
ICLR 2021最佳论文放榜!清华宋飏等3位一作华人学生获最佳论文奖!

新智元报道
新智元报道
来源:iclr
编辑:LRS、yaxin
【新智元导读】ICLR2021 今天在官网公布了最佳论文奖!一作华人学生3篇论文获得了最佳论文奖,2篇来自Deepmind,还有谷歌、斯坦福大学等机构的研究人员都取得了佳绩。
刚刚,ICLR2021 公布了最佳论文奖!

今年,共有8篇最佳论文胜出,其中3篇是华人学生一作,2篇是来自Deepmind,还有谷歌、斯坦福大学等机构的研究人员都取得了佳绩。
ICLR 是深度学习领域的顶级会议,今年的 ICLR 2021大会从5月4日到5月8日在奥地利维也纳举行。
本届ICLR共收到了2997篇论文投稿,相比去年的2594篇论文投稿,增加了15.5%。
其中860篇论文被接收,接受率为28.7%,这些论文有53篇Oral,114篇Spotlight以及693 Poster。
8篇论文获最佳论文!华人一作占3席
最佳论文1:超复数乘法的参数量只需要1/n
标题:Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters
《比全连接更强:超复数乘法的参数量只需要1/n》
作者:Aston Zhang, Yi Tay, Shuai Zhang, Alvin Chan, Anh Tuan Luu, Siu Cheung Hui, Jie Fu
作者机构:谷歌研究院,苏黎世联邦理工大学,南洋理工大学,Mila
论文地址:https://openreview.net/pdf?id=rcQdycl0zyk
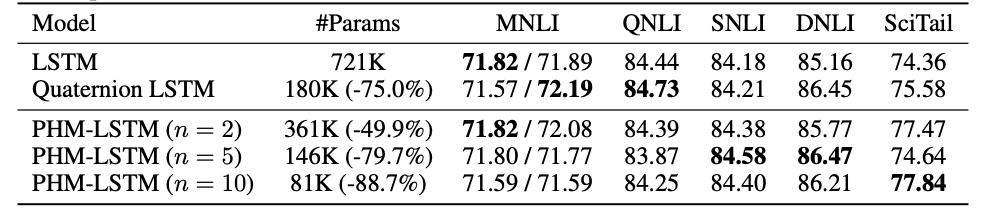
表示学习在超复数空间的表示学习的有效性已经得到了验证。基于四元数(quaternions)的全连接层(四元数就是四维空间的超复数)的汉密尔顿乘积已经取代了传统的实数矩阵乘法,并且在性能不变的情况下,可学习的参数量降低为原来的1/4,在多种应用场景得到了验证。
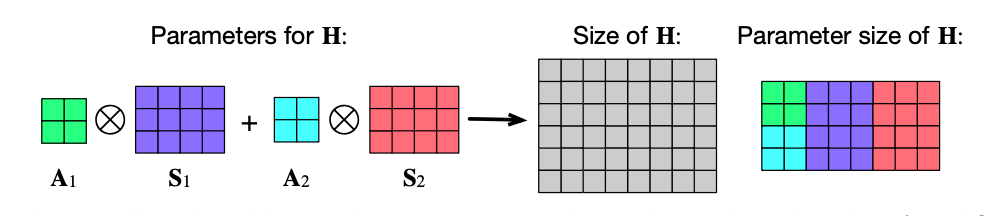
但是一个限制就是只有几个固定的维度可以使用,如四维、八维或十六维,为了使用超复数乘法,智能牺牲模型的灵活性。
基于这个目的,这篇文章提出了一种参数化超复数乘法,使模型能够与数据无关地学习乘法规则。这个模型不仅包括汉密尔顿乘积,通过设置任意1/n的可学习参数,也使模型更灵活。
使用LSTM和Transformer模型对自然语言推理、机器翻译、文本风格迁移的实验上,证明了所提出方法的架构灵活性和有效性。
本文的第一作者是Aston Zhang,是亚马逊Web Services的高级科学家,伊利诺伊大学香槟分校获得计算机科学博士学位。
出版《动手学深度学习》,面向中文读者的「能运行、可讨论」的深度学习教科书,被全球 40 个国家 175 所大学用于教学,由四位主要作者和GitHub贡献者共同编著。

