
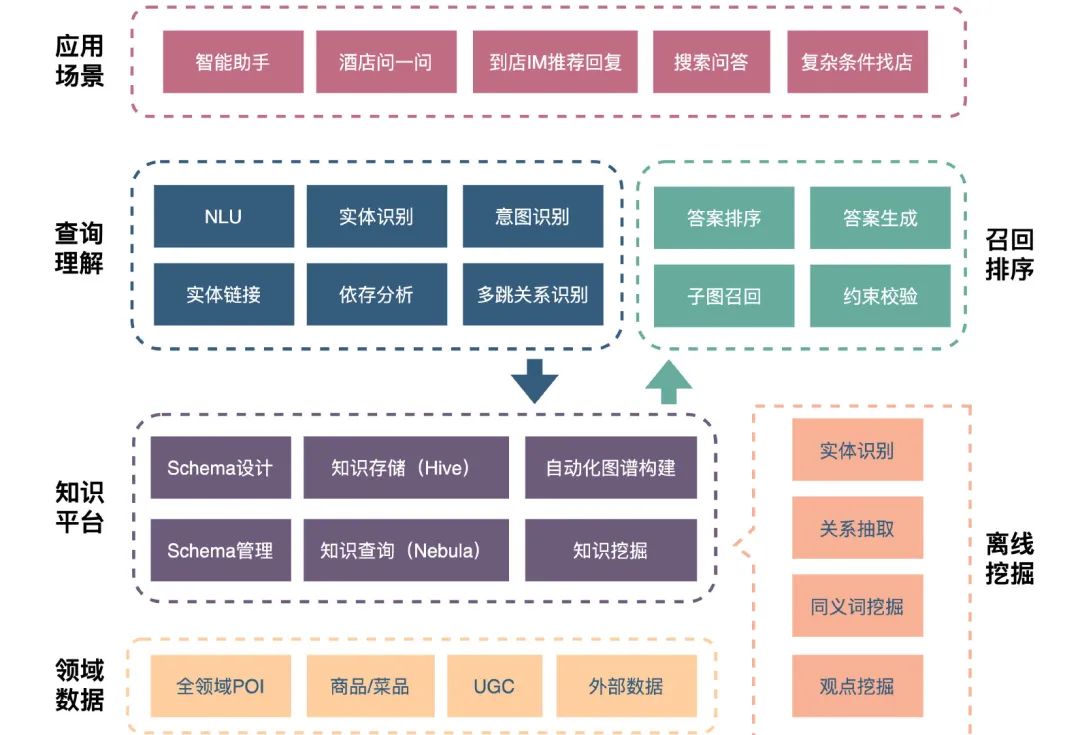
美团知识图谱问答技术实践与探索
知识图谱问答(Knowledge-based Question Answering, KBQA)是指给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。美团在平台服务的售前、售中、售后全链路的多个场景中都存在大量的咨询问题。我们基于问答系统,以自动智能回复或推荐回复的方式,来帮助商家提升回答用户问题的效率,同时更快地解决用户问题。
1 背景与挑战
2 解决方案
2.1 Query理解
2.2 关系识别
2.3 复杂问题理解
2.4 观点问答
2.5 端到端方案的探索
3 应用实践
3.1 酒店问一问
3.2 门票地推
3.3 商家推荐回复
4 总结与展望
1 背景与挑战
PairQA:采用信息检索技术,从社区已有回答的问题中返回与当前问题最接近的问题答案。 DocQA:基于阅读理解技术,从商家非结构化信息、用户评论中抽取出答案片段。 KBQA(Knowledge-based Question Answering):基于知识图谱问答技术,从商家、商品的结构化信息中对答案进行推理。
