
【NLP】吊打BERT、GPT、DALL·E,跨模态榜单新霸主诞生!

文 | 赵一静
最近,三个重量级榜单,视觉推理VCR、文本推理ANLI、视觉问答VQA同时被统一模态模型UNIMO霸榜。一个模型统一了视觉和文本两大主阵地,重塑了小编的认知和期望。如此全能,堪称是AI领域的外(一)星(拳)选(超)手(人)!带着兴奋与好奇,我们来解读一下这篇ACL佳作!
论文题目:
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
论文链接:
https://arxiv.org/pdf/2012.15409
项目地址:
https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【0526】 下载论文PDF~
关于统一模态的野望,补补历史课
不谈历史无以谈模型,AI领域各自为王由来已久!NLP领域,18年Google BERT[1]横空出世,绝对实力统一文本理解,从此预训练+微调成为NLP的基本范式。19年后OpenAI接连发布GPT-2[2]/GPT-3[3],高调宣布GPT系列才是文本生成界的王者。CV领域,21年3月Swin Transformer[4]屠榜各大CV任务,有声音认为结束了卷积神经网络家族在该领域的统治。多模态领域,19年伊始ViLBERT[5]等一系列视觉-文字预训练工作大爆发,21年1月DALL.E[6]发布,文字生成图像技惊四座,搭配CLIP[7]使用炫技效果更佳...

这些模型都很伟大,但都存在一个问题,不够通用,自然也就限制了想象力!在单模文本数据上训练的模型便只能做自然语言处理,在视觉数据进行训练便只能做视觉任务,在图文数据上学习下游任务必须得是图文结合才行!显然,一个强大且通用的AI系统应该具备同时处理各种不同模态数据的能力。而目前的最优技术只能够在自身领域工作,一旦模型试图跨领域,直接不可用打脸。有同学说多模模型不可以做单模任务么?作为一个过来人,可以负责任的告诉你,君不见那效果跌的,惨不忍睹。也许,是时候重新审视这种狭义的多模态了,真正的多模态模型不应该对模态缺失这么敏感,而且应该比单模模型更强!
小编都能预感到历史的脉搏,难道AI巨头们看不到么?20年的最后一天,吴恩达邀请了顶级学者群,让大牛们对 2021 年的 AI 技术发展进行了一次展望,OpenAI 首席科学家 Ilya Sutskever就表达了类似的观点:
文本本身可以表达关于世界的大量信息,但它并不完备,因为我们也生活在视觉世界中。下一代 AI 模型将能够编辑文本输入并生成图像,我们也希望它们能够借由其见过的图像而更好地理解文本。联合处理文本和图像的能力将使模型变得更聪明。人类接触的不仅是阅读到的内容,还有看到和听到的内容。如果模型可以处理类似的数据,那么它们就能以类似人类的方式学习概念。这个灵感尚未得到证实,我希望 2021 年能够看到这方面的进展。
通俗点讲,不懂视觉的文本模型不是好AI,这个概念就是广义的多模态,或者说就是统一模态吧!
深入剖析UNIMO的算法设计
其实百度的嗅觉还挺敏锐的,扒一下UNIMO在arXiv的首次曝光,是在20年12月份,当时公布了Base版本小模型在部分任务上的效果,按照时间推演,20年中就已经在布局统一模态了,早于阿里M6[8]和悟道·文澜[9],后者在21年3月份提出了类似的模型概念。由于UNIMO首次从大模型大数据的角度正面直击统一模态概念和问题,且实验相对充分,拿来做解剖再合适不过。这次ACL论文放榜,UNIMO带来了更详细的方法描述和实验结果,我们来看一下!