最佳论文2 :重新思考可微分NAS方法中的架构选择
标题:Rethinking Architecture Selection in Differentiable NAS
作者:Ruochen Wang, Minhao Cheng, Xiangning Chen, Xiaocheng Tang, and Cho-Jui Hsieh
作者机构:加州伯克利大学
论文地址:https://openreview.net/forum?id=PKubaeJkw3
自谷歌2016年提出了基于强化学习神经网络架构搜索(NAS)一来,一些关于NAS方法泉涌而出,其中最有影响力的工作就是DARTS。
NAS以其搜索效率高、搜索过程简单等优点成为当前最流行的神经网络结构搜索方法之一。
它借鉴了早期谷歌提出的weight sharing的搜索思想,将搜索架构建模为矩阵α使用可微分的策略对矩阵α与网络参数进行交替优化,在分类和其他任务上都取得了很好的效果。
来自加州大学洛杉矶分校的研究人员发现DARTS有一些显而易见的缺点,他们重新审视了DARTS方法中的Architecture Selection,发现很多论文中都在重点讨论搜索中超图网络的优化问题,很少有学者去关注架构问题。
论文中作者重新评估了几个可微分的 NAS 方法与所提出的架构选择,发现架构参数α中的权重参数在很多情况下并不能衡量对应候选操作对于supernet的重要性。
在预训练DARTS supernet中随机选择了三条边,作者分别计算了其中不同候选操作对应的α值与离散化精度。
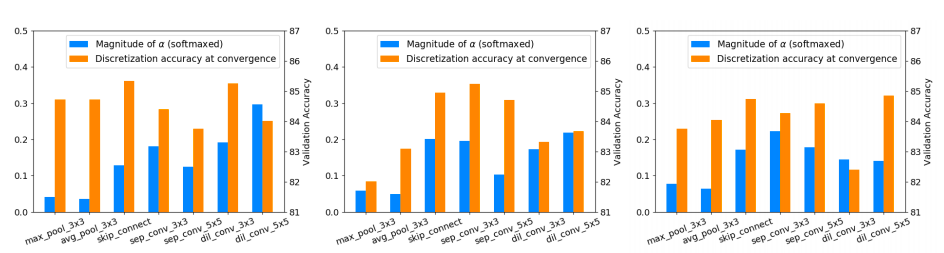
作者按照对搜索网络的贡献度来进行候选操作的选择,并进一步提出了一种alternative perturbation-based的架构选择方法,这一方法在DARTS、SDARTS、SDAS等一些NAS模型上取得了性能的提升。
论文一作Ruochen Wang来自洛杉矶加州大学(UCLA),他目前是UCLA亨利·萨穆埃利工程与应用科学学院研究生研究助理。
Ruochen Wang在2015年获得密歇根大学计算机科学、统计学学士学位,2020年获得密歇根大学和洛杉矶加州大学的计算机科学硕士学位。

