
AutoEncoder (AE) 和 Variational AutoEncoder (VAE) 的详细介绍和对比

来源:DeepHub IMBA 本文约2000字,建议阅读8分钟
本文对分别用于数据压缩和数据生成AE和VAE进行了详细的介绍。
数据压缩
Autoencoder - AE
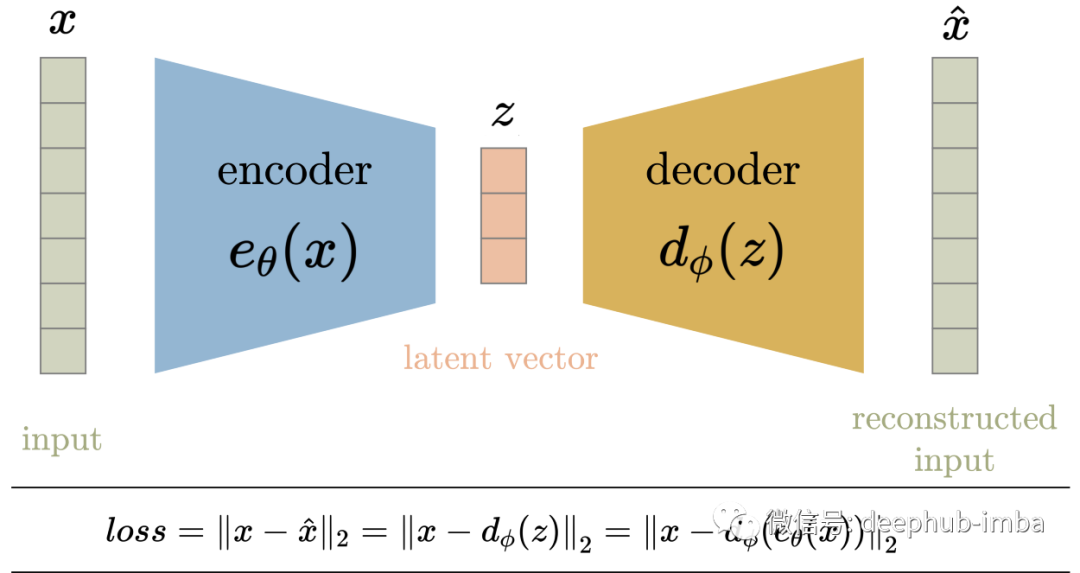
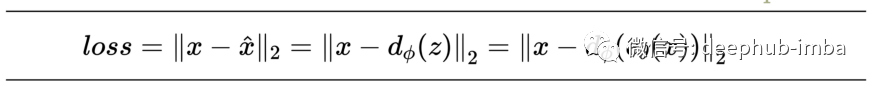