繁多的业务场景:美团平台业务场景众多,包涵了酒店、旅游、美食以及十多类生活服务业务,而不同场景中的用户意图都存在着差别,比如“早餐大概多少钱”,对于美食类商家需要回答人均价格,而对于酒店类商家则需要回答酒店内餐厅的价格明细。 带约束问题:用户的问题中通常带有众多条件,例如“故宫学生有优惠吗”,需要我们对故宫所关联的优惠政策进行筛选,而不是把所有的优惠政策都回答给用户。 多跳问题:用户的问题涉及到知识图谱中多个节点组成的路径,例如“XX酒店的游泳池几点开”,需要我们在图谱中先后找到酒店、游泳池、营业时间。
2 解决方案
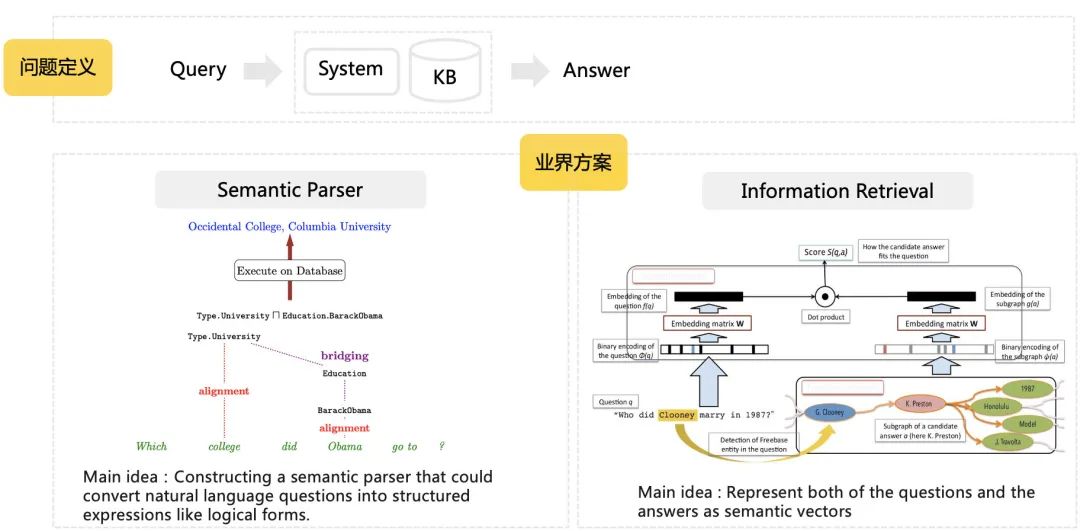
基于语义解析(Semantic Parsing-based):对问句进行深度句法解析,并将解析结果组合成可执行的逻辑表达式(如SparQL),直接从图数据库中查询答案。 基于信息抽取(Information Retrieval):先解析出问句的主实体,再从KG中查询出主实体关联的多个三元组,组成子图路径(也称多跳子图),之后分别对问句和子图路径编码、排序,返回分数最高的路径作为答案。
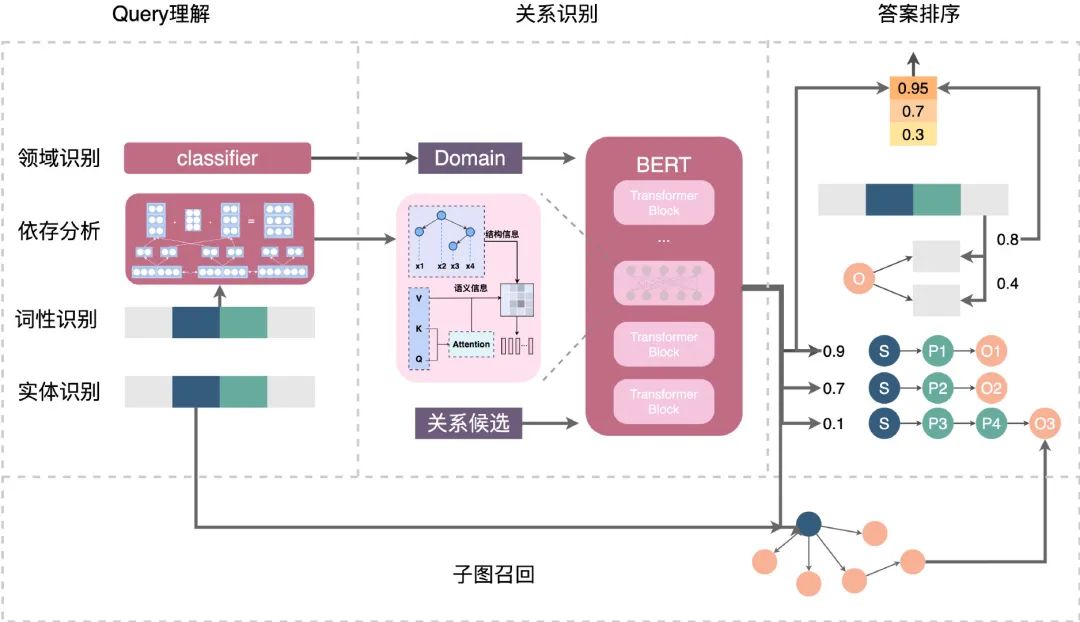