想让模型同时具备单模应用能力和多模应用能力,甚至实现模态能力增强,配备大规模的多源异构数据资源是必不可少的,这也符合我们的认知。UNIMO使用了大量的文本数据、图像数据以及图文匹配数据进行联合学习,同时也让我们对语音、视频、以及网络上模态弱关联的数据的使用有了一些期待。互联网上的海量自然标注数据是我们取之不尽用之不竭的宝库,是真正意义上的One Piece!(PS:但是收集清理数据可是不容易呀)
不是有了大量数据,模型就能消化的了,我们也得看他的能力不是?UNIMO的核心网络是Transformer,同时为视觉和文本输入学习统一的语义表示空间。其中图像数据
在经过目标识别后被转换为视觉表示(visual token)序列,文本数据
被转换为词(word token)序列,图文对儿数据
被转换为视觉序列和词序列的拼接。这三种类型数据共享模型参数,经过多层注意力机制学习后得到视觉语言一体的上下文相关的语义表示。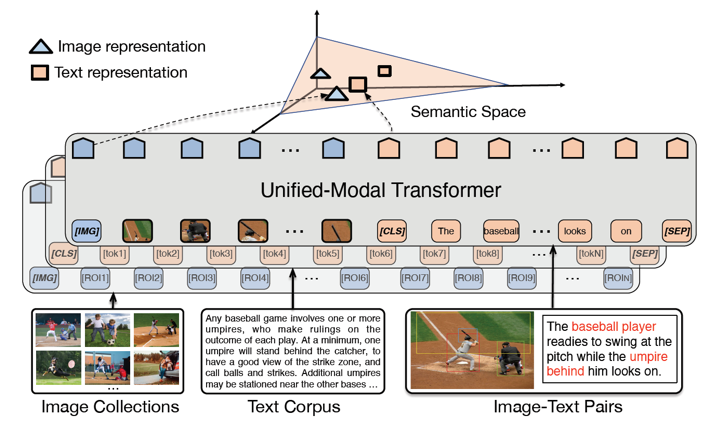
跨模态对比学习
为了能够使得多种模态输入能够兼容和相互增强,还需要好的学习机制来保障。Hinton老爷子在图像领域卖力宣传了一整年的对比表示学习(Contrastive learning)[10]当仁不让,UNIMO将其泛化到了跨模态层面。听起来,让模型不断地从模态内和模态间的对比中学习,确是一种行之有效的统一表示的手段,也是UNIMO成功的核心。跨模态对比学习(Cross-Model Contrastive learning,CMCL)的主要思想是使得含义相同的图文pair(正例)能够在语义空间上更接近,含义不同的图文pair(负例)在语义空间上要距离更远。从对比中学习,对正负例的质量、数量、学习技巧有很高的要求,UNIMO也毫不吝啬的使用了多种策略:
(1)文本改写(Text Rewriting):为了增强图文在多个粒度上的语义对齐能力,论文将图像的文本描述从句子级、短语级和词汇级别三个粒度进行了改写。在句子级层面,基于回译(Back Translation,即一句话机器翻译模型翻译成多种其他语言,再翻译回来,利用机器翻译模型的能力在不改变句子原始意图的前提下得到相同含义的其他形式句子)的技术来获得一张图片的多个正例文本。进一步,利用自然语言离散化符号的特性,基于TF-IDF相似度检索得到更多的字面词汇重复率高,但是含义不同的句子作为一张图片的强负样本。在短语级和词汇级别,首先将文本解析成场景图,然后随机替换掉其中的物体(object)、属性(attribute)和关系(relation)以及它们的组合,获得这两个粒度的强负例。
(2)图像/文本检索(Image and Text Retrieval):为了在跨模态学习中融合更多的单模态知识,图文对儿信息会被从大规模单模态数据中检索出来的背景知识进一步增强和丰富。这部分检索的数据会分别和图文对中的另一种模态数据组成弱相关对儿加入对比学习。妙就妙在这部分弱相关数据是由纯文本和纯图像数据源贡献的,我们知道单模数据在网络上是无穷尽、易收集的,这可以打开一新扇窗户。
正式地,对于图文对儿
,对比学习损失为:
其中,
,
和
分别代表强正例集合,图像检索的弱相关集合,文本检索的弱相关集合。
,
和
表示对应的负例集合。
一个很有意思的事情是,学术界对于建模图文对儿该走单流还是双流一直都有争论。单流模型派认为图像端和文本端共享单塔结构就可以,不需要独立建模,这样便于信息传递,这方面的代表工作有微软的UNITER等。双流模型派任务需要分开建模,这样在实际使用有优势,对于弱相关也能够处理的更好,这方面的代表工作有悟道·文澜等。而UNIMO图文模态是共享参数的,看似是单流模型,但是它进行弱相关数据对比的时候两种模态是分开建模的,走的却是双塔结构,同时发挥了这两种结构的优势,让人服气!
