
【机器学习】4 款超级棒的模型可解释性工具包,总有一款适合你!
近年来机器学习模型可解释性成为大家关注的热点,我们不再满足于模型效果,而是对模型效果的产生原因有了更多的思考,这样的思考不仅有助于模型和特征优化,也能更好的帮助理解模型本身和提升模型服务质量。
算法通常被看成黑盒子模型,训练数据流入黑盒子,训练出一个函数(这个函数也可以称之为模型),输入新的数据到该函数得出预测结果。对于算法给出的预测结果,其实很多人内心都会有质疑:"WHY?"
这就是为什么我们要拥有模型可解释性。
什么是模型可解释性?
模型可解释性试图理解和解释响应函数所做出的这些决定,即what,why以及how。通常,机器学习模型通过预测,并使用这些预测解决一系列问题。我们会有如下疑问:
这些预测的可信度如何? 他们足够可靠地做出重大决策吗?
模型可解释性将你的注意力从"结论是什么?"转到"为什么得出这个结论?"。
为什么模型可解释性很重要?
以一个分类器的示例:哈士奇与狼的分类问题,其中一些哈士奇犬被错误分类为狼。使用可解释的机器学习,你可能会发现这些错误分类主要是由于图像中的雪而引起的,分类器将其用作预测狼的特征。
模型可解释性对于验证模型结果是否符合你的期望是很有必要的。它不仅可以与业务方建立信任关系,推动项目继续进行下去,而且可以结果来改善模型性能本身。
如何解释机器学习模型?
为方便大家理解,让我们创建一个模型,引入随机森林分类器,并对模型进行训练、预测。
#训练
From sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(train_X,y)
#预测
testpred = rfc.predict(test_X)
模型可解释工具
我们已经建立了模型,现在是时候介绍、使用「4种」可解释工具了。
1、ELI5
我们先从最流行的工具之一ELI5开始。ELI5 是一个 Python 软件包,可帮助调试机器学习分类器并解释其预测。它可以为以下机器学习框架和软件包提供支持:
scikit-learn Keras xgboost LightGBM CatBoost sklearn-crfsuite
ELI5 安装方法
pip install eli5
# 或
conda install -c conda-forge eli5
ELI5 使用方法
import eli5
eli5.show_weights(rfc)
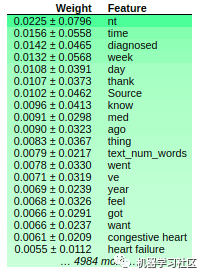
更多使用技巧,文档参考如下:
https://eli5.readthedocs.io/en/latest/
2、LIME
在机器学习模型事后局部可解释性研究中,一种代表性方法是由 Marco Tulio Ribeiro 等人提出的 Local Interpretable Model-Agnostic Explanation(LIME)。
一般地,对于每一个输入实例,LIME首先利用该实例以及该实例的一组近邻数据训练一个易于解释的线性模型来拟合待解释模型的局部边界,然后基于该线性模型解释待解释模型针对该实例的决策依据,其中,线性模型的权重系数直接体现了当前决策中该实例的每一维特征重要性。
LIME 安装方法
pip install lime
# 或
conda install -c conda-forge lime
