
前沿技术|联邦学习入门笔记




数据孤岛正阻碍着训练人工智能模型所必须的大数据的使用,同时为了确保用户隐私和数据安全,各组织间交换模型信息的过程将会被精心地设计,使得没有组织能够猜测到其他任何组织的隐私数据内容。
一种可行的方法是由每一个拥有数据源的组织训练一个模型,之后让各个组织在各自的模型上彼此交流沟通,最终通过模型聚合得到一个全局模型。
联邦学习是一种具有以下特征的用来建立机器学习模型的算法框架:
多方参与:有两个或以上的联邦学习参与方协作构建一个共享的机器学习模型。每一个参与方都拥有若干能够用来训练模型的训练数据。
本地计算:在联邦学习模型的训练过程中,每一个参与方拥有的数据都不会离开该参与方,即数据不离开数据拥有者。
加密消息:联邦学习模型相关的信息能够以加密方式在各方之间进行传输和交换,并且需要保证任何一个参与方都不能推测出其他方的原始数据。
联邦性能:联邦学习模型的性能要能够充分逼近理想模型(是指通过将所有训练数据集中在一起并训练获得的机器学习模型)的性能。
值得注意的是,联邦学习的性能允许比数据集中训练模型的性能稍差,对于联邦学习,确保用户数据的安全性和隐私保护比模型性能更有价值。
如果使用安全的联邦学习在分布式数据源上构建机器学习模型,这个模型在未来数据上的性能近似于把所有数据集中到一个地方训练所得到的模型的性能。
协调方是一台聚合服务器,在联邦学习过程中负责模型参数的“分发”和“聚合”。在这种模式下,参与方的原始数据永远不会离开自己。
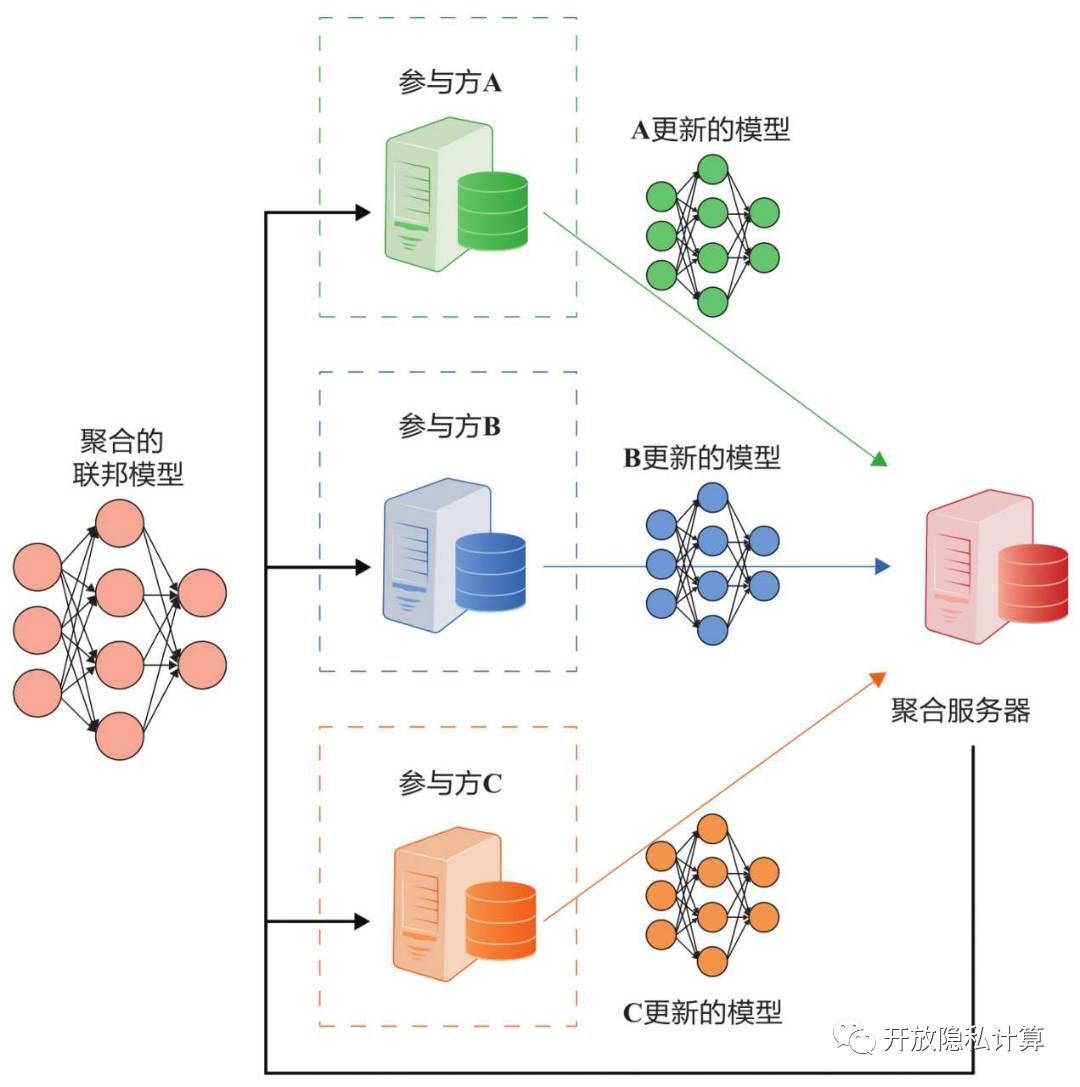
C/S架构
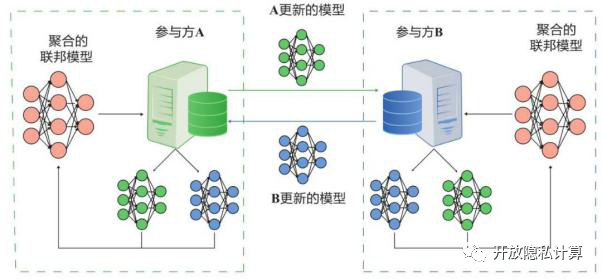
P2P架构
联邦学习的优点:
保护用户的隐私和数据安全。
允许若干参与方协同训练一个机器学习模型,使得各参与方获得一个优于自己训练的模型。
有效解决“数据孤岛”问题,应用领域广泛,如检测多方借贷风险、医疗健康诊断等。
商业潜力巨大,3-5年内进入行业蓝海。
联邦学习的挑战:
系统开销大,加密和解密消耗大多数计算资源。