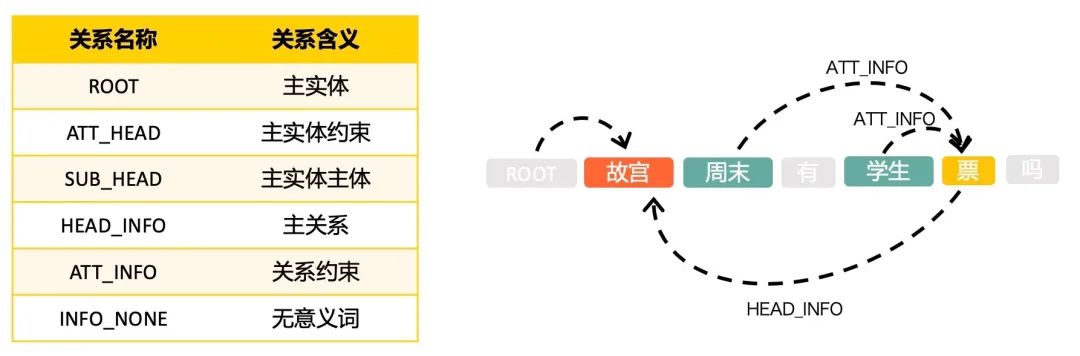
Query理解:输入原始Query,输出Query理解结果。其中会对对Query进行句法分析,识别出用户查询的主实体是“故宫” 、业务领域为“旅游”、问题类型为一跳(One-hop)。 关系识别:输入Query、领域、句法解析结果、候选关系,输出每个候选的分数。在这个模块中,我们借助依存分析强化Query的问题主干,召回旅游领域的相关关系,进行匹配排序,识别出Query中的关系为“门票”。 子图召回:输入前两个模块中解析的主实体和关系,输出图谱中的子图(多个三元组)。对于上述例子,会召回旅游业务数据下主实体为“故宫”、关系为“门票”的所有子图。 答案排序:输入Query和子图候选,输出子图候选的分数,如果Top1满足一定阈值,则输出作为答案。基于句法分析结果,识别出约束条件为“学生票”,基于此条件最终对Query-Answer对进行排序,输出满足的答案。
2.1 Query理解
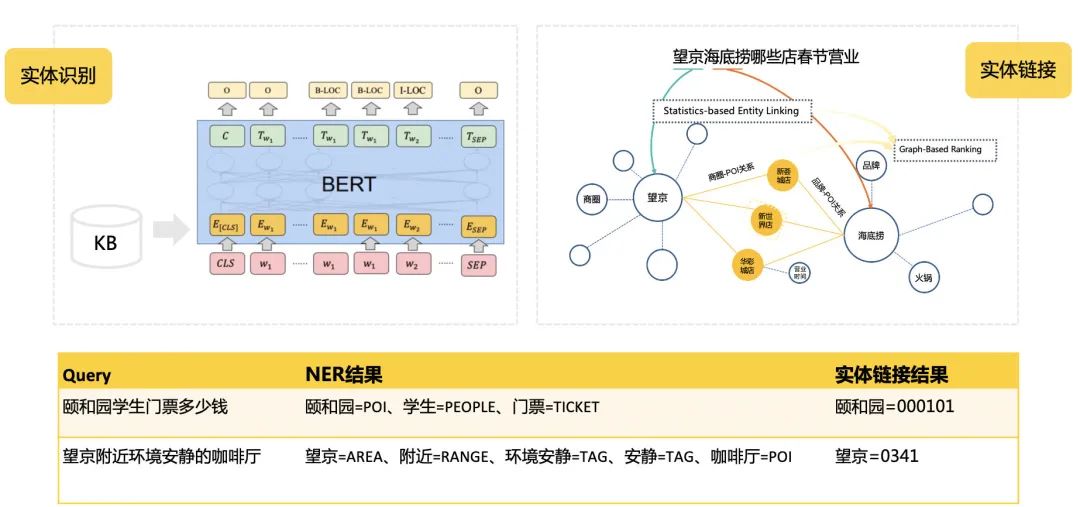
实体识别和实体链接,输出问句中有意义的业务相关实体和类型,如商家名称、项目、设施、人群、时间等。 依存分析:以分词和词性识别结果为输入,识别问句的主实体、被提问信息、约束等。
