
如何用深度强化学习自动炒股

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
深度学习技术在股票交易上的应用研究调查
http://gregharris.info/a-survey-of-deep-learning-techniques-applied-to-trading/
文中缩写:
DBN = 深度信念网络
LSTM = 长短期记忆网络
MLP = 多层感知器
RBM = 受限玻尔兹曼机
ReLU = 修正线性单元
CNN = 卷积神经网络
限价委托单薄模型(Limit Order Book Modeling)
Sirignano(2016)提出一种预测限价委托单薄变化的方法。他开发了一个「空间神经网络(spatial neural network)」,该网络可以利用局部空间结构的优势,比标准的神经网络更具可解释性、也更具计算效率。他模拟了在下一状态变化时最好的出价和要价。
架构:每个神经网络有 4 层。标准的神经网络每个隐藏层有 250 个神经元,而该空间神经网络有 50 个。他在隐藏层神经元上使用双曲正切激活函数。
训练:他在 2014 年至 2015 年的 489 支股票的委托单薄上训练并测试了该网络(每支股票有一个单独的模型)。他使用了来自纳斯达克的 Level III 限价委托单薄数据,这些数据有着纳秒级别的十进制精度。训练包括了 50 TB 的数据,并且使用了 50 个 GPU 组成的集群。他总结了 200 个特征:现价委托单薄在首个 50 非零买入和卖出(bid/ask)水平的价格和大小。他使用 dropout 防止过拟合,并在每个隐藏层之间使用批规范化( batch normalization)来防止内部的协变量转变(covariate shift)。最后,使用 RMSProp 算法完成训练。RMSProp 类似于带有动量的随机梯度下降,但它通过一个过去梯度的移动平均(running average)对梯度进行规范化。他使用了一个自适应学习速率——在任何时候,当训练错误率随着训练时间增加时,这个学习速率就会按一定的常数因子下降。他使用一个被一个验证集强加的提前停止(early stopping)来减少过拟合。在训练时为了减少过拟合,他也用了一个 l^2 惩罚机制。
结果:他的结果显示限价委托单薄展现出了一定程度的局部空间结构。他能提前 1 秒预测委托单薄,也能预测下一次买入/卖出变化的时候。这一空间神经网络超过了标准的神经网络和没有线性特征的逻辑回归。这两种神经网络都比逻辑回归的错误率低 10%。
基于价格的分类模型
1.Dixon 等人(2016)使用一个深度神经网络预测 43 种大宗商品和外汇期货在接下来 5 分钟的价格变化。
架构:他们的输入层有 9896 个神经元,输入由滞后的价格差别和合同间的协动构成的特征。网络中有 5 层学习到的全连接层。4 个隐藏层中的第一层有 1000 个神经元,而且后面的每层逐次减少 100 个神经元。输出层有 129 个神经元(每一类 {-1,0,1} 对应 3 个神经元,乘以 43 个合同)。
训练:他们使用标准的带有随机梯度下降的反向传播方法进行训练。他们通过使用 mini-batching(依次在数个训练样本上计算梯度,而非单个样本) 加速训练过程。他们使用一个英特尔 Xeon Phi 协处理器进行训练,而非使用英伟达 GPU 。
结果:总体上,他们报告在三类分类上实现了 42% 的准确率。他们做了一些前行训练(walk-forward training),而非传统的回测(backtest)。他们的箱形图(boxplot)展示了一些来自每一合同 mini-backtest 的普遍积极的夏普比率。他们没有把交易成本或者交叉买入/卖出差价考虑在内。他们所有的预测和特征都基于每 5 分钟最后时刻的中间价位。
