
谁说GPT只擅长生成?清华研究力证:GPT语言理解能力不输BERT
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者|张倩、小舟
来源|机器之心
问:铅笔和烤面包机哪个更重? 答:铅笔比烤面包机重。

论文链接:
https://arxiv.org/pdf/2103.10385.pdf
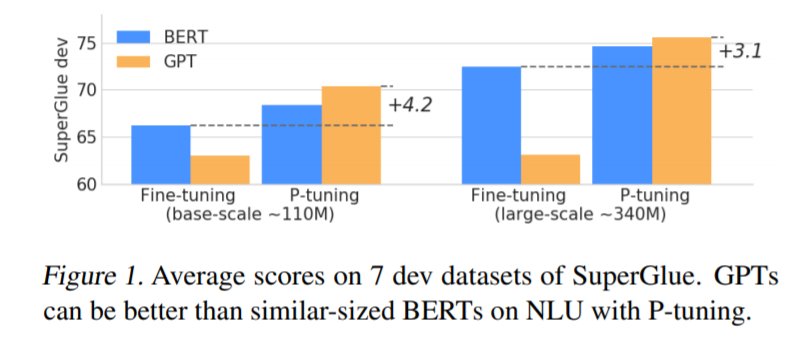
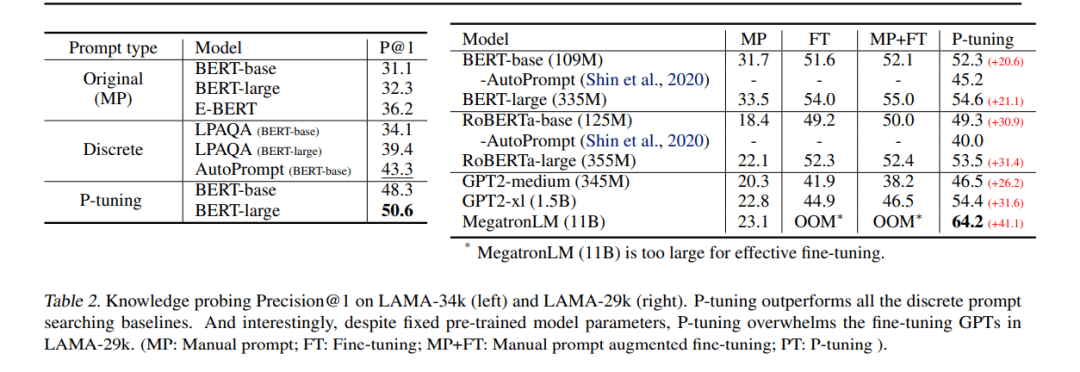
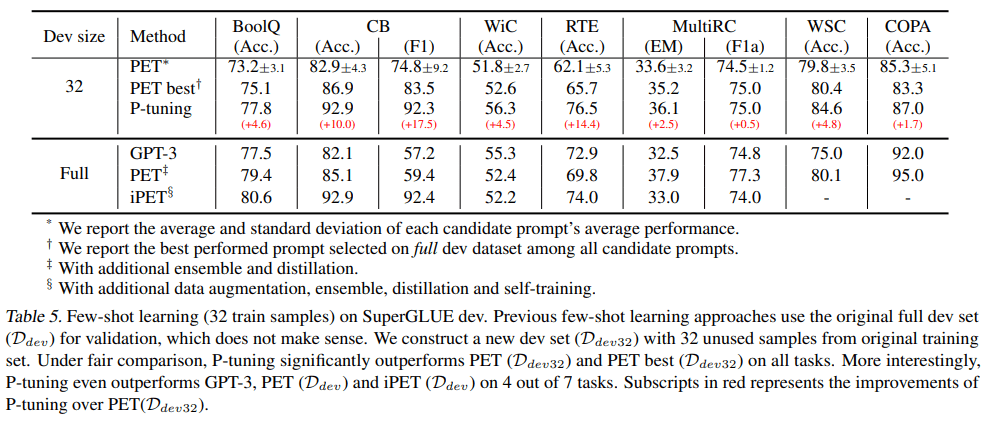
1. 表明在 P-tuning 的加持下,GPT 也能拥有和 BERT 一样强大(有时甚至超越后者)的自然语言理解能力,而 P-tuning 可以提高预训练语言模型的性能。这表明,GPT 类架构在自然语言理解方面的能力被低估了。
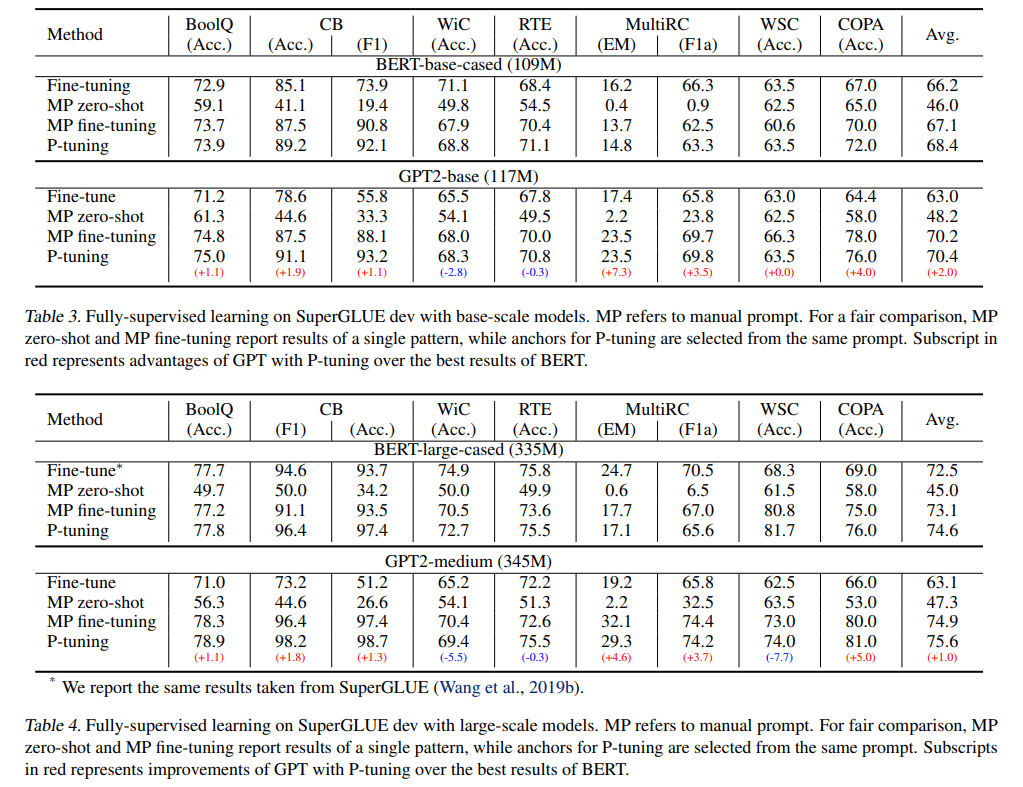
2. 表明 P-tuning 是一种提高 GPT 和 BERT 在 few-shot 和全监督场景中自然语言理解能力的通用方法。在 LAMA knowledge probing 和 few-shot SuperGLUE 两个基准的测试中,该方法优于之前的 SOTA 方法,表明语言模型在预训练过程中掌握的世界知识和 prior-task 知识比以往认为的要多。