为了提升OOV(Out-of-Vocabulary)词的识别能力,我们对实体识别的序列标注模型进行了知识注入,利用已知的先验知识辅助新知识的发现。 考虑到实体嵌套的问题,我们的实体识别模块会同时输出粗粒度和细粒度的结果,保证后续模块对于Query的充分理解。 在问答的长Query场景下,利用上下文信息进行实体的链接,得到节点id。
2.2 关系识别
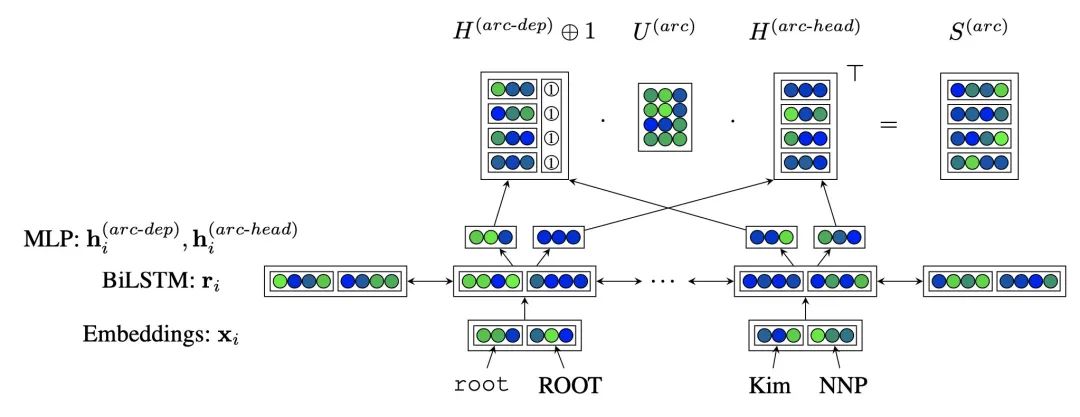
表示型:也称“双塔模型”,它的主要思想是将两段文本转换成一个语义向量,然后在向量空间计算两向量的相似度,更侧重对语义向量表示层的构建。 交互型:该方法侧重于学习句子中短语之间的对齐,并学习比较他们之间的对齐关系,最终将对齐整合后的信息聚合到预测层。由于交互型模型可以利用到文本之前的对齐信息,因而精度更高、效果更好,所以在本项目中我们采用交互型模型来解决匹配问题。
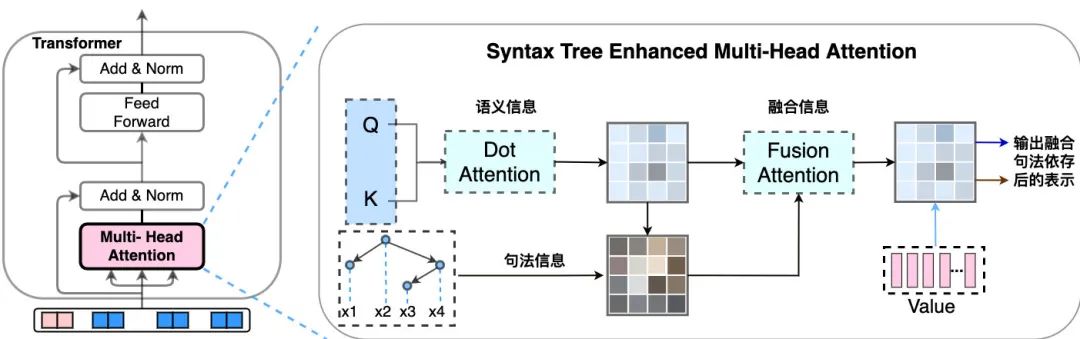
层次剪枝:BERT每层都会学到不同的知识,靠近输入侧会学到较为通用的句法知识,而靠近输出则会学习更多任务相关的知识,因此我们参考DistillBERT,采取Skip等间隔式层次剪枝,只保留对任务效果最好的3层,比单纯保留前三层的剪枝在F1-score上提升了4%,同时,实验发现不同剪枝方法效果差距可达7%。 