
关于机器学习模型的可解释性算法!

来源:Datawhale 本文约1400字,建议阅读5分钟
本文介绍目前常见的几种可以提高机器学习模型的可解释性的技术。
Partial Dependence Plot (PDP);
Individual Conditional Expectation (ICE)
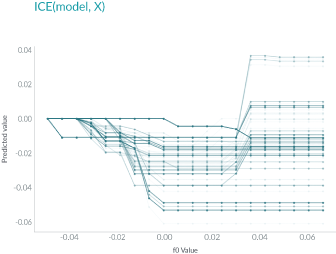
Permuted Feature Importance
Global Surrogate
Local Surrogate (LIME)
Shapley Value (SHAP)
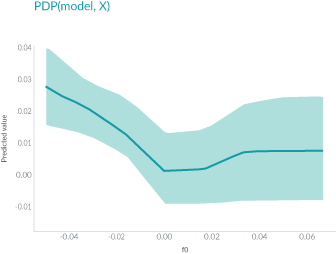
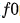 的值y轴表示预测值。阴影区域中的实线显示了平均预测如何随值的变化而变化。PDP能很直观地显示平均边际效应,因此可能会隐藏异质效应。
的值y轴表示预测值。阴影区域中的实线显示了平均预测如何随值的变化而变化。PDP能很直观地显示平均边际效应,因此可能会隐藏异质效应。例如,一个特征可能与一半数据的预测正相关,与另一半数据负相关。那么PDP图将只是一条水平线。
首先,我们使用经过训练的黑盒模型对数据集进行预测; 然后我们在该数据集和预测上训练可解释的模型。
注:代理模型可以是任何可解释的模型:线性模型、决策树、人类定义的规则等。
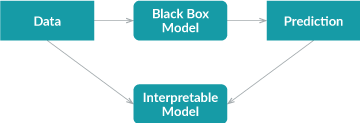
由于代理模型仅根据黑盒模型的预测而不是真实结果进行训练,因此全局代理模型只能解释黑盒模型,而不能解释数据。
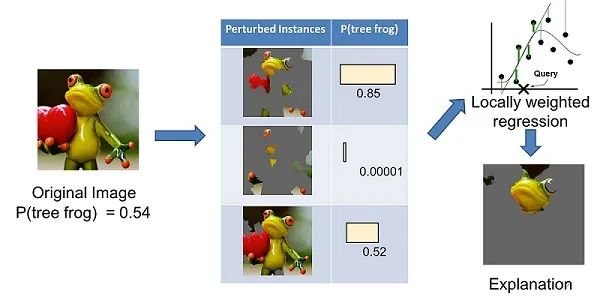

https://www.twosigma.com/articles/interpretability-methods-in-machine-learning-a-brief-survey/
编辑:于腾凯
校对:林亦霖
评论