
浙大图谱讲义 | 第一讲-知识图谱概论 — 第2节-知识图谱的起源
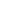
本讲义系列主要整理自浙江大学《知识图谱导论》(浙江省优秀研究生课程)的课程讲义。作为一门导论性质课程,该课程希望帮助初学者梳理知识图谱基本知识点和关键技术要素,帮助技术决策者建立知识图谱的整体视图和系统工程观,帮助前沿科研人员拓展创新视野和研究方向。
本次推文主要介绍讲义的“第一讲 知识图谱概论 第2节 知识图谱的起源”,更多相关内容请点击上方“话题”或文末“往期推荐”。


他认为人的记忆偏重关联,而非像图书馆那样严格的层次分类目录式的信息组织方式。因此,他提出设计一种Mesh关联网络来存储电子化的百科全书。

1989年,作为欧洲高能物理研究中心的计算机工程师,Tim提出了一种基于超文本技术的信息管理系统。在这个Proposal中,我们就可以看到知识图谱的影子。起初他只是希望为高能物理研究中心的科学家设计一种新型的科技文献管理系统。
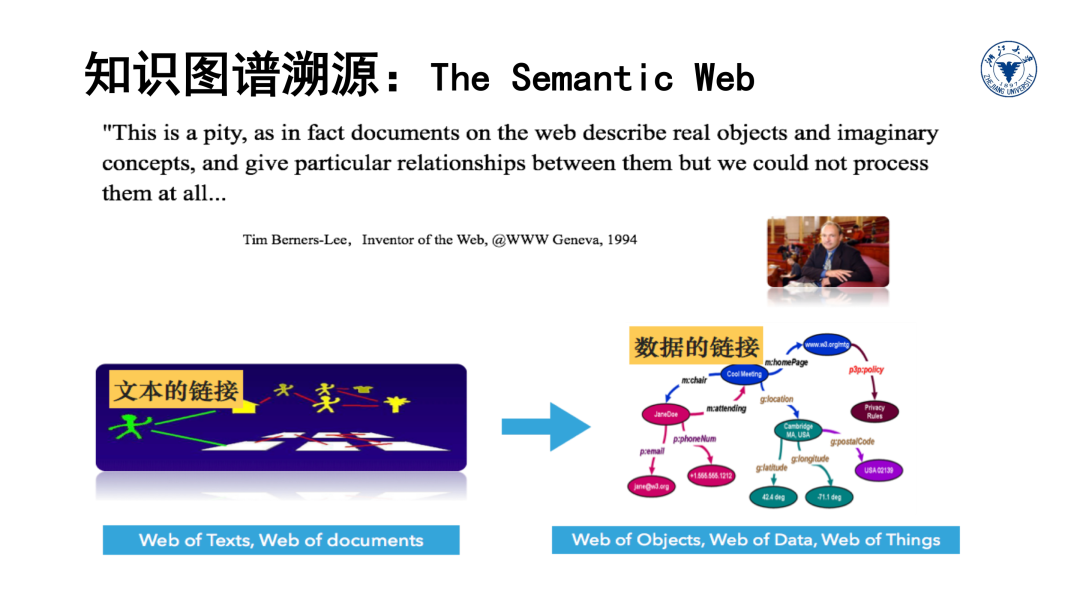


