
综述论文:机器学习中的模型评价、模型选择与算法选择!
本论文回顾了用于解决模型评估、模型选择和算法选择三项任务的不同技术,并参考理论和实证研究讨论了每一项技术的主要优势和劣势。进而,给出建议以促进机器学习研究与应用方面的最佳实践。

评估模型的泛化性能,即模型泛化到未见过数据的能力;
通过调整学习算法和在给定的假设空间中选择性能最优的模型,以提升预测性能;
确定最适用于待解决问题的机器学习算法。因此,我们可以比较不同的算法,选择其中性能最优的模型;或者选择算法的假设空间中的性能最优模型。
虽然上面列出的三个子任务都是为了评估模型的性能,但是它们需要使用的方法是不同的。本文将概述解决这些子任务需要的不同方法。
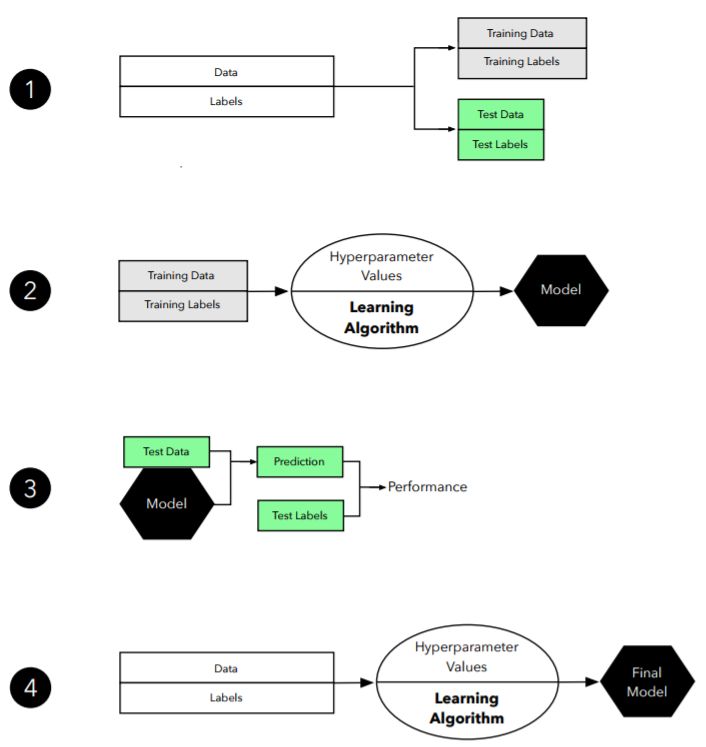
我们想评估泛化准确度,即模型在未见数据上的预测性能。
我们想通过调整学习算法、从给定假设空间中选择性能最好的模型,来改善预测性能。
我们想确定手头最适合待解决问题的机器学习算法。因此,我们想对比不同的算法,选出性能最好的一个;或从算法的假设空间中选出性能最好的模型。



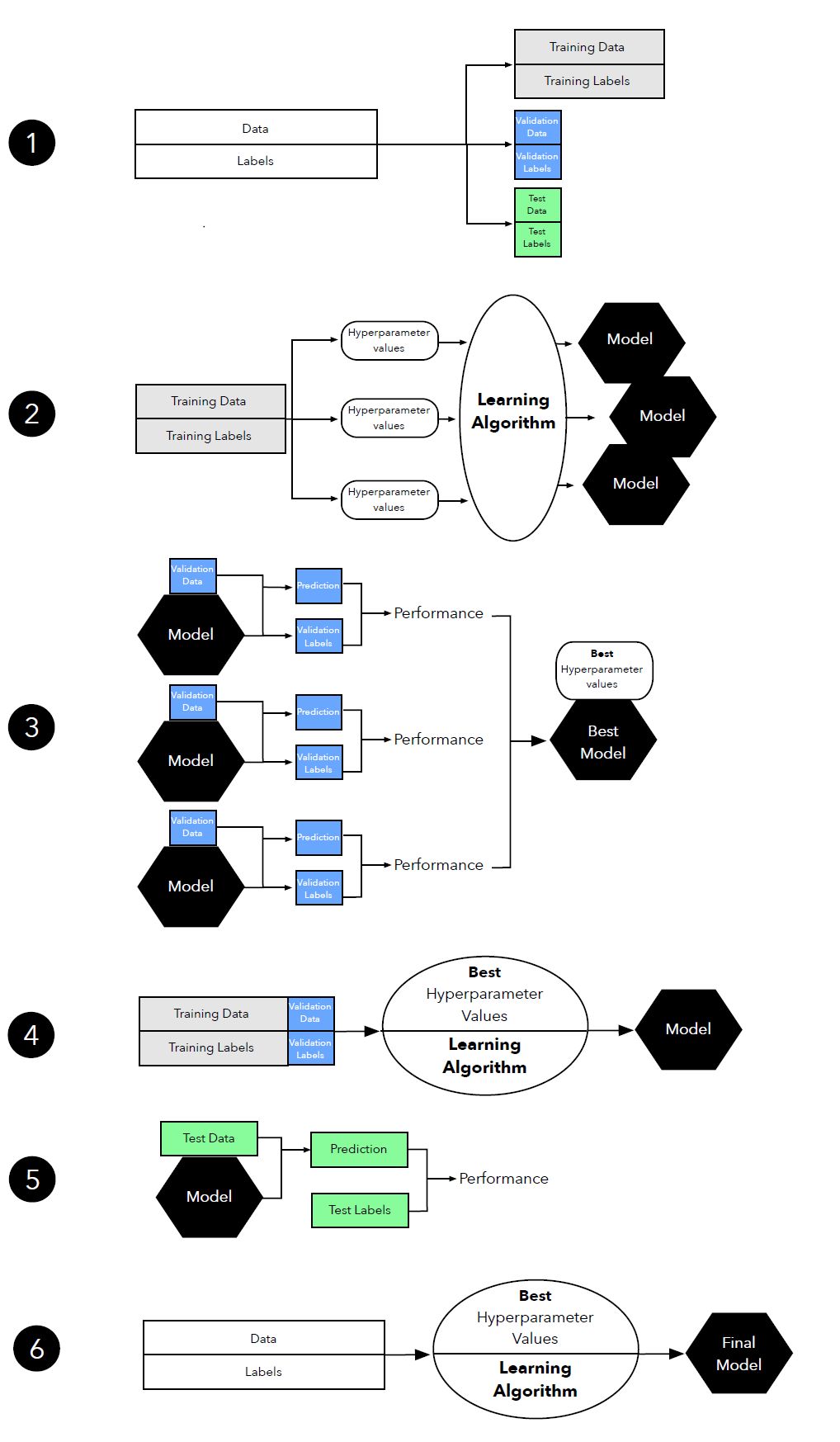
我们想评估泛化准确度,即模型在未见数据上的预测性能。
我们想通过调整学习算法、从给定假设空间中选择性能最好的模型,来改善预测性能。
我们想确定最适合待解决问题的机器学习算法。因此,我们想对比不同的算法,选出性能最好的一个,从算法的假设空间中选出性能最好的模型。

