
基于对比学习(Contrastive Learning)的文本表示模型【为什么】能学到语义【相似】度?
共 1666字,需浏览 4分钟
·
2022-02-09 17:37
我最近在做对比学习相关的实践,折腾了好久,调来调去效果一般,甚是烦躁。以下主要是一些个人的体会,思路会比较逆向。
回答这个问题,要从语义相似度计算的一般范式说起。计算句子A和句子B的语义相似度,通常来说,基于交互的方案结果更准确:

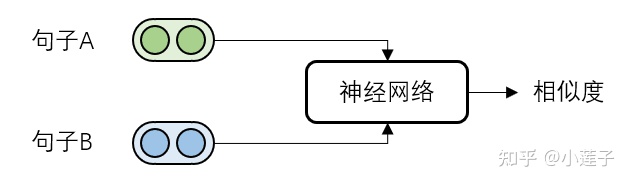
如果一共有N个句子,那么就需要进行 N × (N-1) 次相似度计算。在绝大多数的工程落地场景中,这样的计算开销都是无法被接受的。因此,建模只能转向基于表示的“两步走”方案:

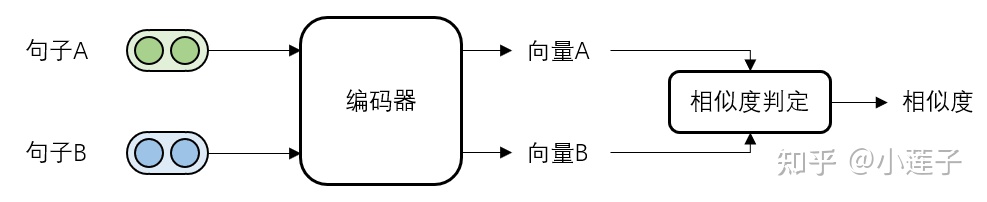
每个输入句子,先要经过一个编码器进行量化,再由一个轻量级的判定模块进行相似度输出。这样设计的好处是,偏“重”的编码部分可以离线计算并缓存结果,只需计算 N 次。相似度判定部分,虽然仍是 N × (N-1) 次计算,但采用的是余弦等非神经网络的形式,即使放在线上实时进行也可以承受。
这样“前重后轻”的结构,缺乏两个句子间的深度交互。前置神经网络在编码时,无法提前获知当前句子将和什么样的目标句子做比较,难以判断语义建模的重点是在哪个文本片段。比如,以下是 SemEval-2016 的一组标题:
A: Mandela's condition has 'improved'(曼德拉的状态有所好转)
B: Mandela's condition has 'worsened over past 48 hours'(曼德拉在过去48小时每况愈下)
单看 A 句,如果编码器将句子抽象为“曼德拉的状况波动”,似乎也可以接受,但是结合 B 句一起看,就出现了严重的信息取舍错误。
总结来说,由于使用了不可学习的余弦相似度作为度量,并且完全去除了编码部分的交互耦合,基于表示的方案无法进行 task-specific 式的模型学习。语义相似度的求解,转换成了一个单纯的特征映射过程:编码器提取输入句子的语义信息,再将它投影到向量空间中。‘
这有点像传统机器学习领域的问题。在理想情况下,所有句子在该空间的分布,应当满足 alignment 和 uniformity。即,语义相似的句子彼此聚集,语义无关的句子均匀分布。
为了达成这一目标,模型需要尽可能多地提前认识各种各样的数据。鉴于训练数据不好找,只能自行构造,于是诞生了“自监督训练”,“对比学习”也是其中的一种形式。这套流程最早是从计算机视觉里来的,用于图像向量化:

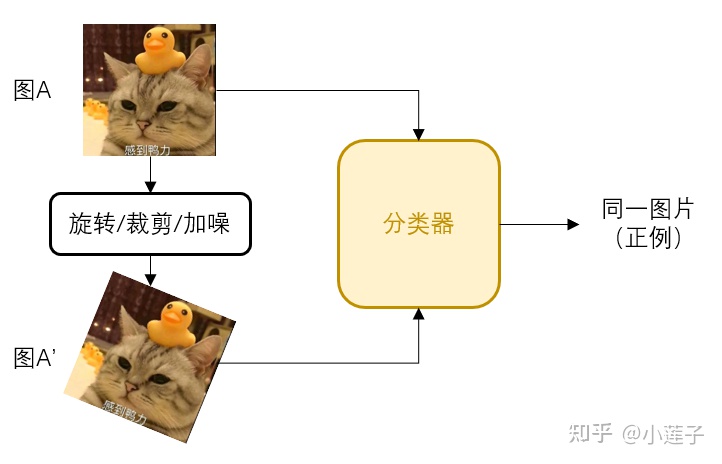
通过人为进行数据增强,让模型抵抗表层噪声,聚焦核心信息。回到 NLP 里,也有类似方法:

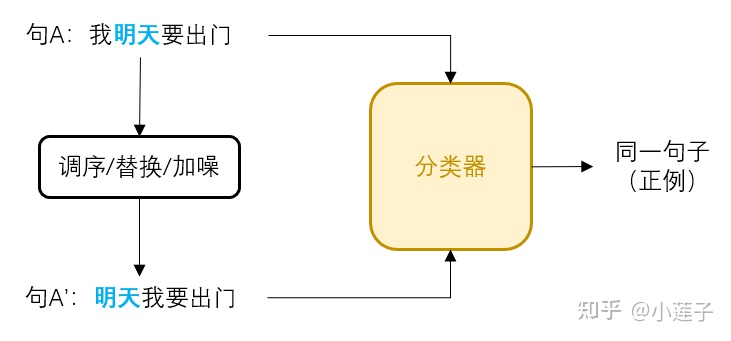
自监督通常主要有两类,一种是生成式,比如经典的 Mask-LM;一种是这里用的分类式。对于某个句子 X,按照上述流程构建“正例对”(X,X'),从 batch 里随机一个其他句子构建“负例对”(X,Y)。如此一来,便可以批量生产训练数据。
我自己在实践的时候,起初比较偷懒,就是这样直接处理的。正例对的相似度为1,负例对的相似度为0。但是,学习效果很差,和以往单句场景的经验完全不一致。我猜测,真正的标注训练数据相比,构造而成的“伪样本对”有两个隐患:
1. 针对性不强:正样本由数据增强生成,丰富度有限;负样本随机配对,暗含[任意组合都输出0]的错误诱导;
2. 标签不准确:没有经过人工校对,正样本的相似度未必就是1,很有可能只有0.5或者干脆就完全相反;负样本也极有可能随机到语义相似的句子;
因此,需要明确分类标签的交叉熵,就不适合作为相似度自监督任务的损失函数。我们需要一种更宽松的约束条件,来达成更准确的学习目标。对比学习正是如此,它的核心诉求是:
>score(X,Y) \\" eeimg="1" loading="lazy"> 配套的损失函数,有点像排序问题,是一个多路的softmax交叉熵,称为 InfoNCE。假设有1个正例组合(X,X')和N个负例组合(X,Y):
在 loss->0的时候,log内部->1,分子和分母互相逼近,由于含有共同的部分(X,X'),会让正例得分越来越大,负例越来越小,从而拉开彼此的差距。也就是常说的“正例拉近,负例推远”,正好契合语义特征空间 alignment 和 uniformity 的目标。