
两步帮你快速选择SKlearn机器学习模型
Scikit-learn,简称Sklearn,是使用最广泛的开源Python机器学习库。它基于Numpy和Scipy,提供了大量用于数据挖掘和机器学习分析、预测的工具,包括数据预处理、可视化、交叉验证和多种机器学习算法。其中提供的模型能够实现分类,回归,聚类,数据降维等功能。
Sklearn是解决实际问题的一种工具,但面对机器学习问题时,最难的部分其实并不是缺乏工具,而是如何为具体项目找到合适的模型。
此处举2个案例。
案例1:老板丢给你20万个客户的淘宝网店购物记录,让你预测其中客户未来的一年内的生命周期价值LTV(Life TimeValue),用Scikit-learn中的哪个模型?
案例2:老板丢给你1000个客户的下载、注册、使用和卸载App的行为记录,让你预测其中一些客户未来3个月内流失的可能性,用Scikit-learn中的哪个模型?
Sklearn中的机器学习模型这么多,怎么知道哪个模型适合处理什么类型的数据,解决什么样的问题呢?
步骤1:找到Sklearn官网提供的“工具选择流程图”。只要带着问题,跟着图往下走,就能够找到答案。
此处整理了中文版本,便于大家阅读。
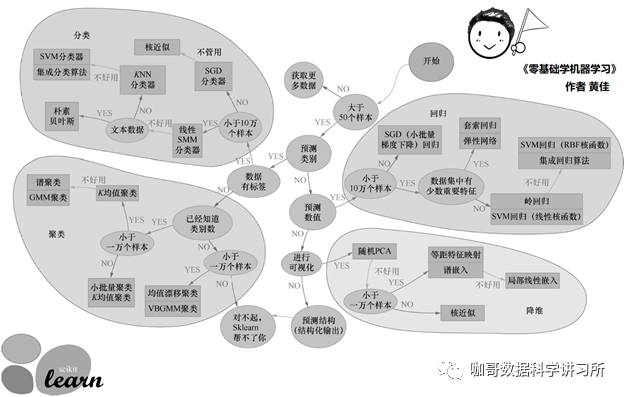
步骤2:跟着图分解自己的案例。
以案例1为例:
从上图的“开始”往下走,进入“大于50个样本”环节;
然后判断为“Yes”,进入“预测类别”环节;
这里是预测价值,明显不是类别,跟着No进入“预测数值”环节;
然后进入“小于10万个样本”环节,
我们这里有20万个样本,因此跟着No进入“SGD(小批量梯度下降)回归”模型——找到合适的模型啦!!
如果你是程序员,有时候会希望用程序化的方法进行模型的选择,可以参考如下伪代码:
IF数据量少于50个
数据样本太少了,先获取更多数据吧!!
ELSE数据量多于过50个
IF是分类问题
IF数据有标签
IF数据量大于10万,
选择SGD分类器
ELSE数据量大于10万,
先尝试线性SVM分类器,如果不好用,再继续尝试其他算法
IF特征为文本,
选择朴素贝叶斯SVM
ELSE,
先尝试kNN,如果不好用,尝试SVM加集成方法
ELSE数据没有标签,
选择各种聚类算法
ELSE不是分类问题,
IF需要预测数量,就是回归问题
IF数据量大于10万,
就选择SGD线性回归
ELSE,
根据数据集特征的特点,有Lasso回归和Ridge回归、集成方法、SVM等几种选择。
ELSE如果是要把数据可视化,
则考虑等几种降维方法
ELSE 如果是要输出数据的结构
对不起,Sklearn帮不了你
——上面的内容节选并整理自《零基础学机器学习》
如果SKlearn中的模型都帮不到你的话,那么就需要考虑深度学习库了,这一方法以后的文章会讲到。
此外,选取多种算法模型去解决同一个问题,然后将各种算法的效率进行比较,也不失为一个好的方案。
那么,最后的问题来了,对于案例2,应该选择哪个Sklearn模型呢?请你试一试,并在文末留言说明你的模型选择流程,我们会抽一位答对的读者赠送一本刚出版的热门机器学习新书《零基础学机器学习》呦。
《零基础学机器学习》,通过AI“小白”小冰拜师程序员咖哥学习机器学习的对话展开,内容轻松,实战性强,主要包括机器学习快速上手路径、数学和Python基础知识、机器学习基础算法(线性回归和逻辑回归)、深度神经网络、卷积神经网络、循环神经网络、经典算法、集成学习、无监督和半监督等非监督学习类型、强化学习实战等内容,以及相关实战案例。本书所有案例均通过Python及Scikit-learn机器学习库和Keras 深度学习框架实现,同时还包含丰富的数据分析和数据可视化内容。
本书适合对AI 感兴趣的程序员、项目经理、在校大学生以及任何想以零基础学机器学习的人,用以入门机器学习领域,建立从理论到实战的知识通道。
也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
干掉 LaTeX !用BookDown写本书 101道Numpy、Pandas练习题 【资源干货】香港中文大学《深度学习导论》2021课件 机器学习深度研究:特征选择中几个重要的统计学概念 老铁,三连支持一下,好吗?↓↓↓