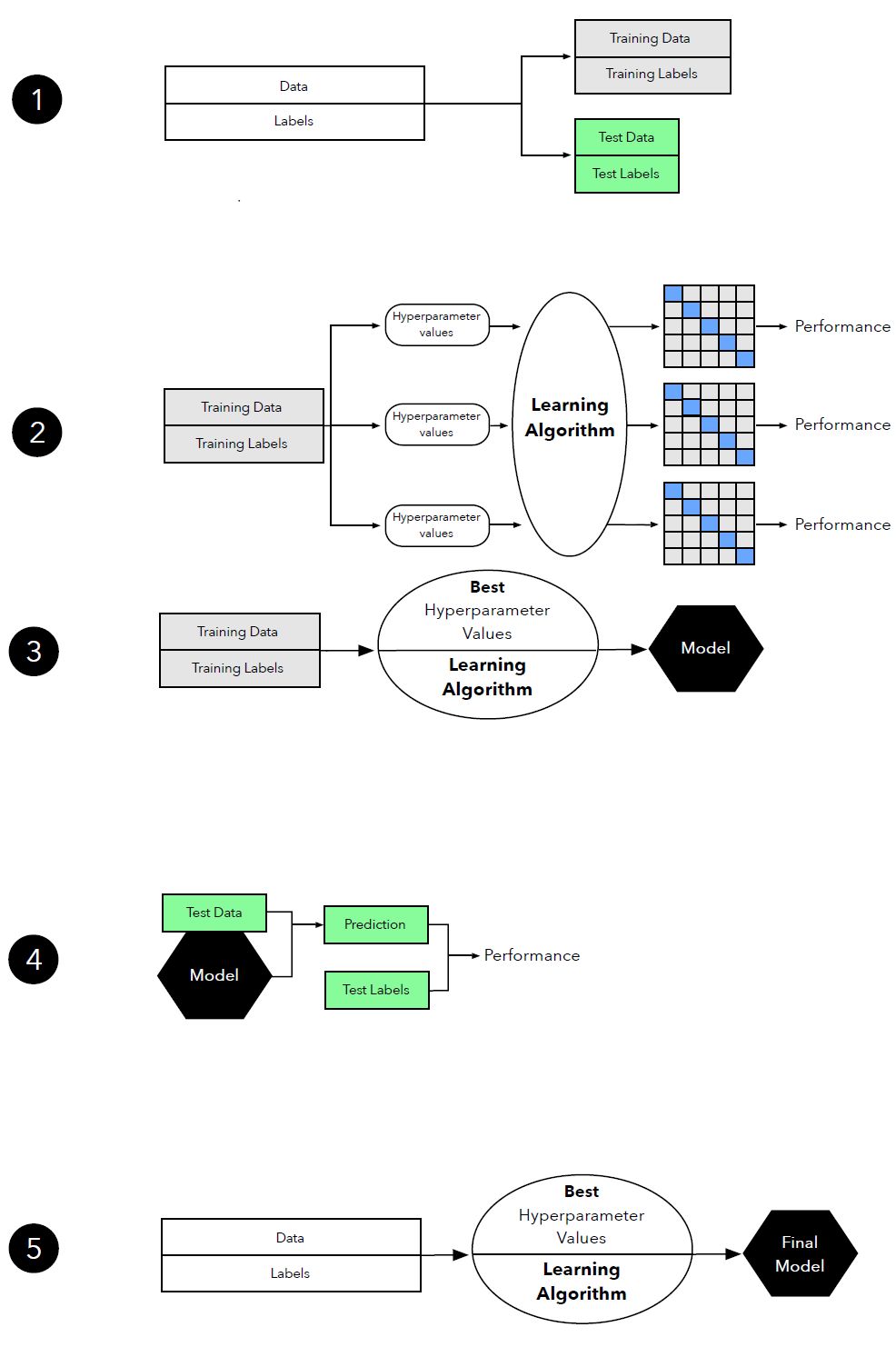
评论