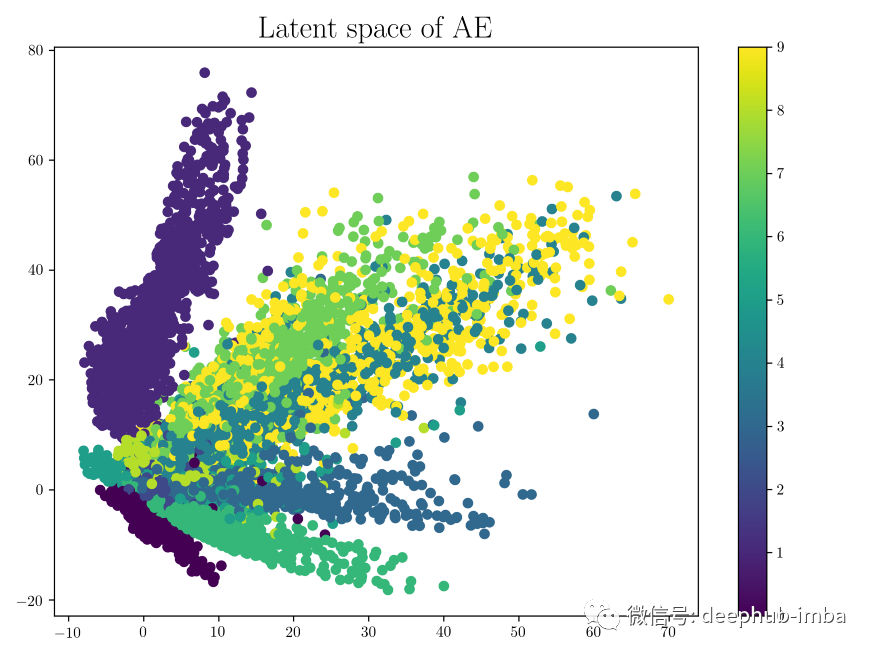
Variational AutoEncoders - VAE
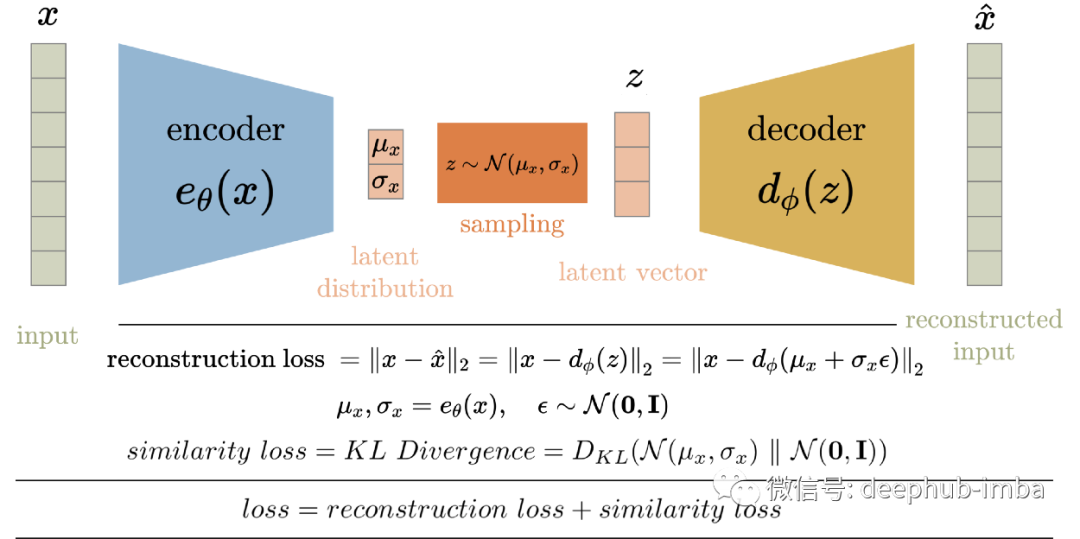
重建的输入; 潜空间应为正态分布;
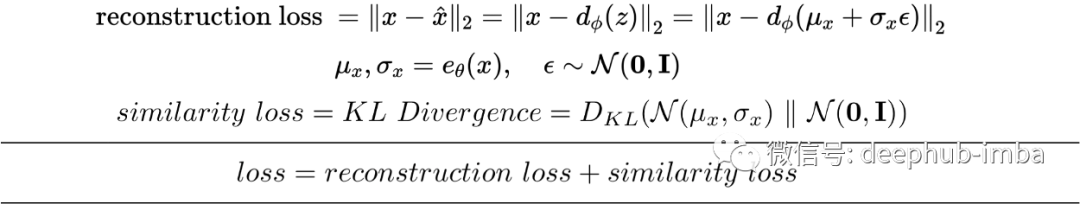
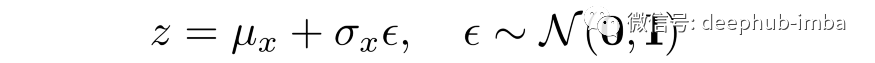
总结
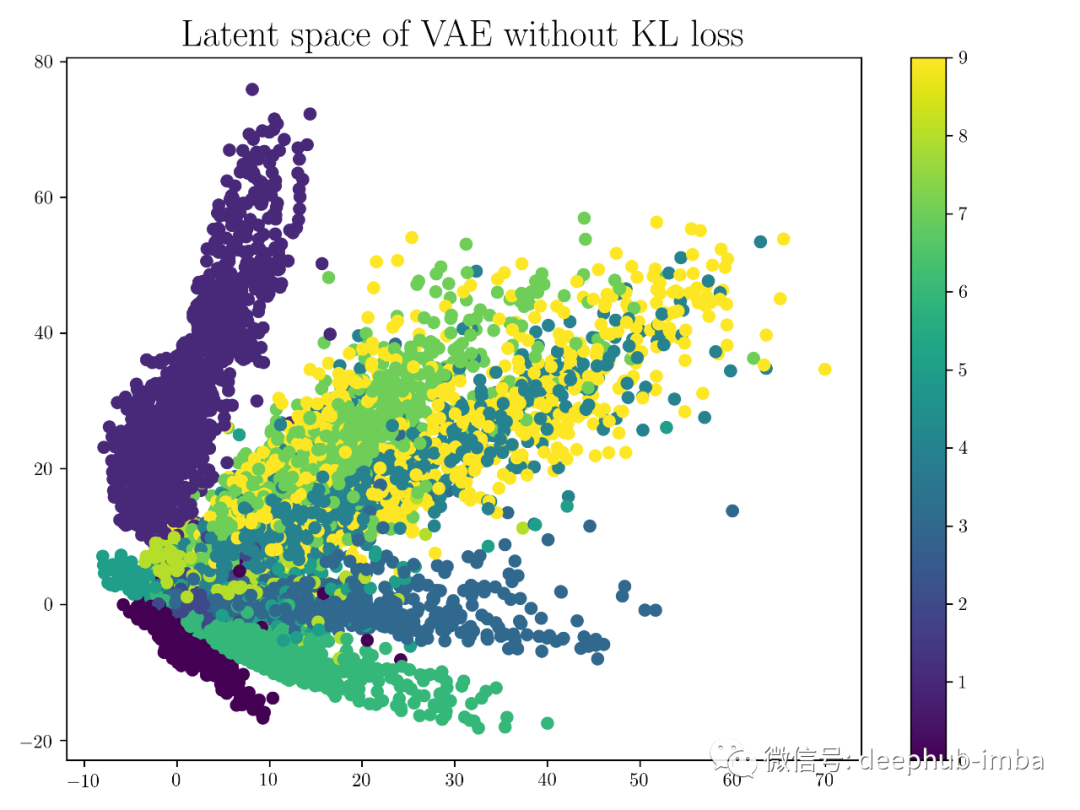