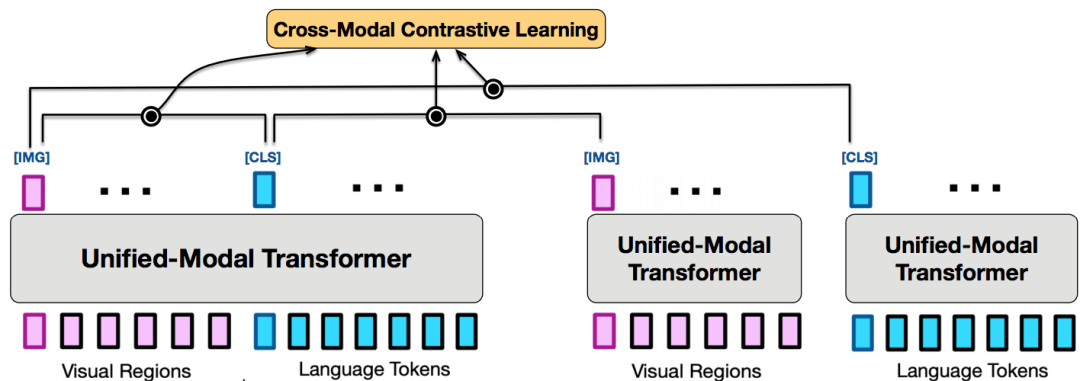
视觉和文本学习
单模态语料除了有一部分进入检索系统进行弱相关对比学习外,大量的会单独进行文本和视觉学习,这样的好处是可以避免遗忘问题,同时也可以迫使网络同时适应两种数据源,并间接注入另一种模态的原始记忆,提高泛化性能。另一方面,图文对数据也会充分利用模态上下文相关的特性设计辅助任务。
(1)视觉学习(Visual Learning):这个部分设计了和BERT的掩码语言模型类似的方法,从多个视觉区域中以一定概率随机选择一部分区域并进行掩盖(MASK),目标是利用剩下的区域信息还原重建这部分区域的原始特征。正式地,对于给定的图像
,被掩盖的区域为
,剩下的区域为
,则目标是最小化损失
类似地,对于图文对
,目标是利用文本信息和剩下的视觉区域来来重建被mask的区域
(2)文本学习(Language Learning):与视觉学习方法类似,仍然采用类似的掩码模型策略,以一定概率随机选择一部分连续token掩盖掉,目标是从剩下的上下文还原这部分内容。同时为了让模型能同时支持生成和理解两类目标,UNIMO设计了双向预测(Bidirectional prediction)和 序列生成(Seq2Seq Generation)两种损失:
最终,整个模型的优化目标是最小化所有损失的和
总体上,图像、文本、图文对三种数据是充分混合训练的,也就是说在一个大batch内会同时出现三种数据。论文公布的数据配比是1:1:5,小编猜想在训练阶段特别是在warmup时期对于技巧和手法应该有很高的要求。
实验
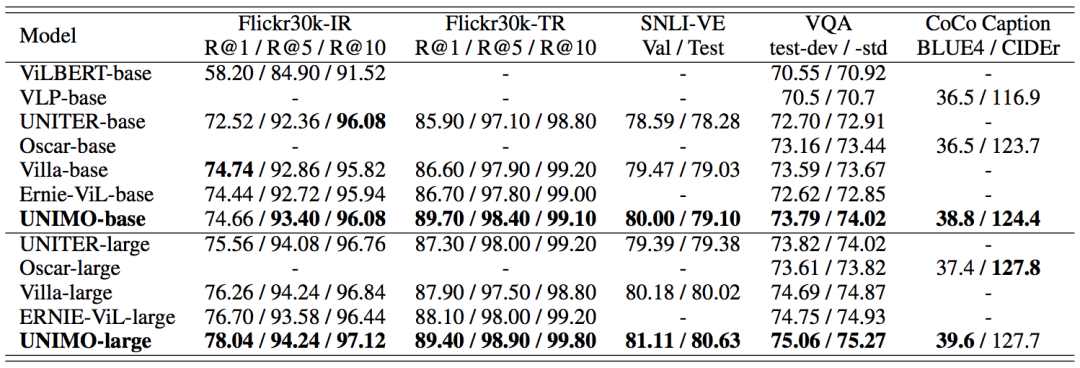
UNIMO的下游任务非常丰富。在文本生成任务上,选择了生成式对话问答数据集CoQA,问题生成数据集SQuAD-1.1,摘要数据集CNNDM和句子压缩数据集Gigaword。在文本理解任务上,选择了情感分类数据集SST-2,自然语言推断数据集MNLI,语言可接受度分类数据集CoLA和语义相关性数据集STS-B。多模理解任务上,选择了非常经典的视觉问答数据集VQA-2.0,视觉蕴含SNLI-VE和图文检索数据集Flickr30K。多模生成任务则选择了MS-COCO图像描述生成。
