
机器学习算法-随机森林之理论概述
前面我们用 3 条推文从理论和代码角度讲述了决策树的概念和粗暴生成。
随机森林的算法概述
决策树我们应该都暴力的理解了,下面我们看随机森林。
随机森林实际是一堆决策树的组合(正如其名,树多了就是森林了)。
这是一个简化版的理解,实际上要复杂一些。具体怎么做的呢?
假设有一个数据集包含n个样品, p个变量,也就是一个n X p的矩阵,采用下面的算法获得一系列的决策树:
从数据集中有放回地取出
n个样品作为训练集,训练1棵决策树。假如数据集有
6个样品[a,b,c,d,e],第一次有放回地取出6个样品可能是[a,a,c,d,d,e],第二次有放回地取出6个样品可能是[a,c,c,d,e,e]。每棵树的训练集是不完全相同的,每个训练集内部包含重复样本。
这一步称为
Bagging (Bootstrap aggregating) 自助聚合。每棵决策树构建时,通常随机抽取
m (m<m在选择每一层节点时不变。每棵决策树野蛮生长,不剪枝。
重复第
1,2,3步t次,获得t棵决策树。
通过聚合t棵决策树做出最终决策:
分类问题:
选择
t棵决策树中支持最多的类作为最终分类 (服从多数,majority vote)回归问题:
计算
t棵决策树预测的数值的均值作为最终预测值
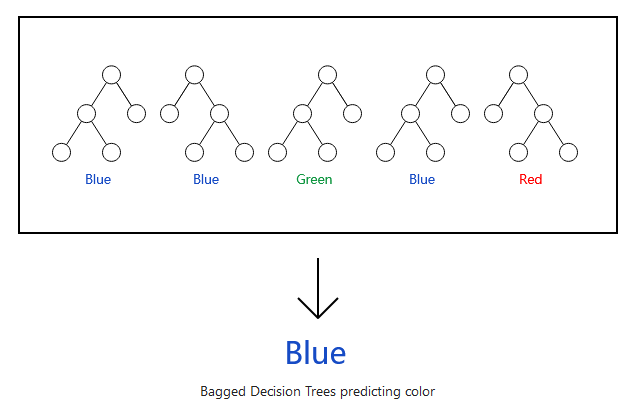
为什么要这么做呢?
在数据科学中,很大数目的相对不相关的模型的群体决策优于任何单个模型的决策。
随机森林的错误率取决于两个因素:
不同树之间的相关性越高,则错误率越大。
这要求
m尽可能小。每个决策树的分类强度越大,则错误率越小。
这要求
m尽可能大。
m通常为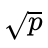 或
或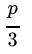 。也可以通过
。也可以通过oob (out-of-bag) error rate (自助聚合错误率)进行迭代调参选择分类效果最好的m。
随机森林工作机制
通过有放回采样的方式构建训练集时,通常有1/3的样品没有被选中。这些样品可以用来估计该训练集获得的决策树的分类错误率 (OOB), 也可以用来评估变量的重要性。
每棵决策树构建好后,用所有的数据作为输入获得每个样品在每个决策树的分类结果,然后计算每一对样品 (c1, c2)之间的相似度 (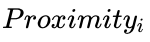 )。如果两个样品分类到相同的分类节点,它们彼此的相似性加一。最终的相似度除以决策树的总数 (
)。如果两个样品分类到相同的分类节点,它们彼此的相似性加一。最终的相似度除以决策树的总数 (t)目获得任意一对样品标准化后的的相似度值。这个值可后续用于缺失值填充、异常样品鉴定和对数据进行低维可视化。(i表示第i棵树)
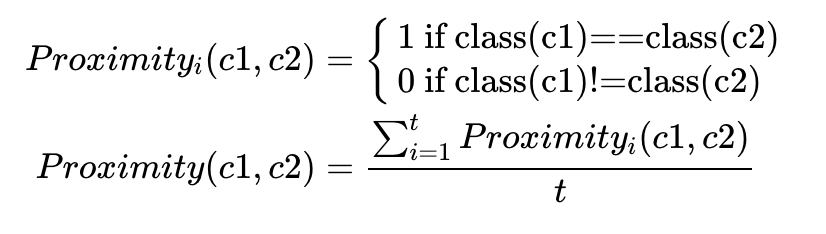
oob (out-of-bag) error rate (聚合错误率)
应用随机森林时,无需交叉验证或额外的测试集来评估错误率,而是在构建随机森林时,可自行评估:
每一个决策树构建时使用到的样本是不同的。
因为是有放回地随机采样,在构建每棵树时,大约
1/3的样品不会被用到。这些没有被抽样到用于构建决策树的样品用来测试该决策树的分类能力。
理论上每个样品在
1/3的决策树中可作为测试样品获得一个分类结果和分类错误率。聚合每个没有被抽样到的样品在所有其不被用于训练集构建的决策树的分类结果作为该样品的最终分类结果,与数据的原始分类一致则是分类正确,否则是分类错误。
所有分类错误的样品除以总样品即为构建的随机森林模型的错误率。
(
i表示第i棵树)

确定分类的关键变量