2.Takeuchi 和 Lee(2013)想要通过预测哪支股票将有比中值更高或更低的月度收益(monthly returns)来加强动量效应( momentum effect)。
架构:他们使用一个由堆栈 RBM 组成的自动编码器提取来自股票价格的特征,然后他们将特征送入一个前馈神经网络分类器。每个 RBM 包含由对称链(symmetric links)连接的可见单位层和隐藏单位层。第一层有 33 个单位,用于输入来自某个时候一支股票的特征。对每个月 t 而言,特征包括 t-2 月到 t-13 月 12 个月份的特征,以及对应 t 月的近似 20 天的回报。他们通过计算关于所有股票每个月或每天的横切面(cross-section)的 z-得分,正则化每个回报特征。编码器最终层的隐藏单位的数量急剧缩减,强迫降维。输出层有 2 个单位,对应股票是否低于或高于月度收益的中间值。最终层的大小依次为 33-40-4-50-2。
训练:在预训练期间,他们将数据集分割成更小的、非重叠性的 mini-batches。然后,他们展开 RBM 形成一个编码解码器,使用反向传播对其进行精调。他们考虑了所有在 NYSE、AMEX 或纳斯达克上交易的价格高于 5 美元的股票。他们在 1965 年至 1989 年的数据上进行训练(848,000 支股票的每月样本),并在 1999 年至 2009 年的数据上进行测试(924,300 支股票的每月样本)。一些训练数据被保留,作为层的数量和每层单位的数量的验证。
结果:他们总体的准确率大约是 53%。但他们考虑到预测前面十分之一股票和后面十分之一股票之间的差别时,他们得到每月 3.35% 的收益,或者每年 45.93% 的收益。
3.Batres Estrada(2015)预测哪个标准普尔 500 指数的股票在哪天将有高于中值的回报,而且他的研究看起来受到了 Takeuchi 和 Lee(2013)论文的影响。
架构:他使用一个 3 层 DBN 结合到一个 MLP。在每个隐层有 400 个神经元,而且他使用到了 S 形激活函数。输出层是一个带有两个输出神经元的 Softmax 层,进行的是二元分类(中值之上或之下)。DBN 由堆栈 RBM 组成,每个进行连续的训练。
训练:他首先预训练了 DBN 模块,然后使用反向传播精调整个 DBN-MLP。输入包括 33 个特征:t-2 至 t-13 月的月度对数收益率,20 支股票在 t 月的每日对数收益率,以及元月效应的指示变量。这些特征使用每个时间段的 Z 得分进行正则化。他使用了 1985 年至 2006 年的标准普尔 500 指数数据集,并按 70%、15% 和 15% 的比例分开分别用作训练、验证和测试。他使用验证数据选择层数、神经元数和正则化参数,也是使用 early-stopping 防止过拟合。
结果:他的模型有 53% 的准确率,超过了正则化逻辑回归以及一些 MLP 基线。
4.Sharang 和 Rao(2015)使用一个在技术指标上训练的 DBN 交易一系列美国中期国债期货。
架构:他们使用一个包含 2 个堆栈 RBM 的 DBN。第一个 RBM 是 Gaussian - Bernoulli(15 个节点),第二个 RBM 是 Bernoulli(20 节点)。DBN 产生隐藏的特征,他们尝试将这些特征输入进 3 个不同的分类器:正则化逻辑回归、支持向量机以及一个有 2 个隐层的神经网络。他们预测如果 5 天内投资组合上升则结果是 1,反之是 -1。
训练:他们使用一个对比差异算法训练 DBN。他们基于开仓、走高、走低、收盘利益和体量数据计算信号,这些数据最早的是 1985 年的,2008 年金融危机期间的一些点被移除了。他们使用 20 个特征:在不同时间段计算得到的「日常趋势」,然后进行规范化。所有的参数使用一个验证数据集进行选择。当训练神经网络分类器时,他们提到在 mini-batch 梯度下降训练期间使用一个动量参数将每次更新的系数收缩到一半。
