
基于知识图谱的行业问答系统搭建分几步?
知识图谱的概念首先是由谷歌提出,其目的是描述真实世界中存在的各种实体和概念,以及他们之间的关系,在真实的行业中应用时,我们需要先根据业务需求进行领域确定,然后通过正常的知识图谱构建方式,进行基础内容的搭建,最后进行实测之后进行优化处理,从而满足原本的业务需求。
构建过程主要分为:知识体系搭建、知识抽取、知识融合、知识储存和检索、知识推理、知识问答等六步。
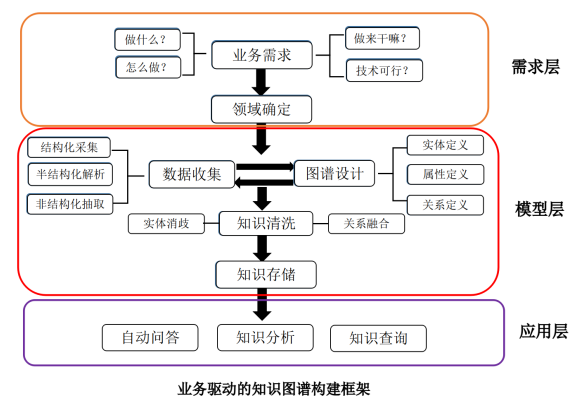
第一步:知识体系构建
采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述:
在这个本体中需要定义出知识的类别体系;
每个类别下所属的概念和实体;
某类概念和实体所具有的属性以及概念之间、实体之间的语义关系;
同时也包括定义在这个本体上的一些推理规则。
第二步:知识获取
知识获取可分为结构化和半结构化数据源中的知识抽取和非结构化文本中实体的知识抽取 。
结构化和半结构化数据源中的知识抽取:因为数据噪声少,这类数据源的信息抽取方法相对简单,经过人工过滤后能够得到高质量的结构化三元组。这是目前工业界常用的技术手段。
非结构化文本中实体的知识抽取:因为涉及到自然语言分析和处理技术,难度较大。但是互联网上更多的信息都是以非结构化文本的形式存在,而非结构化文本的信息抽取能够为知识图谱提供大量高质量的三元组事实,因此是构建知识图谱的核心技术。这目前也是学术研究的重点
第三步:知识融合
知识融合是对不同来源、不同语言或不同结构的知识进行融合,从而对于已有知识图谱进行补充、更新和去重。从融合的对象看,知识融合分为知识体系的融合和实例的融合。核心问题是计算两个知识图谱中两个 节点或边之间的语义映射关系。
第四步:知识存储和查询
目前知识图谱大多是基于图的数据结构,它的存储方式主要有两种形式:RDF格式存储(以三元组的形式存储数据)和图数据库(比RDF 数据库更加通用,目前典型的开源图数据库是Neo4j)。
第五步:知识推理
目前知识推理的研究主要集中在针对知识图谱中缺失关系的补足,即挖掘两个实体之间隐含的语义关系。所采用的方法可以分为两种:
基于传统逻辑规则的方法进行推理:研究热点在于如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题;
基于表示学习的推理:采用学习的方式,将传统推理过程转化为基于分布式表示的语义向量相似度计算任务。这类方法优点是容错率高、可学习,缺点也显而易见,即不可解释,缺乏语义约束。
第六步:知识问答(完成最终应用)
看似简单的六步,却不知道应该怎么做?!这是现在大多数知识图谱入门者最头疼的问题。

很多初学者认为知识图谱的入门学习比较难,不仅仅是因为知识图谱的技术栈比较长,还因为涉及到NLP、ML、Database、知识工程等多个学科知识,找不到重点,自己摸索两个月,回头看“WC,还是啥也没明白呀!”,最后越学越累……

其实掌握了方法,知识图谱的学习并不算难。
学习的第0步,就需要有python编程基础、线性代数和概率论的基础,以及深度学习基础知识(CNN、RNN)等。
第1步,从理论上来说,掌握以知识图谱为代表的知识工程的基本问题和基本方法,系统性的掌握知识图谱生命周期各阶段核心技术原理,了解知识图谱领域的前沿发展态势。
第2步,从实践上来说,学会使用经典的知识图谱相关软件,编程实现知识图谱各阶段经典算法,掌握知识图谱案例发展脉络,能够简单实现基于知识图谱的问答系统。

深蓝学院倾心打磨了《知识图谱理论与实践》课程,由于受疫情影响,我们基于以往6期的知识图谱线下课程,迭代精品线上课程。这本课程将理论基础与实践相结合,让你实现基本知识图谱的问答系统~

课程大纲

添加课程小助手,领取课程超详细课程大纲
抢占优惠名额啦
扫码添加深蓝学院-子书
备注【115】,快速通过好友哦!
评论