpose(%1, %3) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":11:11)
%5 = toy.generic_call @multiply_transpose(%3, %1) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":12:11)
toy.print %5 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":13:3)
toy.return loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":8:1)
} loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":8:1)
} loc(unknown)
我们需要弄清楚codegen.toy是如何产生的MLIR文件。也即下图的AST到MLIR表达式那部分(包含Dialect)。
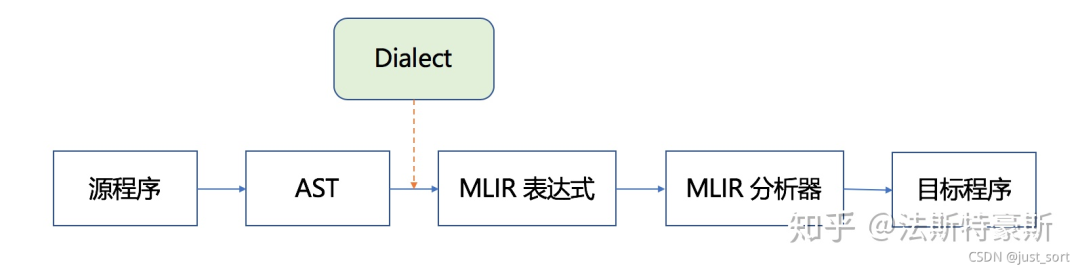
生成MLIR的流程
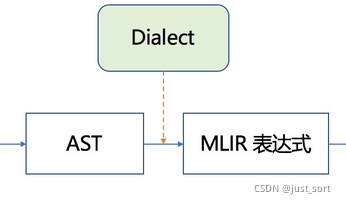
这里首先有一个MLIRGen函数负责遍历AST。具体在mlir/examples/toy/Ch2/mlir/MLIRGen.cpp文件中实现,里面有一个mlirGen函数,实现如下:
/// Dispatch codegen for the right expression subclass using RTTI.
mlir::Value mlirGen(ExprAST &expr) {
switch (expr.getKind()) {
case toy::ExprAST::Expr_BinOp:
return mlirGen(cast(expr));
case toy::ExprAST::Expr_Var:
return mlirGen(cast(expr));
case toy::ExprAST::Expr_Literal:
return mlirGen(cast(expr));
case toy::ExprAST::Expr_Call:
return mlirGen(cast(expr));
case toy::ExprAST::Expr_Num:
return mlirGen(cast(expr));
default:
emitError(loc(expr.loc()))
<< "MLIR codegen encountered an unhandled expr kind '"
<< Twine(expr.getKind()) << "'";
return nullptr;
}
}
这个函数会根据AST中的节点类型递归调用其它的mlirGen子函数,并在各个子函数完成真正的转换MLIR表达式的操作。以上面codege.toy的transpose(a)操作为例,对应的mlirGen子函数为:
/// Emit a call expression. It emits specific operations for the `transpose`
/// builtin. Other identifiers are assumed to be user-defined functions.
mlir::Value mlirGen(CallExprAST &call) {
llvm::StringRef callee = call.getCallee();
auto location = loc(call.loc());
// Codegen the operands first.
SmallVector4> operands;
for (auto &expr : call.getArgs()) {
auto arg = mlirGen(*expr);
if (!arg)
return nullptr;
operands.push_back(arg);
}
// Builtin calls have their custom operation, meaning this is a
// straightforward emission.
if (callee == "transpose") {
if (call.getArgs().size() != 1) {
emitError(location, "MLIR codegen encountered an error: toy.transpose "
"does not accept multiple arguments");
return nullptr;
}
return builder.create(location, operands[0]);
}
// Otherwise this is a call to a user-defined function. Calls to
// user-defined functions are mapped to a custom call that takes the callee
// name as an attribute.
return builder.create(location, callee, operands);
}
我们可以看到if (callee == "transpose")这里是对函数签名进行判断,如果是transpose 那么就需要新建一个TransposeOp类型的MLIR节点,即builder.create。这行代码涉及到MLIR的Dialect和TableGen,我们详细解释一下。
在【从零开始学深度学习编译器】十一,初识MLIR 中已经说过,MLIR是通过Dialect来统一各种不同级别的IR,即负责定义各种Operation和解析,同时还具有可扩展性。在Toy语言中我们也定义了Dialect,定义这个Dialect的时候是通过TableGen规范来定义到mlir/examples/toy/Ch2/include/toy/Ops.td中的。
// Provide a definition of the 'toy' dialect in the ODS framework so that we
// can define our operations.
