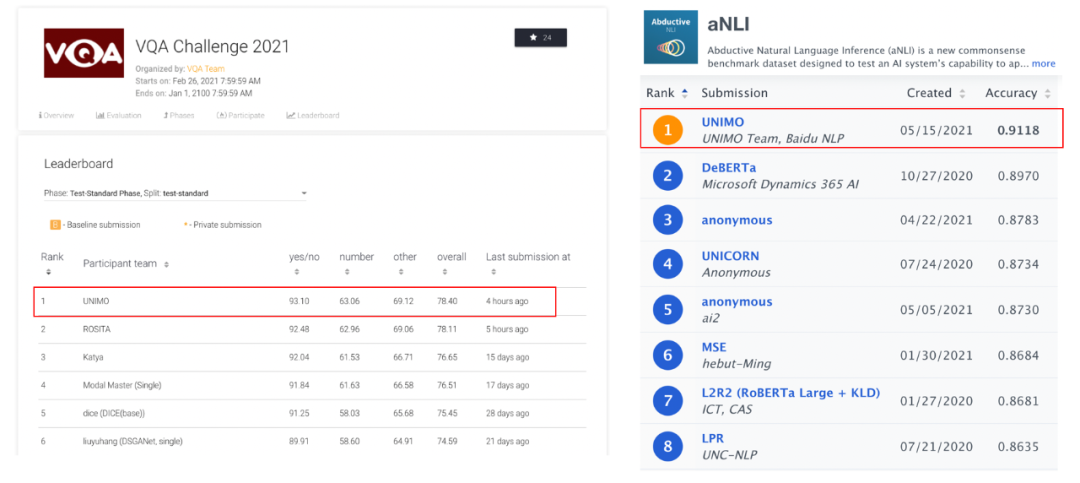
ACL 2021 | 百度NLP开源语言与视觉一体的统一模态预训练方法,登顶各类榜单
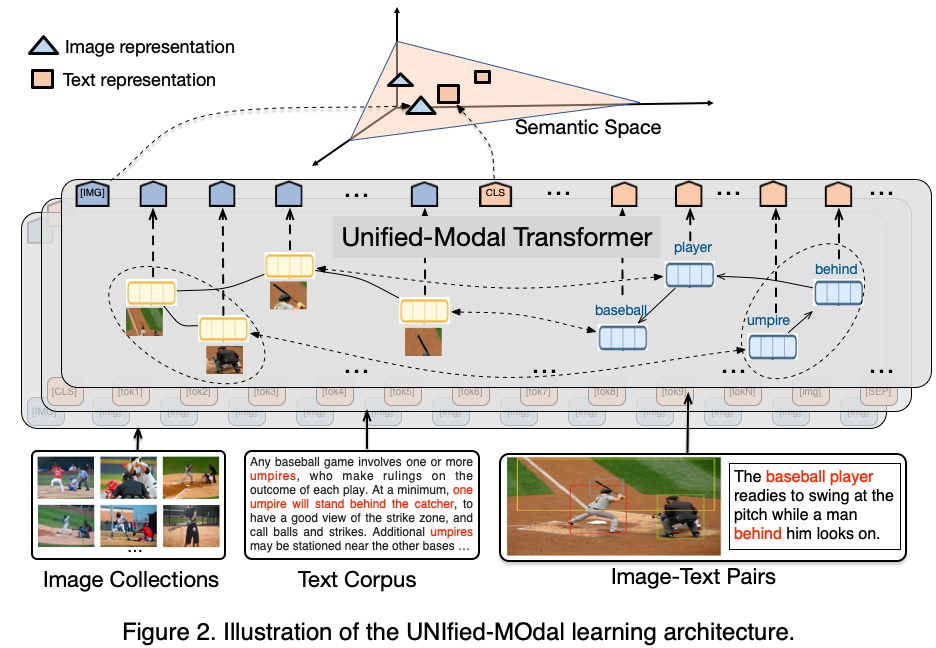
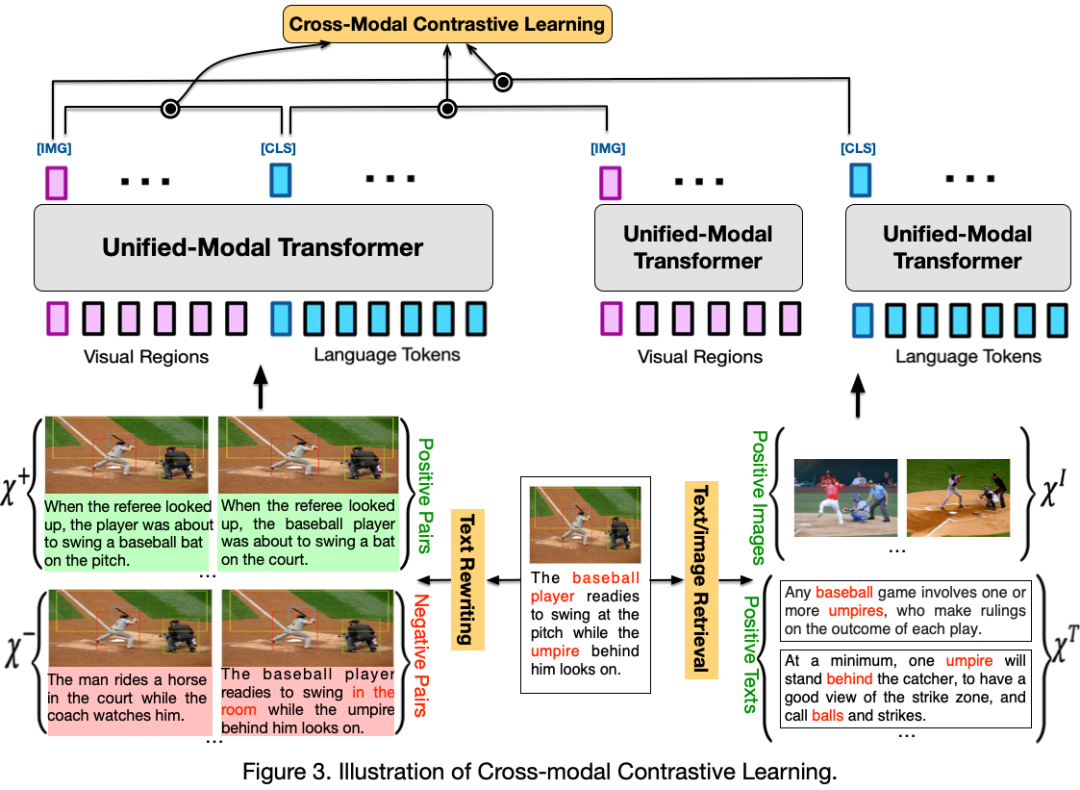
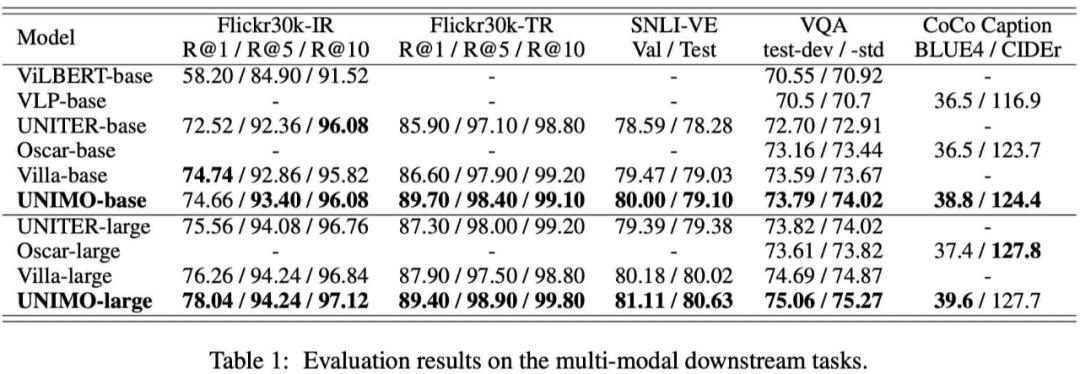
百度首创地提出了语言与视觉一体的预训练方法 UNIMO,提供了一种新的统一模态学习范式,打破了文本、图像和图文对等数据间的边界,让机器可以像人一样利用大规模异构模态数据,学习语言知识与视觉知识并相互增强,从而实现感知与认知一体的通用 AI 能力。






© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP百度首创地提出了语言与视觉一体的预训练方法 UNIMO,提供了一种新的统一模态学习范式,打破了文本、图像和图文对等数据间的边界,让机器可以像人一样利用大规模异构模态数据,学习语言知识与视觉知识并相互增强,从而实现感知与认知一体的通用 AI 能力。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!