结果:使用 PCA 构建的投资组合对第一主成分没有什么影响。这种投资组合是对工具的人工延展,所以真正的交易是在 ZF 和 ZN 合同之间的差价完成的。所有的输入价格是中间价,意味着买卖差价被忽略了。结果看起来是有益的,三种分类模型的准确率比随机预测器高 5%-10%。
5.Zhu 等人(2016)使用震荡箱理论( oscillation box theory)基于 DBN 做交易决策。震荡箱理论表示,一个股票价格将在某个时间段在固定范围内震荡。如果价格超出了这个范围,然后它就进入了一个新的震荡箱。作者想要预测震荡箱的边界。他们的交易策略是当价格超出了上边界则买入股票,它低于下边界时则卖出股票。
架构:他们使用一个由堆栈 RBM 构成的 DBN 以及一个最后的反向传播层。
训练:他们使用 block Gibbs sampling (块吉布斯采样)方法以一种无监督的方式贪婪地训练从低到高的每一层。然后,以监督方式训练反向传播层,它将精调整个模型。他们选择标准普尔 500 指数中的 400 支股票进行测试,而且测试集覆盖 2004 到 2005 年间的 400 天。他们使用了开仓、走高、走低、收盘价格,还有技术分析指标,作为全部的 14 个模型输入。一些指标通过使用灰色关联分析(gray relation analysis)或灰色关联度在预测中更具影响。
结果:在他们的交易策略中,每笔交易收取 0.5% 的交易成本,并为 stop-loss 和交易率增加了一些参数。我并未完全理解结果图,但报告称有极大的收益。
基于文本的分类模型
1.Rönnqvist 和 Sarlin (2016) 使用新闻文章来预测银行危机。具体来说,他们创造了一种分类器来评价一个给定的句子是否暗示了危机(distress)或安宁(tranquility)。
架构:他们在这篇论文中使用了两个神经网络。第一个用于语义的预训练,以减少维度。为了做到这一点,他们在文本上运行一个滑动窗口(sliding window),该窗口会取出一个包含 5 个词的序列然后学习预测下一个词。他们使用了一种前馈拓扑(feed-forward topology),其中一旦学习到了连接权重,中间的投射层(projection layer)就会提供语义向量。他们也将句子的 ID 包括到了该模型的输入中,以提供上下文语境和预测下一个词的信息。他们使用了二进制霍夫曼编码(binary Huffman coding)将句子 ID 和 词映射到输入层中的激活模式(activation pattern),这能依据频率粗糙地对词进行组织。他们说带有固定上下文大小的前馈拓扑在句子序列的建模上比循环神经网络更加高效。他们没有使用百万计的输入(一个词一个输入),而是使用了来自已经学到的语义模型的 600 个输入。其第一层有 600 个节点 ,中间层有 50 个修正线性隐藏节点,而输出层有两个节点(危机/安宁)。
训练:他们的训练使用了在 2007-2009 年金融危机中在 101 家银行上观察到的 243 个危机事件。他们使用了 71.6 万个提及银行的句子,这些句子选自危机期间或之后路透社(Reuters)的 660 万篇新闻文章。
结果:他们使用一种自定义的「有用性(Usefulness)」度量来评估他们的分类模型。评估通过交叉验证完成,并为每一个分类都分配了 N 家银行。他们将危机的数量聚集到了不同的时间序列,但却没有继续深入去考虑创造一种交易策略。
2.Fehrer 和 Feuerriegel (2015)训练了一个基于新闻头条预测德国股票收益的模型。
架构:他们使用了一种递归自编码器,在每一个自编码器上都有一个用于估计概率的附加 softmax 层。他们执行了三类预测 {-1, 0, 1} 来预测下一天与新闻头条相关的股票的收益。