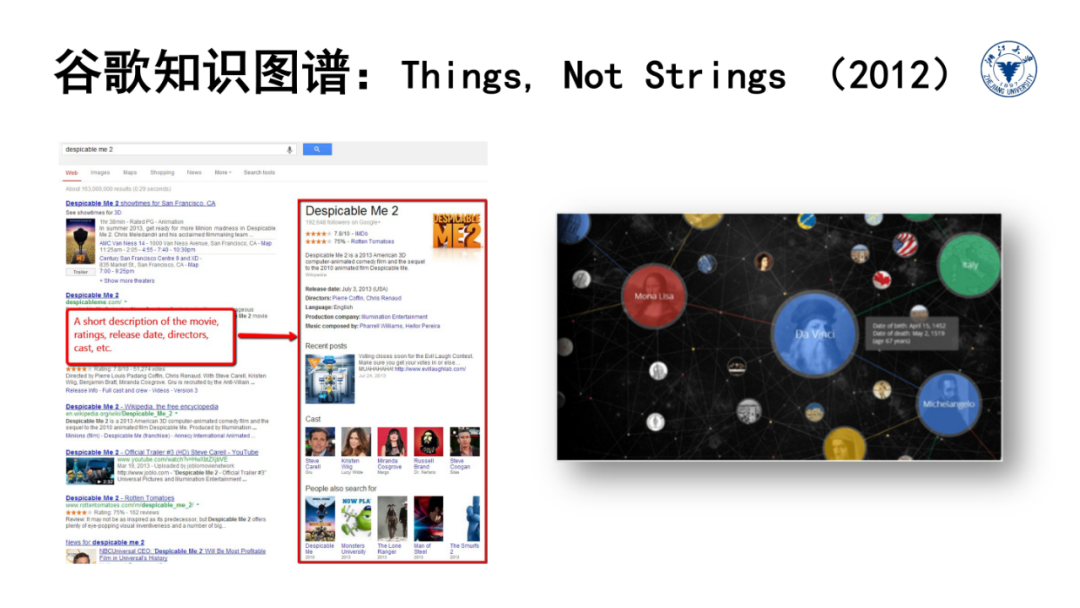
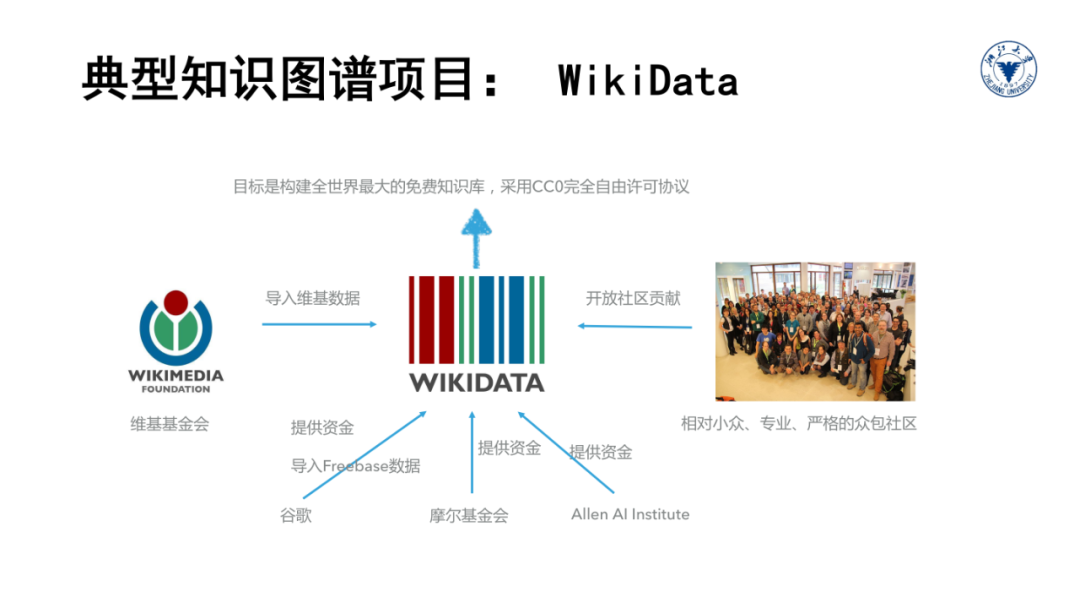