领域任务数据预精调:剪枝后,由于训练数据有限,3层模型的效果有不小的下降。通过对业务的了解,我们发现美团的“问大家”模块数据与线上数据的一致性很高,并对数据进行清洗,将问题标题和相关问题作为正例,随机选取字面相似度0.5-0.8之间的句子作为负例,生成了大量弱监督文本对,预精调后3层模型在准确率上提升超过4%,甚至超过了12层模型的效果。 知识增强:由于用户的表达方式多种多样,准确识别用户的意图,需要深入语意并结合语法信息。为了进一步提升效果,同时解决部分Case,我们在输入中加入了领域与句法信息,将显式的先验知识融入BERT,在注意力机制的作用下,同时结合句法依存树结构,准确建模词与词之间的依赖关系,我们在业务数据以及五个大型公开数据集上做验证,对比BERT Base模型在准确率上平均提升1.5%。
2.3 复杂问题理解
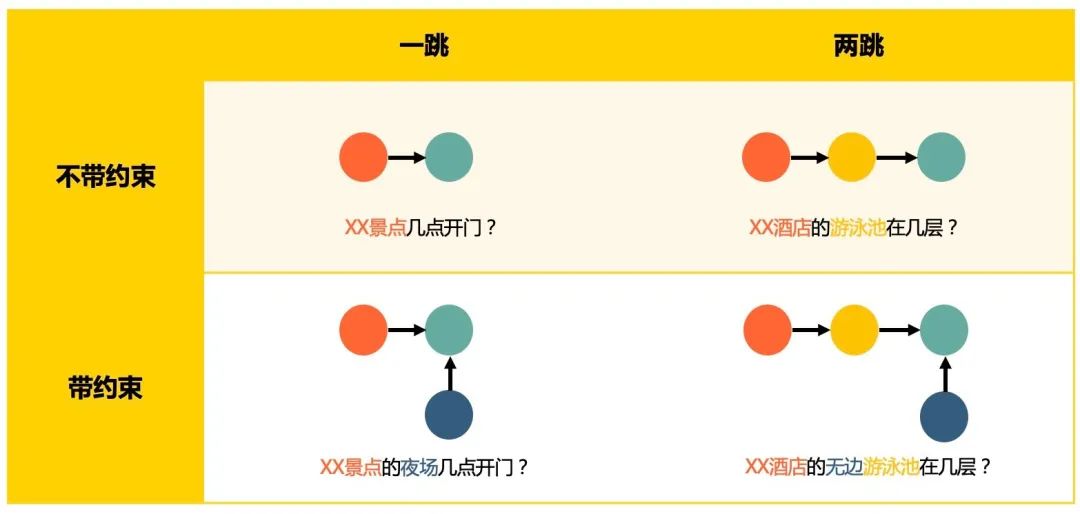
2.3.1 带约束问题

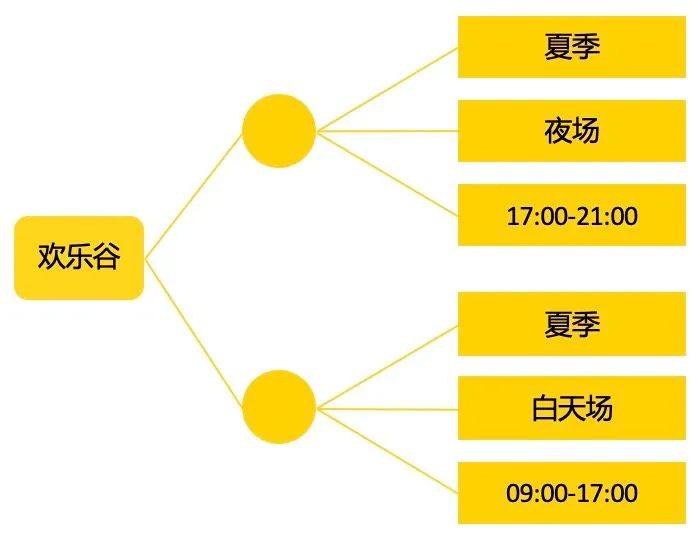