训练:他们使用高斯噪声(aussian noise)对权重进行了初始化,然后通过反向传播进行更新。他们使用了一个英语的 ad-hoc 新闻发布数据集,其覆盖了 2004-2011 年之间关于德国市场的 8359 个头条新闻。
结果:他们的递归自编码器有 56% 的准确度,这比更传统的随机森林建模方法 53% 的准确度更好。他们没有开发交易策略,公开发布了一个他们的代码 Java 实施系统。
3.Ding 等人 (2015) 使用从新闻头条中提取出的结构化信息预测每天标准普尔 500 指数的运动。他们使用 OpenIE 处理头条来获取结构化的时间表征(执行器、动作、对象、时间)。他们使用一个神经张量网络通过成倍地结合事件参数(event argument)来学习它们的语义组合性(semantic compositionality),而不是像标准神经网络那样只是绝对量地学习。
架构:他们结合了短期和长期的事件影响,使用了一个 CNN 来执行输入事件序列的语义组合。他们在卷积层之上使用了一个最大池化层,这让该网络可以仅保留由卷积层生成的最有用的特征。他们有一个单独用于长期和中期事件的卷积层。这两个层与用于短期事件的输入层一起将信息馈送到一个隐藏层,然后再馈送到两个输出节点。
训练:他们从路透社和彭博社的新闻里提取出了 1000 万个事件。为了进行训练,他们使用随机参数替换事件参数的方式来制造虚假的事件。在训练过程中,他们假设真实事件应该比受损的事件得分更高。当情况不是这样时,就更新模型的参数。
结果:他们发现结构化事件是比预测股市的词更好的特征。他们的方法的效果比基准方法好 6%。他们预测了 S&P 500 指数和 15 支股票的情况,他们给出的表说明他们可以以 65% 的准确度预测标准普尔 500 指数。
波动预测
1.Xiong 等人 (2015)通过对开盘价、走高、走低和收盘价的估计来预测标准普尔 500 指数的日常波动。
架构:他们使用了一个包含一个 LSTM 模块的单一 LSTM 隐藏层。他们使用每日的标准普尔 500 指数的收益和波动作为输入。他们还囊括了 25 个国内的谷歌趋势,覆盖了行业和经济的主要领域。
训练:他们使用了每次批处理(batch)带有 32 个采样器的 Adam 方法,并使用平均绝对百分误差(MAPE)作为目标损失函数。他们设置了最大的 LSTM 延迟以便涵盖 10 个连续的观察。
结果:结果表明他们的 LSTM 方法比 GARCH、Ridge 和 LASSO 技术的效果都好。
投资组合优化
Heaton 等人(2016) 尝试创造一种优于生物技术指数 IBB 的投资组合。他们有一个目标:追踪少数股票和低验证误差的指数。他们也尝试在大规模下跌(drawdown)期间通过反相关(anti-correlated)来跑在指数的前面。他们没有直接对协方差矩阵建模,而是在深度架构拟合程序中进行训练,其允许出现非线性。
架构:他们使用了带有正则化和 ReLU 的自动编码。他们的自动编码器有一个带有 5 个神经元的隐藏层。
训练:他们使用了 2012-2016 年 IBB 成份股的每周收益数据。他们自动编码了该指数中的所有股票,并评估了每只股票和它的自动编码的版本之间的不同之处。他们也关注了数量不断变化的其它股票,该数量是通过交叉验证选择的。
结果:他们发现追踪误差是包括在投资组合中的股票数量的函数,但似乎并没有和传统的方法进行比较。他们也使用正收益替代了指数下跌,并找到了追踪这种修改过的指数的投资组合。
💡 初衷
最近一段时间,受到新冠疫情的影响,股市接连下跌,作为一棵小白菜兼小韭菜,竟然产生了抄底的大胆想法,拿出仅存的一点私房钱梭哈了一把。
第二天,暴跌,俺加仓
第三天,又跌,俺加仓
第三天,又跌,俺又加仓...
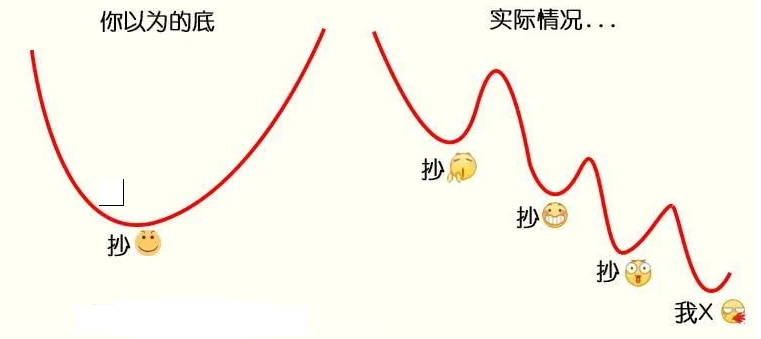