话不多说,直接上图。在多模任务上的结果非常亮眼,各大任务都是SOTA,特别是在检索任务上优势很大。从论文给出的Case Show来看,UNIMO着实在精准理解和捕捉细节方面表现更好。

值得一提的是,UNIMO在视觉推理(VCR)榜单上目前榜首,但是还没有在论文中公开对比结果。做过VCR任务的同学也许有了解,通用预训练在这个任务上没有太大作用,基本大家都靠领域二次pretrain刷分,由于UNINO融入了大量的单模语料,小编反而期待UNIMO能在通用能力上的效果对比。
最值得关注的还是在单模任务上的表现。w/o single-model这一行无情的揭开了目前多模态模型们的伤疤,管你在多模任务上表现多么厉害,给你基础的文本任务都做不好。CoLA效果直接跌掉50个点,简直对AI的通用能力要绝望了。没有对比就没有伤害,UNIMO的表现一如既往的稳定,这应该就是统一模态的优势吧。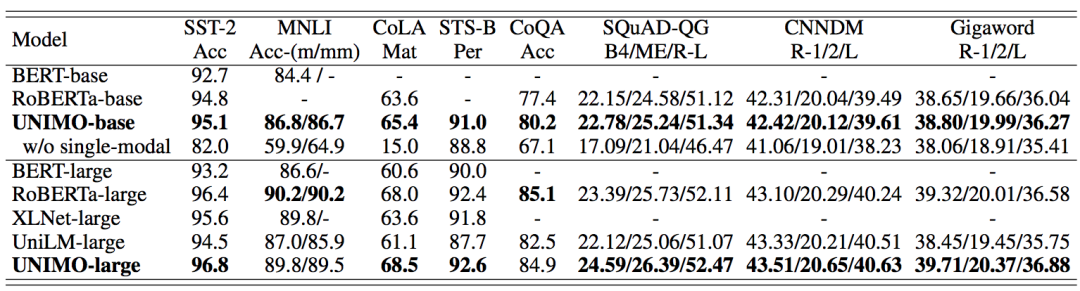
一些期待
我们说一个好的模型应该能经的起Challenge,这里小编也提出几点希望。
(1)变得更强。其实UNIMO的整体设计非常通用,由于它的训练过程中包括生成式辅助任务,所以应该可以直接支持文生图和DALL.E[6]掰手腕。其次,纯视觉任务的表现也可以拉出来溜溜。扩展到视频和语音也是必要的。
(2)长的更大。模型越大越好已经成为一种共识,UNIMO目前的参数只有Large的体量,显然这远远不够,只有长的更大才能让人见识到真的威力吧。
(3)吃的更多。其实论文全篇都在讲一件事,互联网上的所有数据都可以是UNIMO的食物。但是网络上更多的是弱相关的跨模态数据和单模数据,希望UNIMO能吃的下!
时代在呼唤一个统一的大模型,好在论文的Future Work已经提到了这方面的计划,期待的搓搓手吧。
结语
有人说,凡是个坑,都不好挖,能挖一坑,便能雄霸一方,挖多挖大,方能一统江湖。不得不说,UNIMO挖了一个新的大坑,也是一个好坑!
最后的最后,做一个预测,围绕统一模态的一系列工作, 今年将是井喷的一年,各位想毕业的Phd们,Paper拼手速啊。燃烧吧,GPU!
萌屋作者:赵一静
巴黎理工学院在读Phd,特长幽默,爱好自由,二次元宅,始终在减肥的路上!
往期精彩回顾
本站qq群851320808,加入微信群请扫码:
