
文本相似度,文本匹配模型归纳(附代码)

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
本文将会整合近几年来比较热门的一些文本匹配模型,并以QA_corpus为测试基准,分别进行测试,代码均采用tensorflow进行实现,每个模型均会有理论讲解与代码实现。
项目代码与论文讲解都在持续更新中
DSSM详解
https://blog.csdn.net/u012526436/article/details/90212287
ESIM详解
https://blog.csdn.net/u012526436/article/details/90380840
ABCNN详解
https://blog.csdn.net/u012526436/article/details/90179481
BiMPM详解
https://blog.csdn.net/u012526436/article/details/88663975
DIIN详解
https://blog.csdn.net/u012526436/article/details/90710925
DRCN详解
https://blog.csdn.net/u012526436/article/details/90757018
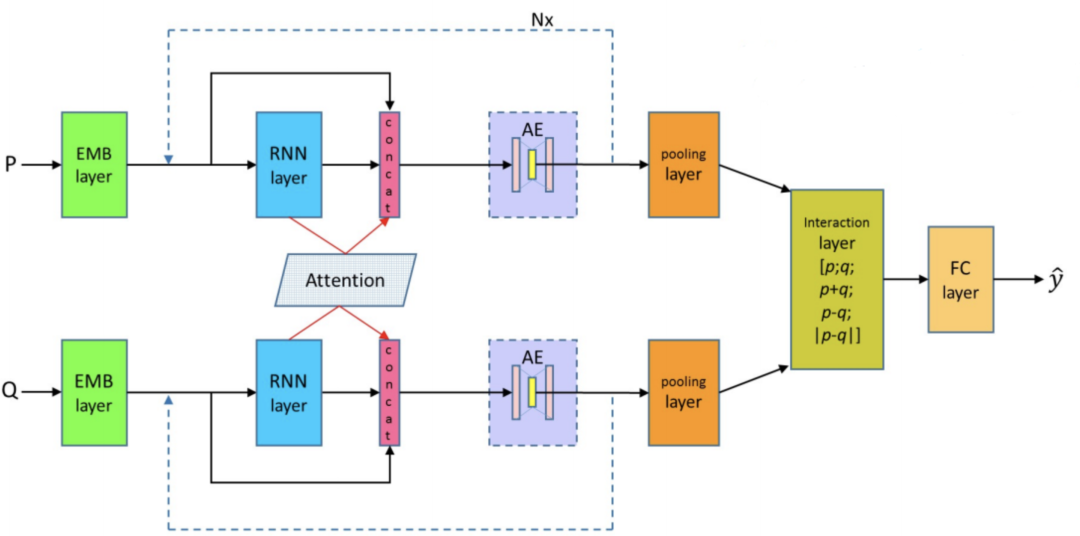
数据集为QA_corpus,训练数据10w条,验证集和测试集均为1w条
其中对应模型文件夹下的args.py文件是超参数
训练: python train.py
测试: python test.py
词向量:不同的模型输入不一样,有的模型的输入只有简单的字向量,有的模型换成了字向量+词向量,甚至还有静态词向量(训练过程中不进行更新)和 动态词向量(训练过程中更新词向量),所有不同形式的输入均以封装好,调用方法如下
静态词向量,请执行 python word2vec_gensim.py,该版本是采用gensim来训练词向量
动态词向量,请执行 python word2vec.py,该版本是采用tensorflow来训练词向量,训练完成后会保存embedding矩阵、词典和词向量在二维矩阵的相对位置的图片, 如果非win10环境,由于字体的原因图片可能保存失败
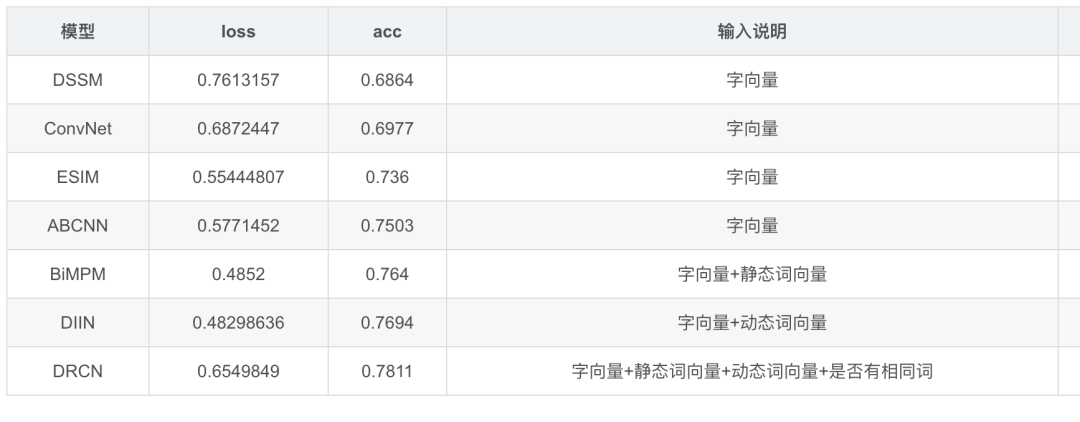
测试集结果对比:
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码