一番错误操作后,结果惨不忍睹,第一次买股票就被股市一段暴打,受到了媳妇无情的嘲讽。痛定思痛,俺决定换一个思路:如何用深度强化学习来自动模拟炒股? 实验验证一下能否获得收益。
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 炒股 即可获取。
AI项目体验地址 https://loveai.tech
单肩包/双肩包/斜挎包/手提包/胸包/旅行包/上课书包 /个性布袋等各式包饰挑选
https://shop585613237.taobao.com/
📖 监督学习与强化学习的区别
监督学习(如 LSTM)可以根据各种历史数据来预测未来的股票的价格,判断股票是涨还是跌,帮助人做决策。
而强化学习是机器学习的另一个分支,在决策的时候采取合适的行动 (Action) 使最后的奖励最大化。与监督学习预测未来的数值不同,强化学习根据输入的状态(如当日开盘价、收盘价等),输出系列动作(例如:买进、持有、卖出),使得最后的收益最大化,实现自动交易。
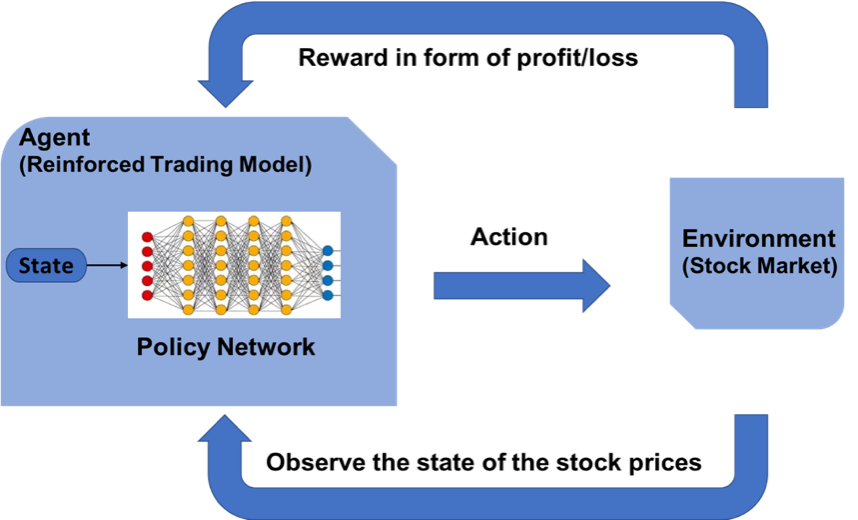
🤖 OpenAI Gym 股票交易环境
观测 Observation
策略网络观测的就是一只股票的各项参数,比如开盘价、收盘价、成交数量等。部分数值会是一个很大的数值,比如成交金额或者成交量,有可能百万、千万乃至更大,为了训练时网络收敛,观测的状态数据输入时,必须要进行归一化,变换到 [-1, 1] 的区间内。
| 参数名称 | 参数描述 | 说明 |
|---|---|---|
| date | 交易所行情日期 | 格式:YYYY-MM-DD |
| code | 证券代码 | 格式:sh.600000。sh:上海,sz:深圳 |
| open | 今开盘价格 | 精度:小数点后4位;单位:人民币元 |
| high | 最高价 | 精度:小数点后4位;单位:人民币元 |
| low | 最低价 | 精度:小数点后4位;单位:人民币元 |
| close | 今收盘价 | 精度:小数点后4位;单位:人民币元 |
| preclose | 昨日收盘价 | 精度:小数点后4位;单位:人民币元 |
| volume | 成交数量 | 单位:股 |
| amount | 成交金额 | 精度:小数点后4位;单位:人民币元 |
| adjustflag | 复权状态 | 不复权、前复权、后复权 |
| turn | 换手率 | 精度:小数点后6位;单位:% |
| tradestatus | 交易状态 | 1:正常交易 0:停牌 |
| pctChg | 涨跌幅(百分比) | 精度:小数点后6位 |
| peTTM | 滚动市盈率 | 精度:小数点后6位 |
| psTTM | 滚动市销率 | 精度:小数点后6位 |
| pcfNcfTTM | 滚动市现率 | 精度:小数点后6位 |
| pbMRQ | 市净率 | 精度:小数点后6位 |
动作 Action
假设交易共有买入、卖出和保持 3 种操作,定义动作(action)为长度为 2 的数组
action[0]为操作类型;action[1]表示买入或卖出百分比;
动作类型 action[0] | 说明 |
|---|---|
| 1 | 买入 action[1] |
| 2 | 卖出 action[1] |
| 3 | 保持 |
注意,当动作类型 action[0] = 3 时,表示不买也不抛售股票,此时 action[1] 的值无实际意义,网络在训练过程中,Agent 会慢慢学习到这一信息。
奖励 Reward
奖励函数的设计,对强化学习的目标至关重要。在股票交易的环境下,最应该关心的就是当前的盈利情况,故用当前的利润作为奖励函数。即当前本金 + 股票价值 - 初始本金 = 利润。
# profits
reward = self.net_worth - INITIAL_ACCOUNT_BALANCE
reward = 1 if reward > 0 else reward = -100
为了使网络更快学习到盈利的策略,当利润为负值时,给予网络一个较大的惩罚 (-100)。
策略梯度
因为动作输出的数值是连续,因此使用基于策略梯度的优化算法,其中比较知名的是 PPO 算法,OpenAI 和许多文献已把 PPO 作为强化学习研究中首选的算法。PPO 优化算法 Python 实现参考 stable-baselines。
🕵️♀️ 模拟实验
环境安装
# 虚拟环境
virtualenv -p python3.6 venv
source ./venv/bin/activate
# 安装库依赖
pip install -r requirements.txt
股票数据获取
股票证券数据集来自于 baostock,一个免费、开源的证券数据平台,提供 Python API。
>> pip install baostock -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn数据获取代码参考 get_stock_data.py
>> python get_stock_data.py将过去 20 多年的股票数据划分为训练集,和末尾 1 个月数据作为测试集,来验证强化学习策略的有效性。划分如下
1990-01-01 ~ 2019-11-29 | 2019-12-01 ~ 2019-12-31 |
|---|---|
| 训练集 | 测试集 |
验证结果
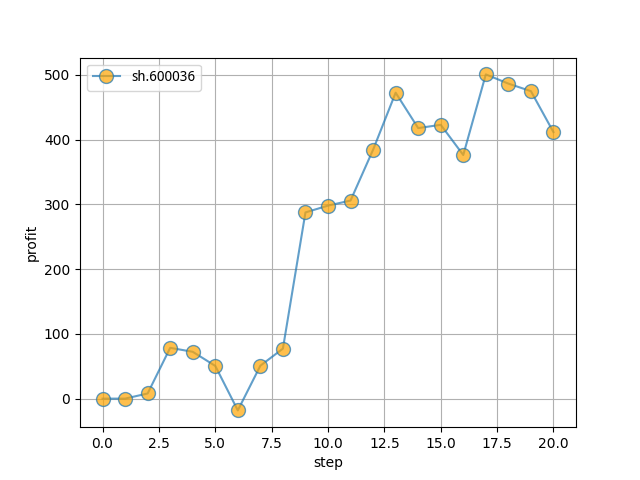
单只股票
初始本金
10000股票代码:
sh.600036(招商银行)训练集:
stockdata/train/sh.600036.招商银行.csv测试集:
stockdata/test/sh.600036.招商银行.csv模拟操作
20天,最终盈利约400
多只股票
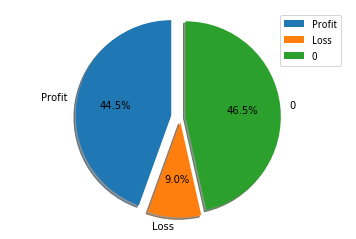
选取 1002 只股票,进行训练,共计
盈利:
44.5%不亏不赚:
46.5%亏损:
9.0%
👻 最后
股票 Gym 环境主要参考 Stock-Trading-Environment,对观测状态、奖励函数和训练集做了修改。
俺完全是股票没入门的新手,难免存在错误,欢迎指正!
数据和方法皆来源于网络,无法保证有效性,Just For Fun!
📚 参考资料
Y. Deng, F. Bao, Y. Kong, Z. Ren and Q. Dai, "Deep Direct Reinforcement Learning for Financial Signal Representation and Trading," in IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 3, pp. 653-664, March 2017.
Yuqin Dai, Chris Wang, Iris Wang, Yilun Xu, "Reinforcement Learning for FX trading"
Chien Yi Huang. Financial trading as a game: A deep reinforcement learning approach. arXiv preprint arXiv:1807.02787, 2018.
Create custom gym environments from scratch — A stock market example
notadamking/Stock-Trading-Environment
Welcome to Stable Baselines docs! - RL Baselines Made Easy