对于每一棵随机决策树,统计其分类OOB数据集中所有样品正确分类的次数 (O)。随机排列OOB数据集中变量m的值,再用该决策树分类,统计所有样品被正确分类的次数 (P)。这两个次数的差值(O-P)即为变量m在单棵决策树的分类重要性得分 (CS, classification score),其在所有分类树中的均值即为该变量的整体重要性得分 (ACS, avraged classification score)。

通过大量数据测试发现,同一个变量不同决策树获得的CS的相关性很低,可以认为是彼此独立的。随后按照常规方式计算所有CS的标准差,ACS/CS获得Z-score值。假设Z-score服从正态分布,根据Z-score估计该变量的重要性程度。
如果变量数目很多,只在第一次用所有变量评估,后续只评估第一次选出的最重要的一部分变量。
筛选关键分类变量的另一个指标 Gini importance
Gini impurity得分是确定决策树每一层级节点和阈值的一个评判标准。每个变量 (m)贡献的Gini impurity的降低程度(GD(m))可以作为该变量重要性的一个评价标准。变量(m)在所有树中的GD(m)之和获得的变量重要性评估与上面通过随机置换数据获得的变量评估结果通常是一致的。
变量互作 Interactions
变量互作定义为,一个决策树通过变量m做了决策后的子节点可以更容易或更不容易通过变量k做决策。如果变量m与变量k相关,按m决策后,再按k决策就不容易分割因为已经被m分割了。
这也是基于两个变量m和k是独立的这一假设。通常通过每个变量作为决策节点时计算出的Gini impurity得分 (g(m)或 g(k),得分越低说明决策分割效果越少)作为评价依据。他们的差值g(m) - g(k)即为变量m和k的互作值,这个值越大,说明基于变量m分割后更有利于基于变量k分割。
相似性 Proximities
每棵决策树构建好后,用所有的数据评估决策树,然后计算每一对样品之间的相似度。如果两个样品分类到相同的分类节点,它们彼此的相似性加一。最终的相似度除以决策树的总数目获得任意一对样品标准化后的的相似度值 (具体见前面的公式)。这些值构成一个n X n (n为总样品数)的矩阵。这个值可后续用于缺失值填充、异常样品鉴定和对数据进行低维可视化。
如果数据集较大,n X n的矩阵可能需要消耗比较多内存。这是可以使用n X t的矩阵来存储 (t是随机森林中决策树的数目)。用户也可以指定每个样品只保留最相似的nrnn个样本,以加快运算速度。
如果有测试数据集,测试集中的样品也可以与训练集中的样品计算两两相似度。
降维展示 Scaling
样品i和j的相似度定义为prox(i,j),这是一个不大于1的正数 (具体见前面公式)。1-prox(i,kj)则是样品i和j的欧式距离。这样就构成一个最大为n X n的距离矩阵。
随后就可以通过MDS方式计算其内积,求解特征值和特征向量。可类比于PCA分析,获得几个新的展示维度。通常绘制第1,2维就可以比较好的展示样品的分布。
原型 Prototypes
Prototypes是一种展示变量与分类关系的方式。对第j类,选择基于相似性获得的K近邻样品中落在j类最多的样品。这k个样品中,计算每个变量的中位数、第一四分位数和第三四分位数。这个中位数就是class j的原型 (prototype), 第一四分位数和第三四分位数则是原型的置信范围。对于第二个原型,按之前的步骤计算,只是不考虑上一步用到的k的样品。输出原型时,如果是连续变量,则用原型值减去第5分位数并除以第95分位数和第5分位数的差值。如果是区域变量,原型就是出现次数最多的值。
训练集中的缺失值填充 Missing value replacement for the training set