LIME 使用方法
LIME主要提供三种解释方法,这三种方法都处理不同类型的数据:
表格解释 文字翻译 图像解释。
我们将使用Lime的文本解释方法。
rfc.fit(vectorized_train_text,y)
Import lime
From sklearn.pipeline import make_pipeline
explainer = lime.lime_text.LimeTextExplainer(
class_names=["Not Patient", "Patient"])
pl = make_pipeline(vect,rfc)
exp = explainer.explain_instance(
train["combined_text"][689], pl.predict_proba)
exp.show_in_notebook()

更多使用技巧,文档参考如下:
https://github.com/marcotcr/lime
3、SHAP
SHAP(SHapley Additive exPlanations)是一种博弈论方法,用于解释任何机器学习模型的输出。它使用博弈论中的经典Shapley值及其相关扩展将最佳信用分配与本地解释联系起来。
SHAP 安装方法
pip install shap
or
conda install -c conda-forge shap
SHAP 使用方法
import xgboost
import shap
# train an XGBoost model
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
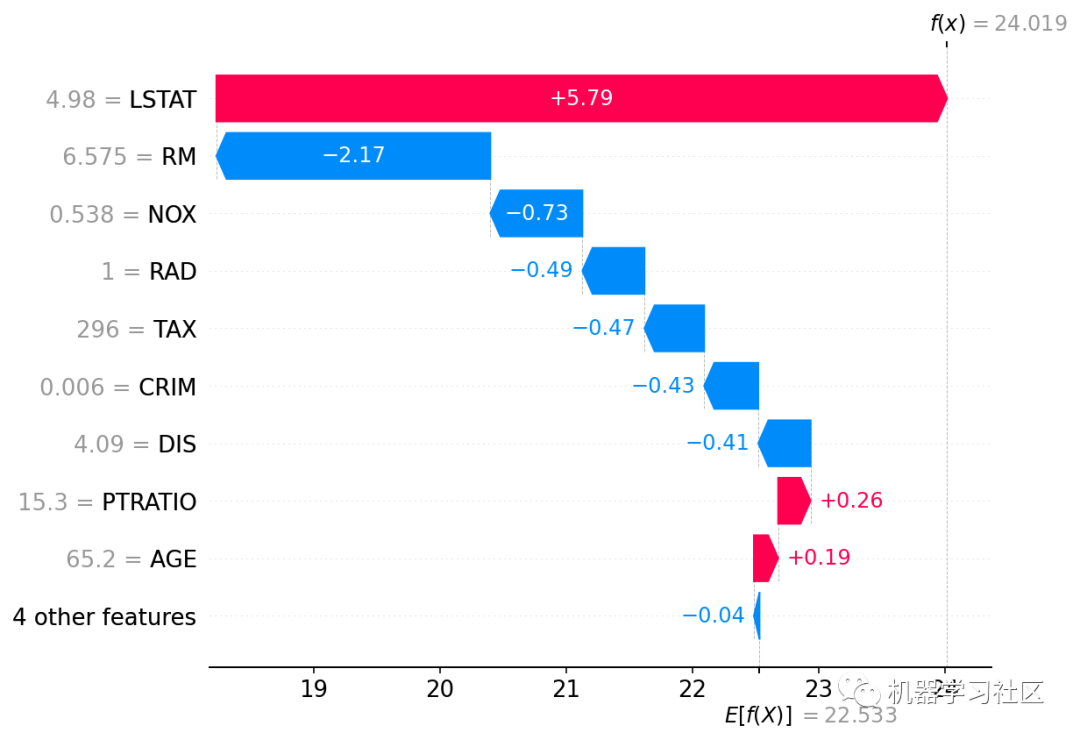
上面的解释显示了每个功能都有助于将模型输出从基值推向模型输出的功能。推高预测的特征以红色显示,推低预测的特征以蓝色显示。可视化相同解释的另一种方法是使用力图:
# visualize the first prediction's explanation with a force plot
shap.plots.force(shap_values[0])

更多使用技巧,文档参考如下:
https://github.com/slundberg/shap
4、MLXTEND
Mlxtend(机器学习扩展)是一个用于数据科学和机器学习任务的非常有用 Python 工具库。
MLXTEND 安装方法
pip install mlxtend
or
conda install -c conda-forge mlxtend
MLXTEND 使用方法
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
['Logistic Regression', 'Random Forest', 'RBF kernel SVM', 'Ensemble'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()
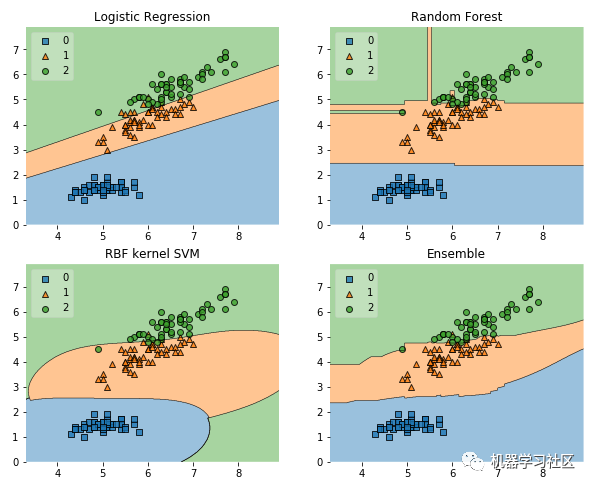
更多使用技巧,文档参考如下:
https://github.com/rasbt/mlxtend
往期精彩回顾
本站qq群851320808,加入微信群请扫码: