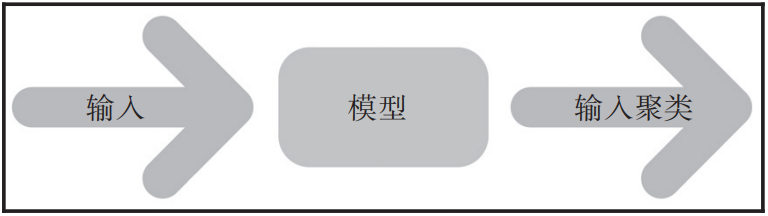
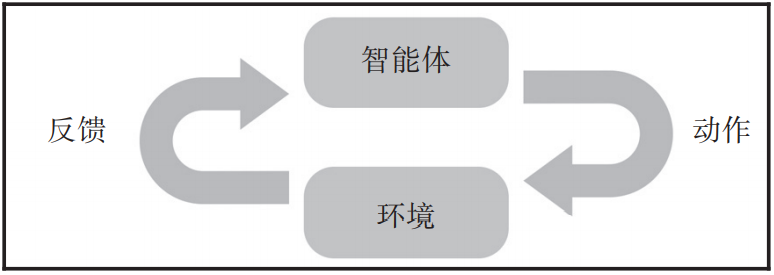
4种不同类别的机器学习概述大数据DT关注共 2132字,需浏览 5分钟 ·2021-09-02 18:28 导读:机器学习涉及方方面面的内容,包含许多不同类型的算法,其学习方式也不相同。我们将简要介绍这些学习方式及其对应的情景。作者:列奥纳多·德·马尔希(Leonardo De Marchi),劳拉·米切尔(Laura Mitchell)来源:大数据DT(ID:hzdashuju)我们可以根据算法执行学习的方式将它们分为以下不同类别:有监督学习无监督学习半监督学习强化学习01 有监督学习有监督学习是目前商业过程中最常见的机器学习形式。这些算法试图找到映射输入和输出的函数的一个很好的近似。为此,顾名思义,我们需要自己为算法提供输入值和输出值,并且尝试找到一个能够使预测值和实际输出值之间误差最小的函数。学习阶段称为训练(training)。模型经过训练后,可以针对未见过的数据预测输出。此阶段通常被视为评分或预测,如图1-1所示。▲图 1-102 无监督学习无监督学习适用于未标记的数据,因此我们不需要实际的输出值,仅需要输入。它尝试在数据中查找模式并根据这些共同属性做出反应,将输入划分为多个不同聚类(如图1-2所示)。▲图 1-2通常,无监督学习通常与有监督学习结合使用,以减少输入空间并将数据中的信号集中在较少数量的变量上,但无监督学习还有其他目标。从这个角度来看,当标记数据很昂贵或不太可靠时,无监督学习比有监督学习更适用。常见的无监督学习技术有聚类(clustering)和主成分分析(Principal Component Analysis,PCA)、独立成分分析(Independent Component Analysis,ICA),以及一些神经网络,例如生成对抗网络(Generative Adversarial Network,GAN)和自编码器(Autoencoder,AE)。03 半监督学习半监督学习是介于有监督学习和无监督学习之间的一种技术。它可以说不属于机器学习中一个单独的类别,而只是有监督学习的一种泛化,但在这将其单独列出是有用的。其目的是通过将一些有标记的数据扩展到类似的未标记数据,从而降低收集标记数据的成本。我们把一些生成模型分类为半监督学习。半监督学习可以分为直推学习和归纳学习。直推学习适用于推断未标记数据的标签,归纳学习适用于推断从输入到输出的正确映射。我们可以看到此过程与我们在学校学习的大多数过程相似。老师向学生展示一些例子,并让学生回家完成作业。为了完成这些作业,他们需要进行泛化。04 强化学习强化学习(RL)是我们目前所见的最独特的类别。这个概念非常有趣:该算法试图找出一个策略来最大化奖励总和。该策略由使用它在环境中执行动作的智能体来学习。然后,环境返回反馈,智能体使用该反馈来改进其策略。反馈是对所执行动作的奖励,可以是正数、空值或负数,如图1-3所示。▲图 1-3关于作者:列奥纳多·德·马尔希(Leonardo De Marchi),目前是Badoo的数据科学家主管,Badoo是世界上的大型交友网站之一,拥有超过4亿名用户。他也是ideai.io(一家专门从事机器学习培训的公司)的首席教练,为大型机构和有活力的初创企业提供技术和管理培训。他拥有人工智能专业硕士学位,曾在体育界担任数据科学家。劳拉·米切尔(Laura Mitchell),目前是Badoo的首席数据科学家。Laura在NLP、图像分类和推荐系统等项目的交付方面具有丰富的实践经验,包括从最初的构思到产品化。她热衷于学习新技术并紧跟行业趋势。本文摘编自《神经网络设计与实现》,经出版方授权发布。延伸阅读《神经网络设计与实现》点击上图了解及购买转载请联系微信:DoctorData推荐语:本书是一本神经网络实践进阶指南,适合对AI和深度学习感兴趣并且想进一步提高技能的读者阅读。划重点👇干货直达👇10本最火的中台与数字化转型图书,朋友圈都在传终于有人把碳达峰、碳中和讲明白了终于找到了!AI学习路线图——从零基础到就业终于有人把数据仓库讲明白了更多精彩👇在公众号对话框输入以下关键词查看更多优质内容!读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化AI | 人工智能 | 机器学习 | 深度学习 | NLP5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生据统计,99%的大咖都关注了这个公众号👇 浏览 40点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 4种不同类别的机器学习概述数据工匠俱乐部0【极简概述】4种不同类别的机器学习机器学习算法与Python实战0【机器学习】机器学习-概述全栈自学社区0【机器学习】聚类代码练习机器学习初学者0JVM 类加载概述SegmentFault0深度学习概述数学算法俱乐部0DejalFoundationCategoriesFoundation 级别的类DejalFoundationCategories是Foundation级别的类,添加了有用的方法到类中:NSArray,NSDictionary,NSString等等,支持iOS和OSX。功能:NS机器学习算法-随机森林之理论概述生信宝典0【机器学习】机器学习项目流程机器学习初学者0【机器学习】机器学习的学习经验总结!机器学习初学者0点赞 评论 收藏 分享 手机扫一扫分享分享 举报




 下载APP
下载APP