随机森林有两种方式填充缺失值。
第一种方式速度快。如果某个样品属于
class j,其变量m值缺失,如果变量m的值是数值型,则用class j中所有样品的变量m的值的中位数作为填充值;如果变量m的值是分类型,则用class j中所有样品出现次数最多的变量m的值作为填充值;第二种方式需要更多计算量但可以给出更好的结果,即便是存在大量缺失数据时。它只通过训练集填充缺失值。首先对缺失值做一个粗略的、非精确的填充。然后计算随机森林和样本相似性。
定义样品i的变量m的值为v(m,i),如果变量m为连续性数值变量,则其填充值为其它样品中变量m的值与该样品与样品i的相似性的乘积的均值 (n1是变量m不为缺失值的样品)。如果变量m为分类型变量, 则替换其为所有样品最频繁出现的值(计算频率时需要用根据每个样品与样品i的相似性进行加权)。
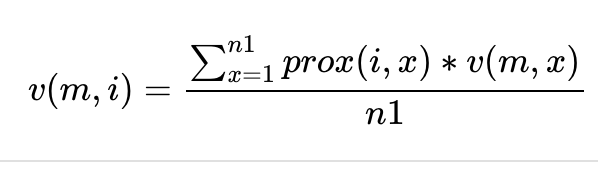
随后使用填充后的数据集迭代构建随机森林模型,计算新的填充值并且继续迭代,通常4-6次迭代即可。
替换测试集中的缺失值 Missing value replacement for the test set
取决于测试集是否自带样品标签(分类属性)有两种方式可以用于缺失值替换。
如果测试集有标签,训练集中计算出的填充值直接用于测试集填充。
如果测试集没有标签,则测试集中的每个样品都重复
n_class次 (n_class为总的分类数)。第一次重复的样品设置其标签为
class 1,并用class 1的对应值填充。第二次重复的样品设置其标签为
class 2,并用class 2的对应值填充。
这个重复后的测试集用构建好的随机森林模型进行分类。在某个样品的所有重复中,获得最多分类的class则是该样品的标签,缺失值也根据对应class填充。
标签有误的样品 Mislabeled cases
训练集通常是人为判断设定的标签。在一些领域,误标记会常出现。很多误标记的样本可以通过异常值检测的方式鉴定出。
异常值 Outliers
异常样本定义为需要从主数据集中移除的样本。从数据上来说,异常样品就是与其它所有样品相似性 (proximity)都很低的样品。通常为了缩小计算量,异常样品是从每个分类内部计算鉴定的。class j的一个异常样本就是在class j中某一个或多个与其它样本相似性很低的样本。
class j中的样品 n与class j中其它样品(k)的平均相似性定义为
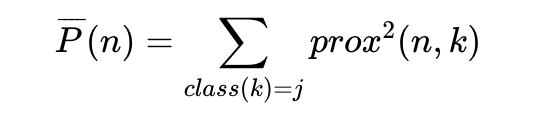
样品n是否为异常样品的度量方式为
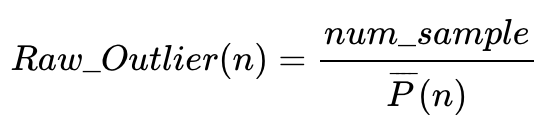
The raw outlier measure for case n is defined as
如果平均相似度较低,这个度量值就会很高。计算这一组数据 (class j中每个样本 (J1, J2, Jn)与其它样本的平均相似度)的中位数和绝对偏差。每个平均相似度值减去中位数除以绝对偏差即获得最终的异常值度量标准。
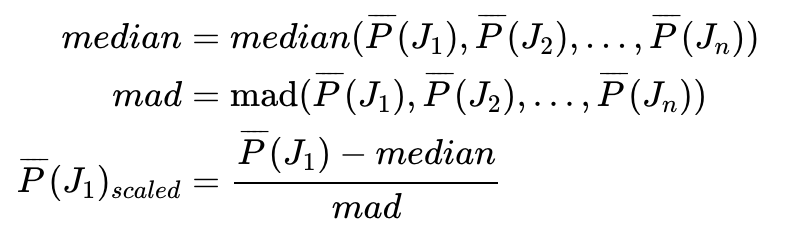
无监督聚类 Unsupervised learning
无监督聚类问题中,每个样品有一些度量值但都没有分类标签(分类问题)或响应变量(回归问题)。这类问题没有优化的标准,通常只能获得模糊的结论。最常见的应用是对数据进行聚类,能聚成几类,每一类是否意义明确。
在随机森林中,所有原始数据都视为来源于class 1, 然后构建一个相同大小的合成数据集都视为来源于class 2。第二个合成数据集通过对原始数据进行单变量 (univariate distribution)随机采样构建。合成数据集每个样品构建方式举例如下:
样品第一个变量的值从该变量在
n个样品中的值随机抽取一个。样品第二个变量的值从该变量在
n个样品中的值随机抽取一个。以此类推
因此,Class 2数据有着独立的随机变量数据分布,并且每个变量的数据分布与原始矩阵的对应变量一致。Class 2数据打乱了原始数据的依赖结构。现在全体数据就有了两个分类,可以应用随机森林算法构建模型。
如果这两类数据的oob误分类率为40%或更高,说明随机森林the x -variables look too much like independent variables to random forests。变量的依赖在分组上贡献不大。如果误分类率低,则说明变量依赖发挥了重要作用。
把无标签数据集改造为包含两个分类的数据集给我们一些好处。缺失值可以有效填充。可以鉴定出异常样品。可以评估变量的重要性。可以做降维分析(如果原始数据有标签,非监督的降维 (`scaling)通常能保留下原始分类的结构)。最大的一个好处是使得聚类成为了可能。
平衡预测错误 Balancing prediction error
在一些数据集,不同分类的预测错误是很不均衡的。一些分类预测错误率低,另一些类预测错误率高。这通常发生在每个类的样品数目差别较大时。随机森林试图最小化总错误率,保持大的类有较低的分类错误率,较小的类有较高的分类错误率。例如,在药物发现时,一个给定的分子会分类为有活性或无活性。通常分类为有活性的的概率为1/10或1/100。这时分类为有活性组的错误率就会很高。
用户可以通过输出每种分类的错误率作为预测不平衡性的评估。为了说明这个问题,我们采用一个有20个变量的合成数据集。class 1的数据符合一个球形的高斯分布,class 2的数据符合另一个球形高斯分布。训练集包含1000个class 1样品和50个class 2样品。测试集包括5000个class 1样品和250个class 2样品。
包含500棵树的随机森林输出的错误率为500 3.7 0.0 78.4。总体错误率较低(3.7%),但class 2的错误率高,为(78.4%)。可以通过对每个class设置不同的权重来平衡错误率。一个class的权重越高,它的分类错误率降低的就越多。一个常规的设置权重的方式是与class中样品数成反比。设置训练集中class 1的权重为1, class 2的权重为20,再次构建模型,输出为500 12.1 12.7 0.0。class 2的权重为20有点太高了,降低为10,获得结果如下500 4.3 4.2 5.2。
这样两个分类的错误率差不多平衡了。如果要求两个分类错误率相等,则还可以再微调class 2的权重。
需要注意的是,在平衡不同分类错误率时,总的错误率升高了。这是正常的。
检测新样品 Detecting novelties
对于测试集异常样品的检测可用来寻找新的不能分类于之前鉴定好的类中的样品。
以下面的卫星图像数据集做例子。训练集有4435个样品,测试集有2000个样品,36个变量,6个分组。
在测试集中,等间距的选取了5个样品。被选中样品的每个变量的值用从训练集中同一个变量的值随机选取一个替换。采用参数noutlier=2; nprox=1作为运行参数,输出下图:
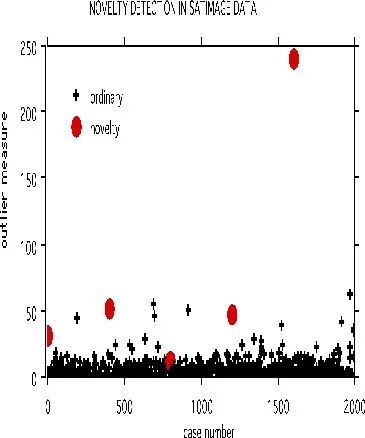
这展示了采用一个固定的训练集,可以检测测试集中的新样品。训练集构建的树可以存储起来用于检测后续的数据集。这个检测新样品的方法目前还处于试验阶段,还不能区分DNA检测中的新样本。
接下来我们就选几套数据集进行实战操作,边操作边理解概念了。
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集
(请备注姓名-学校/企业-职务等)