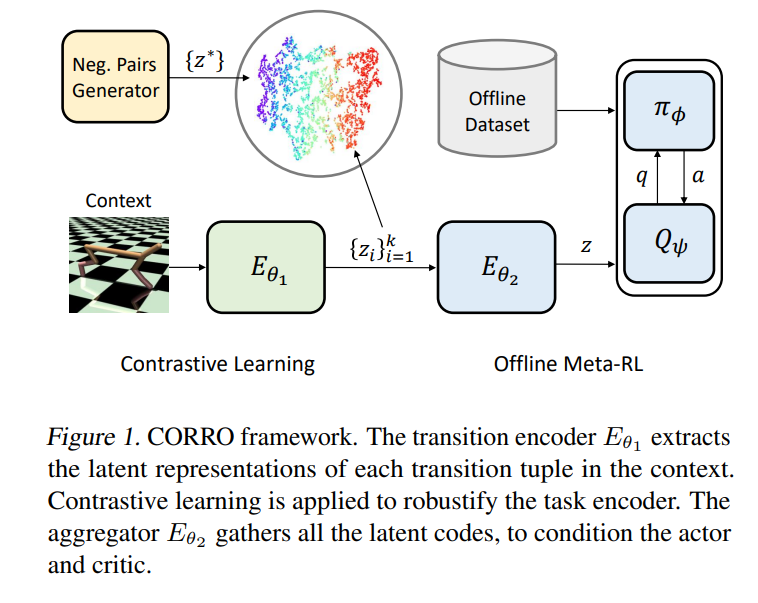
【ICML2022】基于对比学习的离线元强化学习的鲁棒任务表示数据派THU关注共 392字,需浏览 1分钟 ·2022-06-26 23:45 来源:专知本文为论文介绍,建议阅读5分钟我们的方法比以前的方法更有优势,特别是在泛化到非分布行为策略上。我们研究离线元强化学习,这是一种实用的强化学习范式,从离线数据中学习以适应新的任务。离线数据的分布由行为策略和任务共同决定。现有的离线元强化学习算法无法区分这些因素,导致任务表示对行为策略的变化不稳定。为了解决这个问题,我们提出了一个任务表示的对比学习框架,该框架对训练和测试中的行为策略分布不匹配具有鲁棒性。我们设计了一个双层编码器结构,使用互信息最大化来形式化任务表示学习,导出了一个对比学习目标,并引入了几种方法来近似负对的真实分布。在各种离线元强化学习基准上的实验表明,我们的方法比以前的方法更有优势,特别是在泛化到非分布行为策略上。代码可以在https://github.com/PKU-AI-Edge/CORRO上找到。 浏览 54点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Dopamine基于 Tensorflow 的强化学习框架Dopamine 是由 Google AI 实验室推出的一个基于 Tensorflow 的强化学习(Dopamine基于 Tensorflow 的强化学习框架Dopamine是由GoogleAI实验室推出的一个基于Tensorflow的强化学习(RL)框架,旨在为新手和资深RL研究人员提供灵活性、稳定性和可重复性。该框架受大脑中的奖励动机行为启发,反映了神基于强化学习的自动化剪枝模型视学算法0深度学习的发展方向: 深度强化学习!小白学视觉0深度学习的发展方向: 深度强化学习!Datawhale0Tianshou(天授)基于 PyTorch 的强化学习平台Tianshou(天授)是纯基于 PyTorch的强化学习平台,与现有的主要基于TensorFlow的强化学习库不同,Tianshou没有繁杂的嵌套类、不友好的API和速度较慢的代码,其提供了用于构建Tianshou(天授)基于 PyTorch 的强化学习平台Tianshou(天授)是纯基于 PyTorch 的强化学习平台,与现有的主要基于 TensorFl基于视觉模型强化学习的通用机器人小白学视觉0TensorLayer基于TensorFlow的新型深度学习和强化学习库TensorLayer是一个基于TensorFlow的新型深度学习和强化学习库,专为研究人员和工程师【深度学习】深度学习的发展方向: 深度强化学习!机器学习初学者0点赞 评论 收藏 分享 手机扫一扫分享分享 举报


 下载APP
下载APP