
4种不同类别的机器学习概述
导读:机器学习涉及方方面面的内容,包含许多不同类型的算法,其学习方式也不相同。我们将简要介绍这些学习方式及其对应的情景。
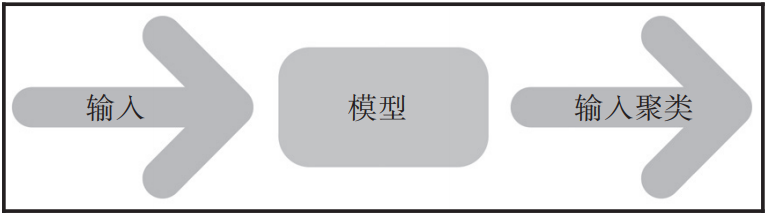
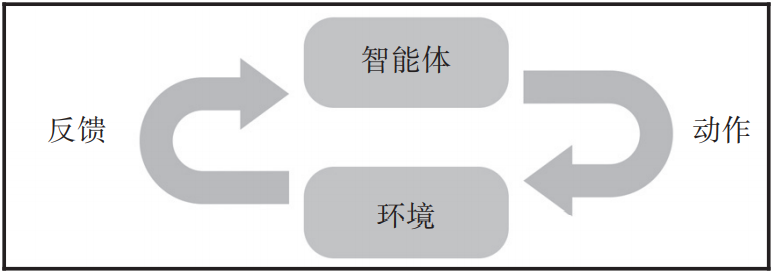
有监督学习 无监督学习 半监督学习 强化学习

(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。
评论