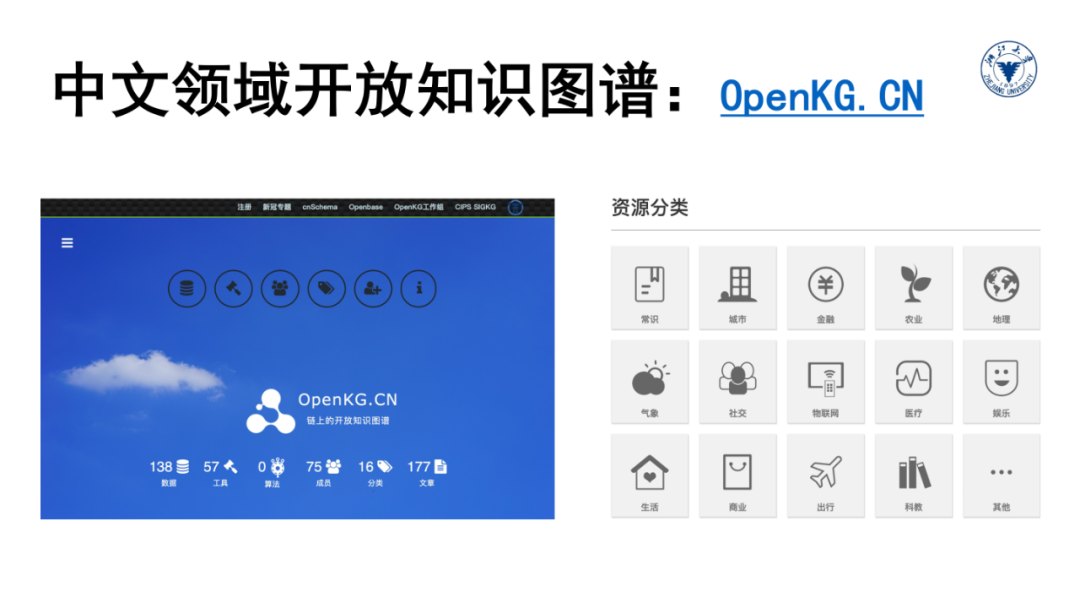
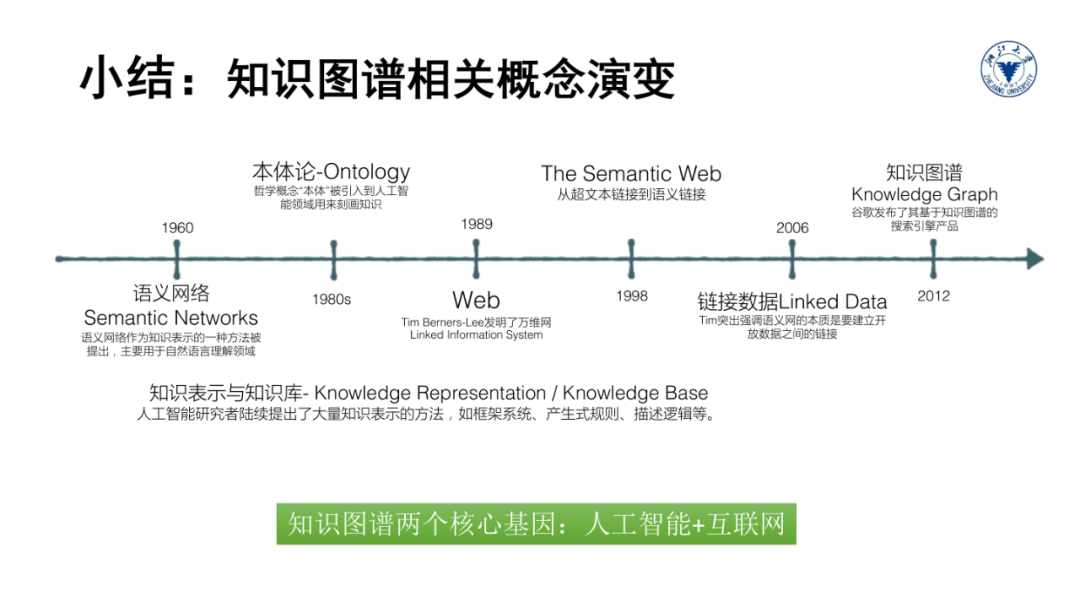
此外,利用图结构的方式描述万物关系和记录事物知识的理念也是来源于万维网。因此,我们需要从多个不同技术视角来完整全面的掌握知识图谱的本质内涵。
# 浙大图谱讲义 | 第一讲-知识图谱概论 — 第1节-语言与知识
# OpenKG开源系列 | 轻量级知识图谱抽取开源工具OpenUE
# Expert Systems With Applications | 基于级联双向胶囊网络的鲁棒三元组知识抽取
# ACMMM2021|在多模态训练中融入“知识+图谱”:方法及电商应用实践
# TASLP | 从判别到生成:基于对比学习的生成式知识抽取方法

浙江大学知识图谱创新研究团队
评论