参与方数据的统计学分布不均,造成联邦训练模型与实际情况存在较大偏差。
联邦学习的参与方与协调方地理位置分散,难以被认证身份,系统容易遭到恶意攻击,破环联邦模型的可用性。
参与方协同训练的激励策略存在公平性问题。
联邦学习的知识组成:
机器学习
分布式计算
密码学与网络安全
区块链共识机制
隐私保护数据挖掘
同态加密
差分隐私
多方安全计算
博弈论与经济学原理
数据安全相关法律
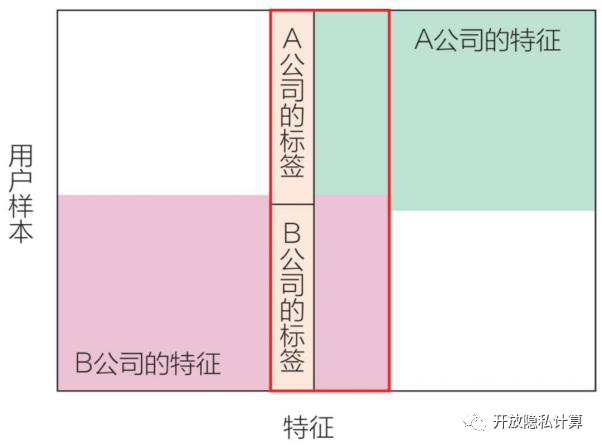
举例:业务规模相似的两个不同地区的电信运营商,各自持有当地的用户数据,因为其分布在不同的区域,所以用户重叠较少,但是由于业务相似,因此特征空间的重叠区域较大。
纵向联邦学习
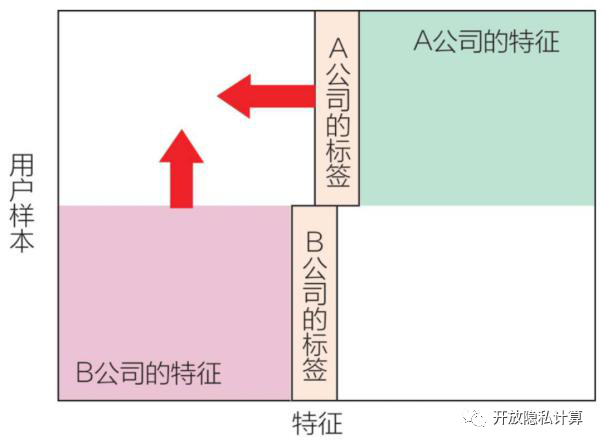
纵向联邦学习的主要应用场景为用户特征部分重叠较少,但是用户样本部分重叠较多。简单来说,纵向联邦学习根据特征维度进行切分,是一种基于特征维度的联邦学习方式。
举例:公司A作为数据提供方,拥有大量用户的行为特征和部分信贷数据;信贷公司拥有大量的用户信贷数据。现在对公司A数据和信贷公司数据中同一批用户进行联邦建模,就属于纵向联邦学习。
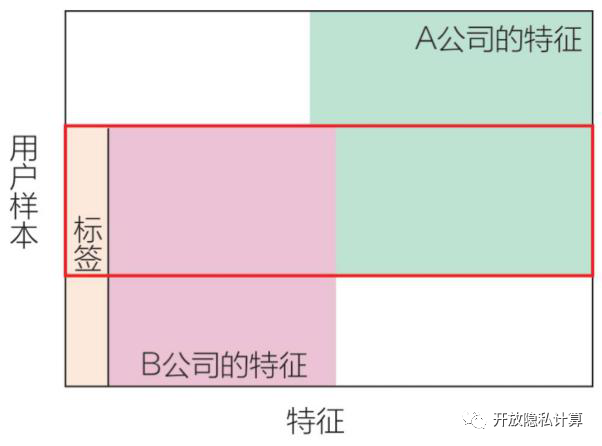
联邦迁移学习
联邦迁移学习的主要应用场景为用户特征部分和用户样本部分重叠均较少。
举例:假设现在有中国某银行的数据集和美国某外卖公司的数据集,因为在不同的国家,所以用户的交叉很少。因为银行业务和外卖公司业务相差很大,所以用户特征的交叉也很少。如果用户需要进行有效的联邦建模,就需要借助迁移学习技术,解决单边数据缺乏或者标签少的问题,从而更有效地进行联邦模型训练。
内容来源:开放隐私计算公众号
数据科学与人工智能公众号创建了机器学习群,添加我的微信,备注:姓名-ML,邀请你加入机器学习群,一起学习和进步。
[1]杨强,刘洋,程勇,等.联邦学习[M].电子工业出版社:北京,2020:2.
[2]彭南博,王虎.联邦学习技术及实战[M].电子工业出版社:北京,2021:2-.