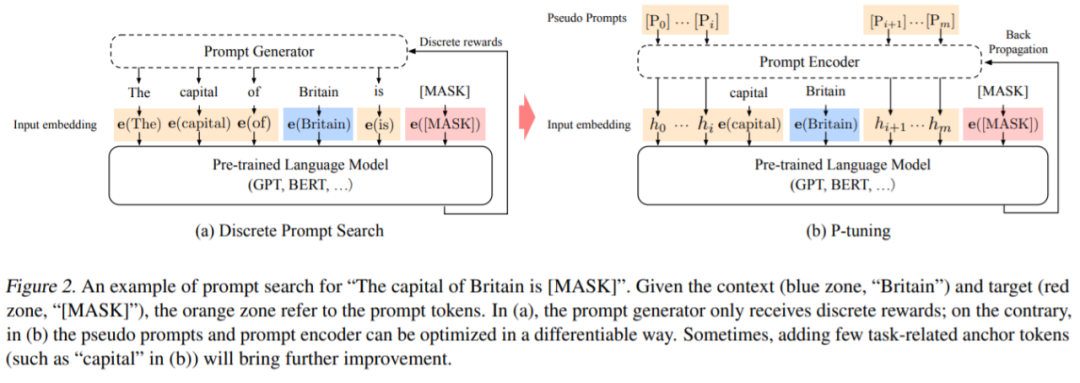
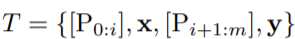 ,传统离散 prompt 满足 [P_i ] ∈ V 并将 T 映射到
,传统离散 prompt 满足 [P_i ] ∈ V 并将 T 映射到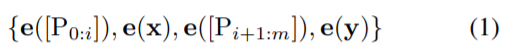
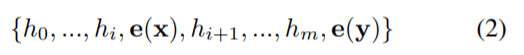
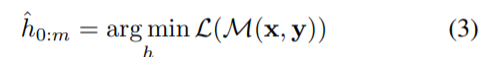


推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论