该信息以通常成对CVT形式存储,一个CVT涉及3个三元组存储。 对于“欢乐谷夏季夜场几点开始”这样的问题,在查询的时候,涉及四跳,分别为,<实体 -> 营业时间CVT>, <营业时间CVT -> 季节=夏季>, <营业时间CVT -> 时段=夜场>,<营业时间CVT -> 时间>。对业界查询快速的图数据库比如Nebula来说,三跳以上的一般查询时间约为几十毫秒,在实际上线使用中耗时较长。 一旦属性名称、属性值有不同的但是同意的表达方式,还需要多做一步同义词合并,从而保证查询时能匹配上,没有召回损失。
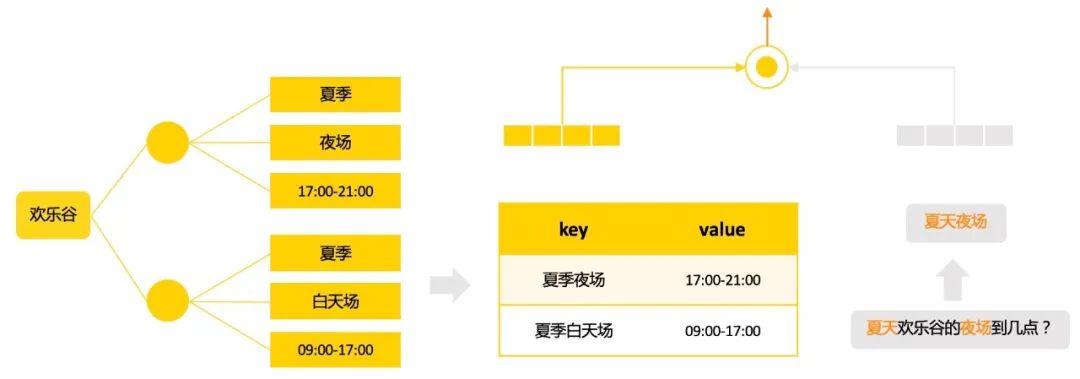
字符串形式:用文本相似度的方法去计算和约束文本的相关性。 文本Embedding:如对Key的文本形式做Embedding形式,与约束信息做相似计算,在训练数据合理的情况下,效果优于字符串形式。 其他Embedding算法:如对虚拟节点做Graph Embedding,约束文本与对应的虚拟节点做联合训练等等。
2.3.2 多跳问题
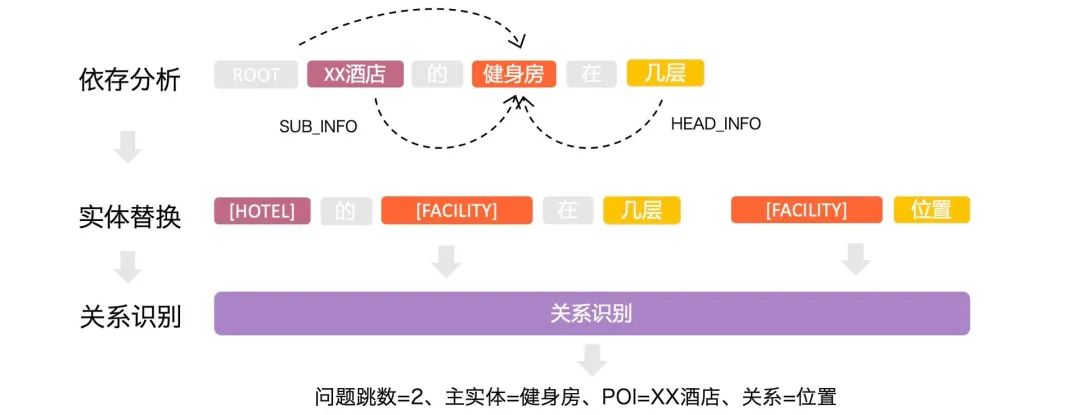
2.4 观点问答
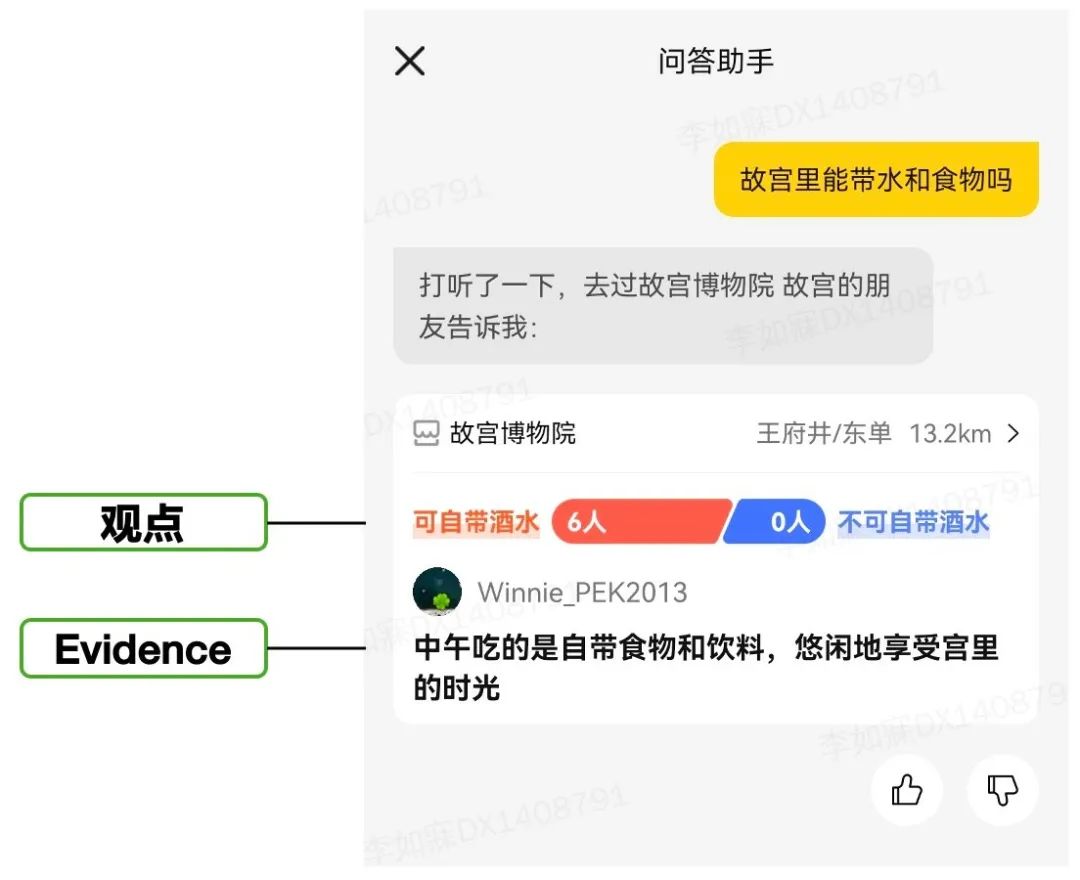