最佳论文3:基于随机微分方程的分数生成式建模
标题:Score-Based Generative Modeling through Stochastic Differential Equations
作者:Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
作者机构:斯坦福大学,谷歌
论文地址:https://openreview.net/pdf?id=PxTIG12RRHS
从数据中生成噪声是很简单的,从噪声中找到数据则需要生成式的模型。这篇文章提出随机查分方程(SDE),通过逐渐注入噪声,把一个复杂的数据分布转换到一个已知的先验分布。另外一个对称的逆时SDE通过把噪声逐渐去处,把先验分布转换回数据分布。
至关重要的是,逆时SDE仅依赖于扰动数据分布的时间相关梯度场(场也叫做分数)。
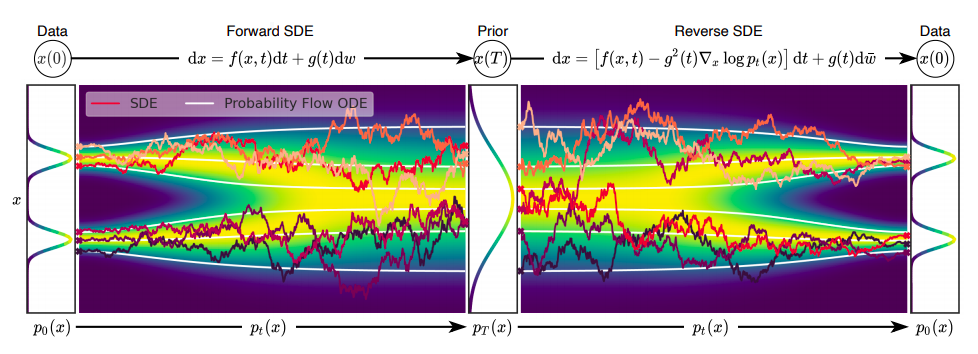
由于利用了基于分数的生成式模型的优势,这篇论文提出的模型能够准确地使用神经网络来估计分数,并且使用几个SDE求解器来生成样例。
论文中提出的框架封装了之前基于分数的生成式模型,扩散概率模型,兼容新的采样过程,并且具有不同的建模能力。
除此之外,一个预测校正器框架被用来纠正离散化的逆时SDE在演化过程中的误差。
一个等价的神经ODE能够从与SDE相同的分布中采样数据,额外计算精确的概率,提升采样效率。
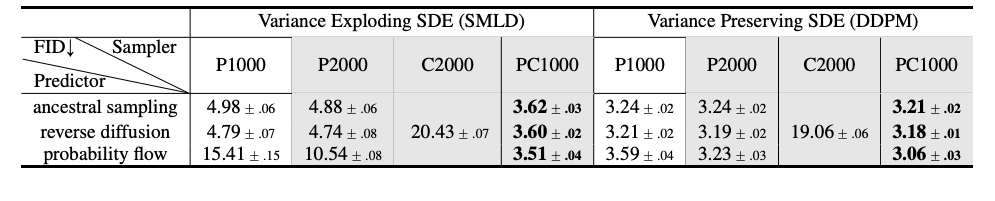
本文提供了一个新的途径使用基于分数的模型解决时序反向问题,在基于类别的生成、图像修复、着色实验中得到了验证。
由于多种架构上的改进,本文在CIFA-10数据集上的非条件图像生成实验上达到SOTA,评分9.89,FID 2.20,2.99bits/dim的概率,在1024*1024图像生成上,首次阐述了如何基于分数生成模型高保真地生成图像。

论文一作宋飏本科毕业于清华大学物理系,现为斯坦福大学计算机系博士生,他的导师是斯坦福大学计算机科学学院Stefano Ermon教授。
目前致力于研究具有灵活的模型结构,稳定的训练方式,优异的样本质量,以及能够自由控制的新型生成式模型。
他表示自己对生成模型的各种应用很感兴趣,比如解决逆问题,以及减少机器学习系统的安全漏洞。

还有5篇论文获得最佳论文奖,它们分别是:
论文4
标题:Complex Query Answering with Neural Link Predictors
作者:Erik Arakelyan, Daniel Daza, Pasquale Minervini, and Michael Cochez
作者机构:UCL 人工智能中心、阿姆斯特丹大学、Discovery Lab
论文地址:https://openreview.net/forum?id=Mos9F9kDwkz
论文5
标题:EigenGame: PCA as a Nash Equilibrium
作者:ZIan Gemp, Brian McWilliams, Claire Vernade, and Thore Graepel
作者机构:Deepmind
论文地址:https://openreview.net/forum?id=NzTU59SYbNq
论文6
标题:Learning Mesh-Based Simulation with Graph Networks
作者:Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter Battaglia
作者机构:Deepmind
论文地址:https://openreview.net/forum?id=roNqYL0_XP
论文7
标题:Neural Synthesis of Binaural Speech From Mono Audio
作者:Alexander Richard, Dejan Markovic, Israel D. Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, and Yaser Sheikh
作者机构:Facebook Reality Labs
论文地址:https://openreview.net/forum?id=uAX8q61EVRu
论文8
标题:Optimal Rates for Averaged Stochastic Gradient Descent under Neural Tangent Kernel Regime
作者:Atsushi Nitanda, and Taiji Suzuki
作者机构:东京大学,国立研究开发法人理化学研究所(Riken),科学技术振兴机构
论文地址:https://openreview.net/pdf?id=PULSD5qI2N1
参考资料:
https://iclr-conf.medium.com/announcing-iclr-2021-outstanding-paper-awards-9ae0514734ab
https://zhuanlan.zhihu.com/p/344538995
https://twitter.com/davencheung/status/1377584920453857286?s=21