def Toy_Dialect : Dialect {
let name = "toy";
let cppNamespace = "::mlir::toy";
}
在MLIR中,Dialect和Operation(也可以说算子)的定义是框架是基于TableGen(一种声明性编程语言)规范构造的,在源码中它以.td的格式存在,在编译时会自动生成对应的C++文件,生成定义好的Dialect。使用TableGen的好处不仅是因为它是声明性的语言让新增Dialect和Operation变得简单,而且容易修改和维护。可能我解释得不是很直观,但我们可以直接结合Chapter2的代码mlir/examples/toy/Ch2/include/toy/Ops.td 来理解。后面我们会看到在Toy语言的示例中,.td文件的组成以及TableGen是如何自动解析.td生成C++代码的。
这里首先在td中定义一下Toy Dialect,并建立和Dialect的链接,它负责将后续在Toy Dialect空间下定义的所有Operation联系起来。即:
// Provide a definition of the 'toy' dialect in the ODS framework so that we
// can define our operations.
def Toy_Dialect : Dialect {
let name = "toy";
let cppNamespace = "::mlir::toy";
}
然后构造一个Toy_Op类代表Toy Dialect下所有Operation的基类,后面新增Operation都需要继承这个类。
// Base class for toy dialect operations. This operation inherits from the base
// `Op` class in OpBase.td, and provides:
// * The parent dialect of the operation.
// * The mnemonic for the operation, or the name without the dialect prefix.
// * A list of traits for the operation.
class Toy_Op traits = []> :
Op;
下面给出transpose Operation的定义感受一下:
def TransposeOp : Toy_Op<"transpose"> {
let summary = "transpose operation";
let arguments = (ins F64Tensor:$input);
let results = (outs F64Tensor);
let assemblyFormat = [{
`(` $input `:` type($input) `)` attr-dict `to` type(results)
}];
// Allow building a TransposeOp with from the input operand.
let builders = [
OpBuilder<(ins "Value":$input)>
];
// Invoke a static verify method to verify this transpose operation.
let verifier = [{ return ::verify(*this); }];
}
在继承Toy_Op的基础上,还使用TableGen语法定义了描述信息,参数,值,builder,verfier这些元素。
编写完td文件之后,就可以使用mlir-tblgen工具生成C++代码,先使用下面的命令生成Dialect的C++代码:./mlir-tblgen -gen-dialect-decls llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td -I ../../mlir/include/
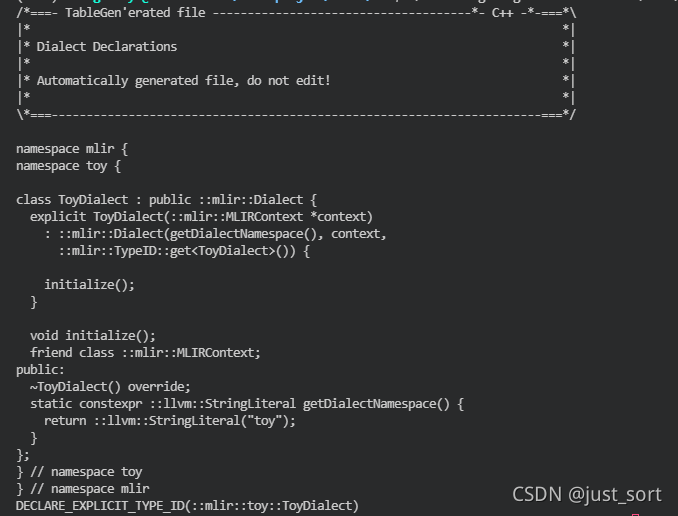
把上面的命令换成./mlir-tblgen -gen-op-defs llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td -I ../../mlir/include/ 就可以生成Operation的C++代码。感兴趣的读者可自行查看。
与工具链 toyc-ch2 的联系,查看CMakeList.txt 文件(默认位置为 llvm-project/mlir/examples/toy/Ch2/include/toy):
set(LLVM_TARGET_DEFINITIONS Ops.td)
mlir_tablegen(Ops.h.inc -gen-op-decls)
mlir_tablegen(Ops.cpp.inc -gen-op-defs)
mlir_tablegen(Dialect.h.inc -gen-dialect-decls)
mlir_tablegen(Dialect.cpp.inc -gen-dialect-defs)
add_public_tablegen_target(ToyCh2OpsIncGen)
使用mlir-tblgen搭配 -gen-op-decls 和 -gen-op-defs 选项,生成 Ops.h.inc 声明代码和 Ops.cpp.inc 定义代码,将两者作为构建工具链 toyc-ch2 的代码依赖。
总结一下,Chapter2主要介绍了MLIR中的MLIRGen,Dialect,Operation以及TableGen这几个MLIR的核心组成部分以及它们是如何相互作用的。它们的关系可以借用中科院Zhang Hongbin同学的PPT来更好的描述:

小结
这是阅读MLIR Toy Tutorials第一章和第二章的笔记,欢迎指出错误和不合理之处。