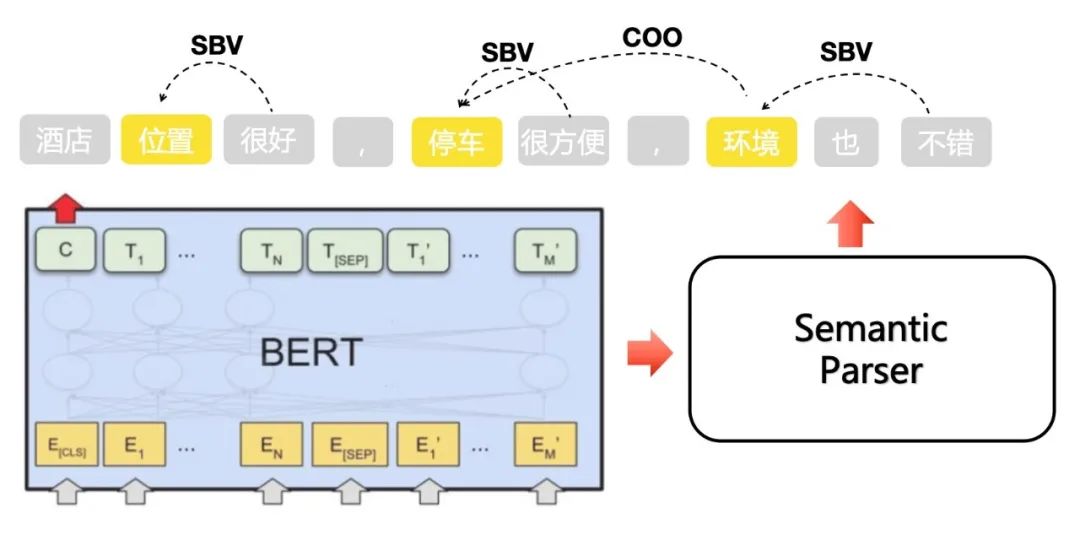
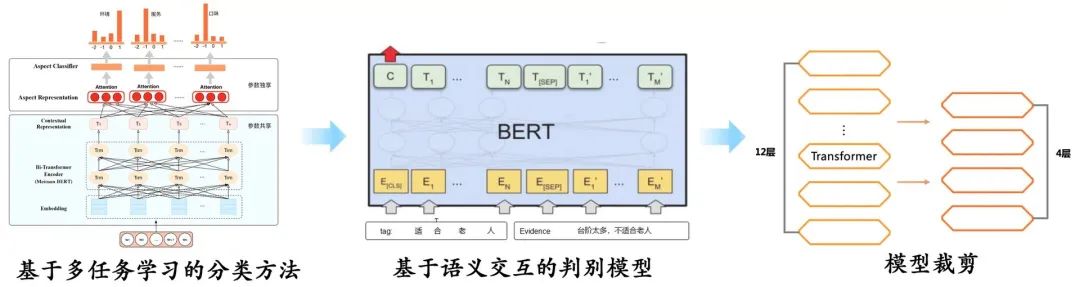
2.5 端到端方案的探索
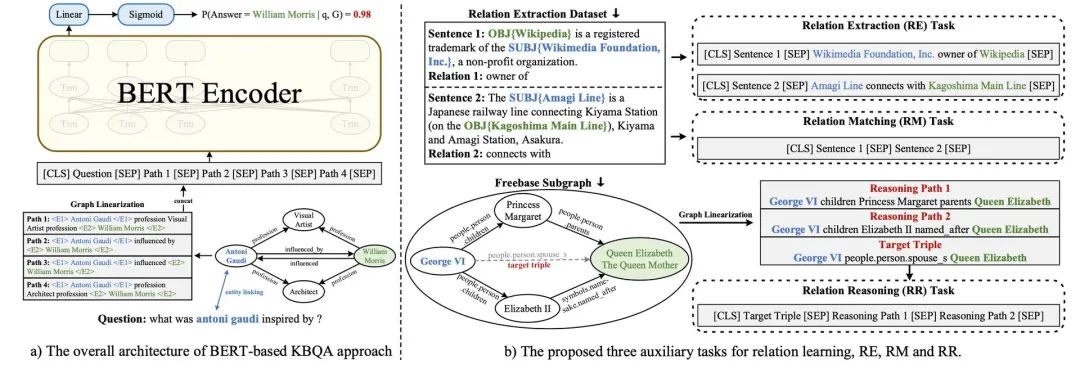
Relation Extraction:基于大规模关系抽取开源数据集,生成了大量一跳( [CLS]s[SEP]h, r, t[SEP] )与两跳( [CLS]s1 , s2 [SEP]h1 , r1 , t1 (h2 ), r2 , t2 [SEP] )的文本对训练数据,让模型学习自然语言与结构化文本间的关系。 Relation Matching:为了让模型更好的捕捉到关系语义,我们基于关系抽取数据生成了大量文本对,拥有相同关系的文本互为正例,否则为负例。 Relation Reasoning:为了让模型具备一定的知识推理能力,我们假设图谱中的(h, r, t)缺失,并利用其他间接关系来推理(h, r, t)是否成立,输入格式为:[CLS]h, r, t[SEP]p1 [SEP] . . . pn [SEP]。
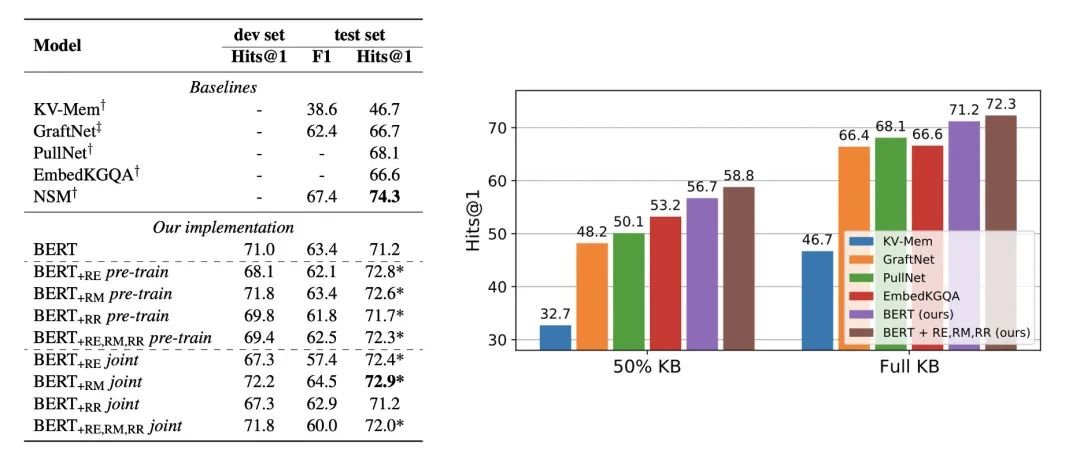
3 应用实践
3.1 酒店问一问