用于在潜在空间中生成输入的压缩变换; 潜变量没有被正则化; 选择一个随机的潜在变量可能会产生垃圾输出; 潜变量具有不连续性; 潜在变量是确定性值; 潜在空间缺乏生成能力;
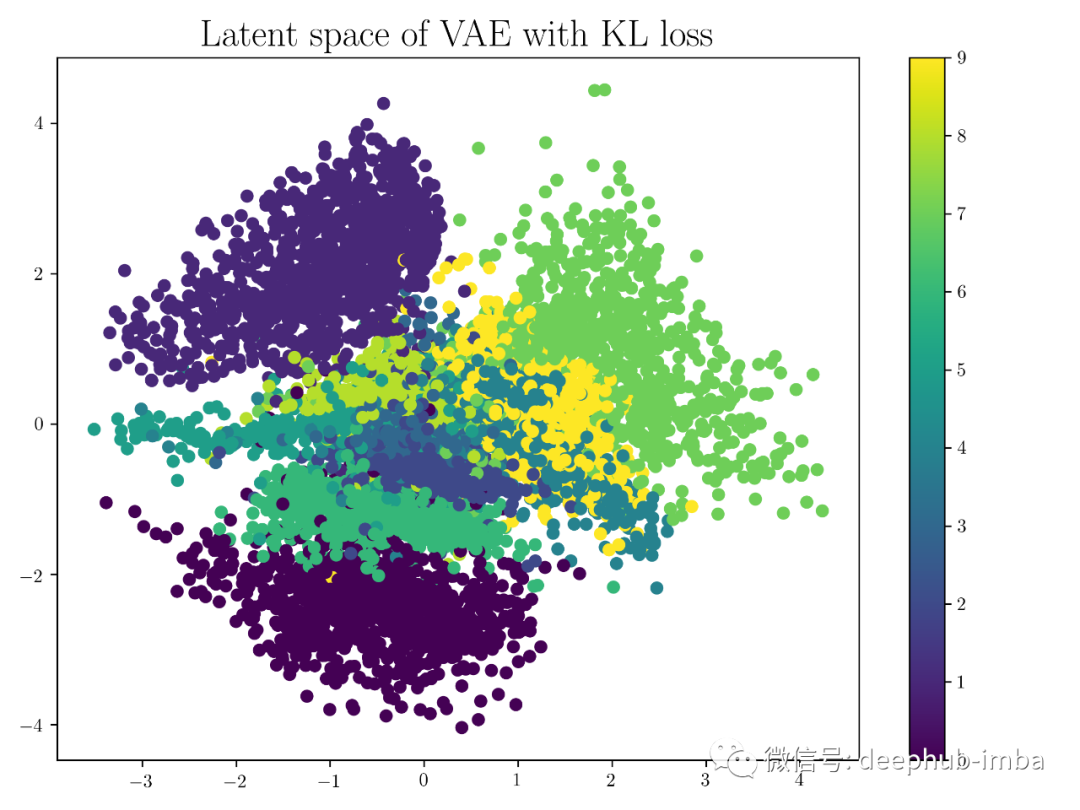
将潜在变量的条件强制为单位范数; 压缩形式是潜在变量的均值和方差; 潜在变量是平滑连续的; 潜在变量的随机值在解码器产生有意义的输出; 解码器的输入是从具有编码器输出均值和方差的高斯中采样的随机值; 正则化的潜在空间; 潜在空间具有生成能力;
评论