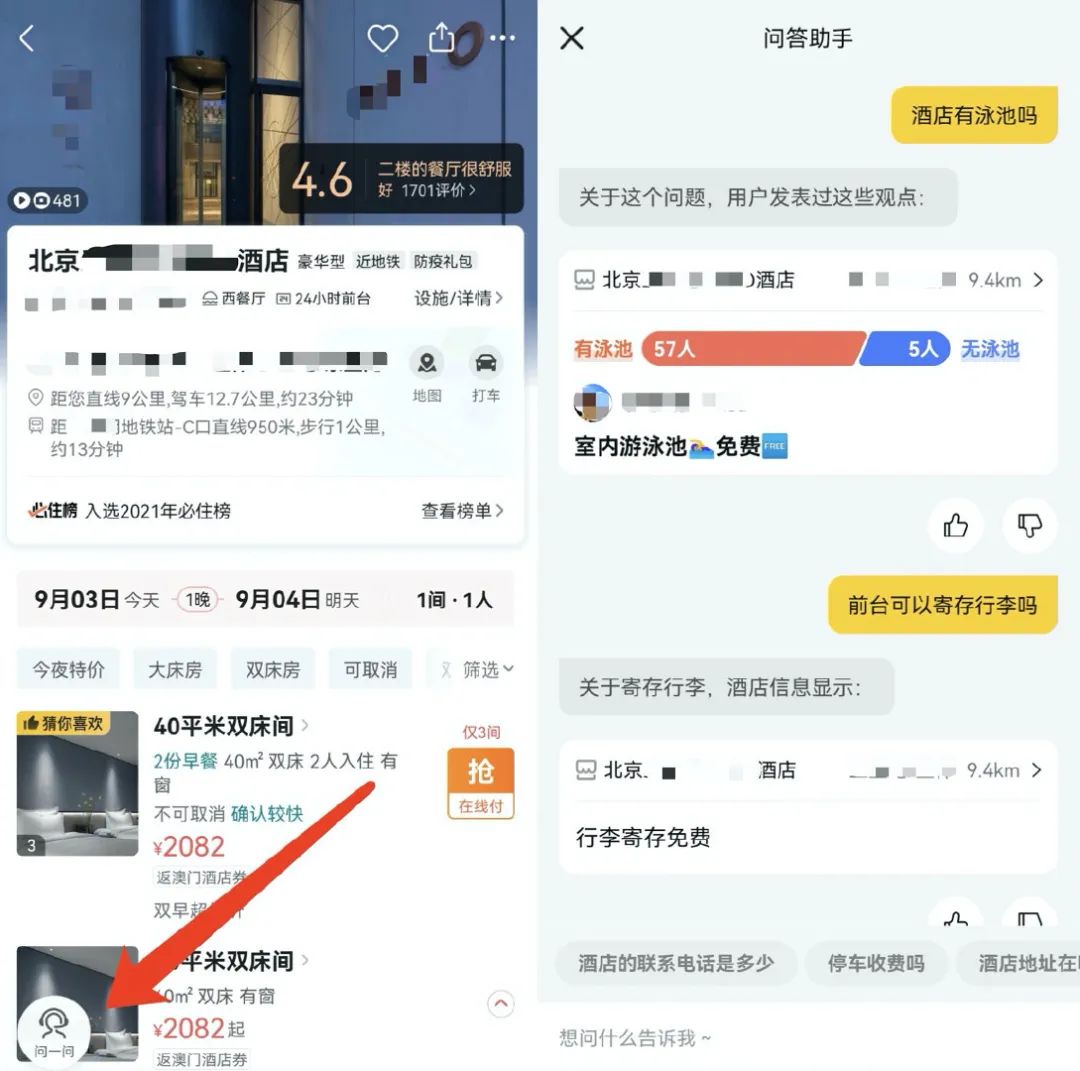
3.2 门票地推
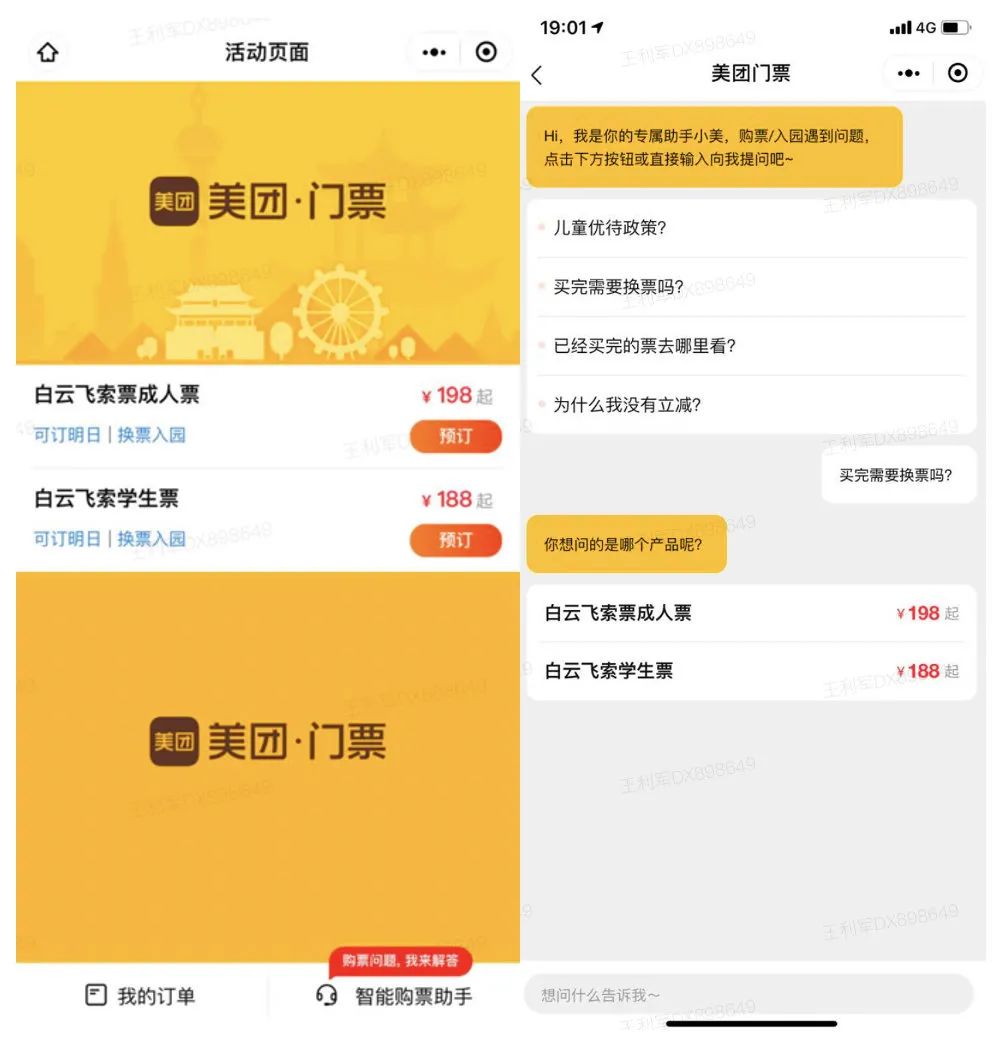
3.3 商家推荐回复
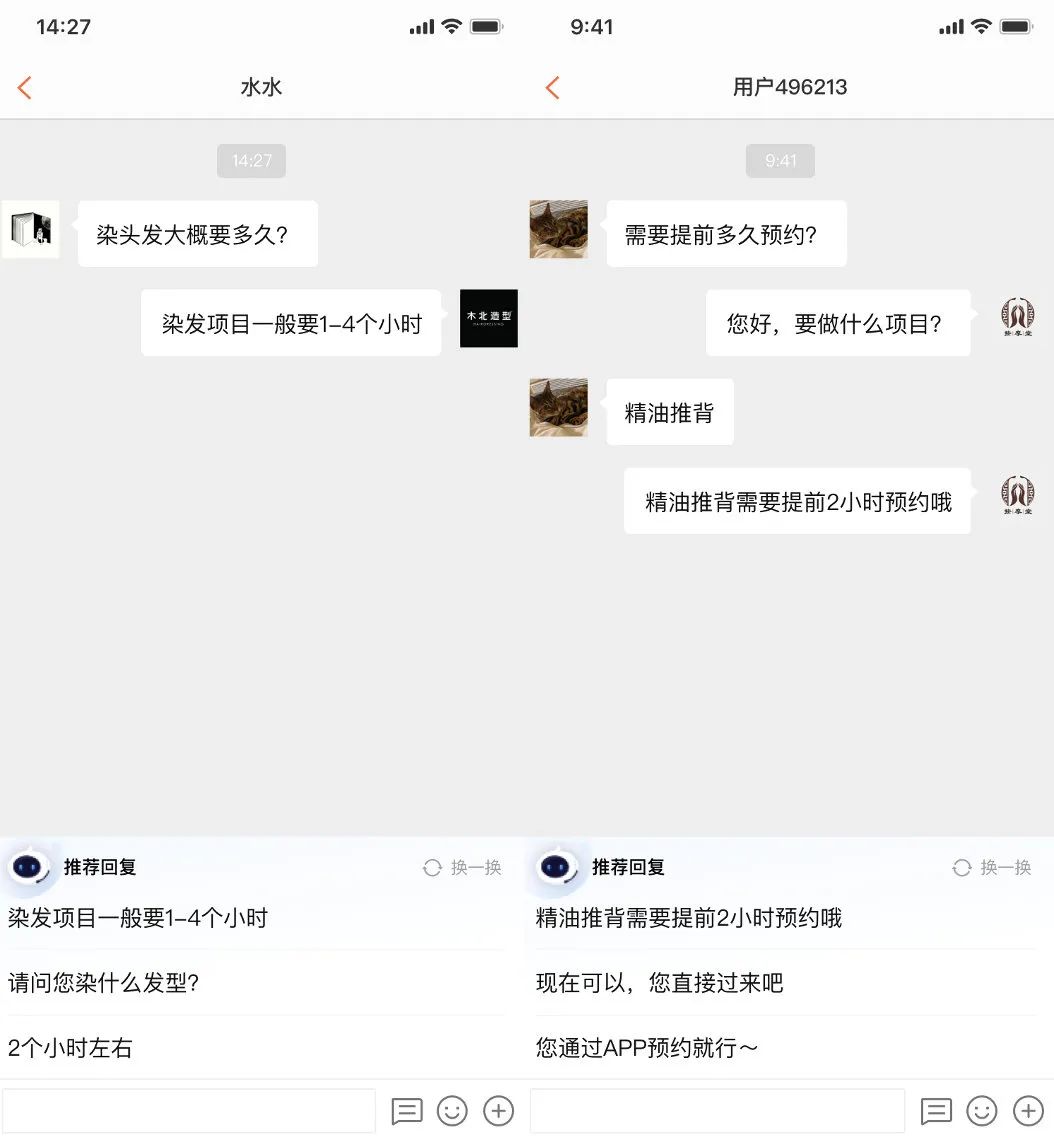
4 总结与展望
无监督领域迁移:由于KBQA覆盖美团酒店、旅游到综等多个业务场景,其中到综包含十多个小领域,我们希望提升模型的Few-Shot、Zero-Shot能力,降低标注数据会造成的人力成本。 业务知识增强:关系识别场景下,模型核心词聚焦到不相关的词将对模型带来严重的干扰,我们将研究如何利用先验知识注入预训练语言模型,指导修正Attention过程来提升模型表现。 更多类型的复杂问题:除了上述提到的带约束和多跳问题,用户还会问比较类、多关系类问题,未来我们会对图谱构建和Query理解模块进行更多优化,解决用户的长尾问题。 端到端KBQA:不管对工业界还是学术界,KBQA都是一个复杂的流程,如何利用预训练模型以及其本身的知识,简化整体流程、甚至端到端方案,是我们要持续探索的方向。
作者简介
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
评论