
跟着李宏毅老师学习 Autoencoder 的各类变体及应用
编辑 | 机器学习与数学
常常见到 Autoencoder 的变体以及应用,打算花几篇的时间好好研究一下,顺便练习 Tensorflow.keras 的 API 使用。
Overview
What is Autoencoder Types of Autoencoder Application of Autoencoder Implementation Great examples Conclusion
Difficulty: ★ ★ ☆ ☆ ☆
1What is Autoencoder?
首先,什么是 Autoencoder 呢? 不啰唆,先看图吧!

Autoencoder 最原始的概念很简单,就是丢入一笔 input data 经过类神经网路后也要得到跟 input data 一模一样的 data。首先,整个 Autoencoder 可以拆解成 Encoder 和 Decoder 两个神经网路。Encoder 先吃进 input data,经过神经网路后压缩成一个维度较小的向量 Z,接着,再将 Z 输入 decoder 中,将 Z 还原成原始大小。听起来很容易,但是我们仔细来瞧瞧,这件事情是不是那么的容易我们就一步一步的分开来看!
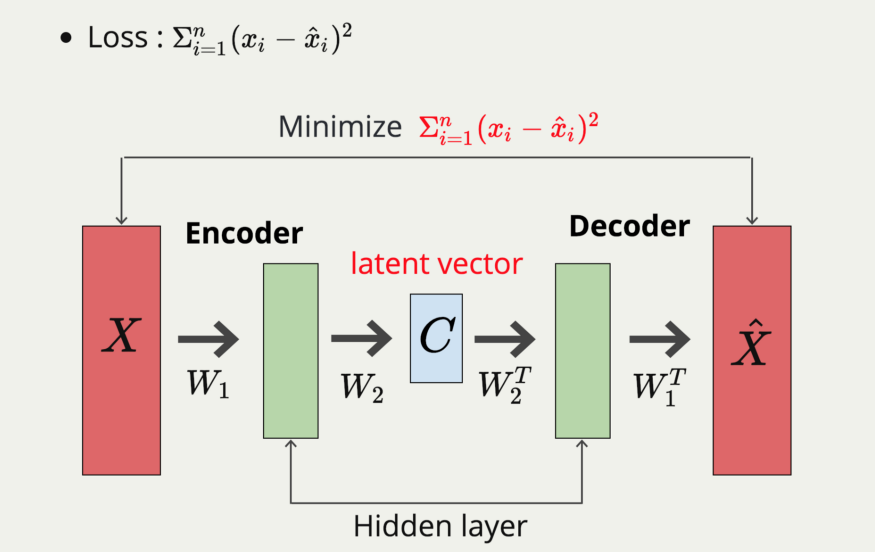
Encoder: Encoder 负责将原始的输入 Input data,压缩成成低维向量 C,这个 C,我们通常称作 code、latent vector 或者特征向量,但我习惯叫它 latent space,因为 C 表示隐藏的特征。Encoder 可以将原始 data 压缩成有意义的低维向量,也就表示 Autoencoder 有降维的功能,经过的 hidden layer 拥有非线性转换的 activation fuction,那么这个 Encoder 就像是强力版的 PCA,因为 Encoder 能够做到 non-linear dimension reduction!
Decoder: Decoder 要做的事情就是将 latent space 尽量地还原回去 input data,是一将低维空间的特征向量转换到高维空间中。
那么怎么衡量 Autoencoder 的工作状况呢!? 很简单,就是去比较两个原始的 input data 与 reconstructed data 的相似程度。因此我们的 Loss function 可以写为,
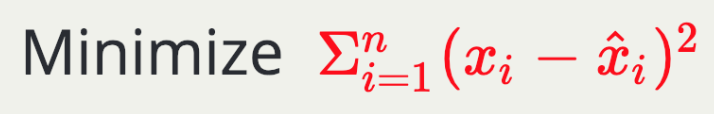
因为要尽可能缩小两笔 data 的差异,我们很自然的就使用 mean square error 做为 loss function (但实作上都使用 cross_entropy,这个后面的章节再讲 XDD )。AutoEncoder 的训练方法跟一般的神经网路一样,都是用 Backpropagation 去更新权重。做个小结,Autoencoder 是,
很常见到的模型架构,也是常见的 unsupervised learning。 可以做为 non-linear 的 dimension reduction 的一种方法。 可以学到 data representation,有代表性的特征转换。
讲到这边,应该可以很轻松的理解,Autoencoder 是怎么样的的一个东西了,架构很简单,那再来就来看看他的变形吧!
2各类 Autoencoder
讲解了 AutoEncoder 的基本原理之后,那就可以来看一下 Autoencoder 的延伸进阶使用,让大家看一下 Autoencoder 的广泛使用!
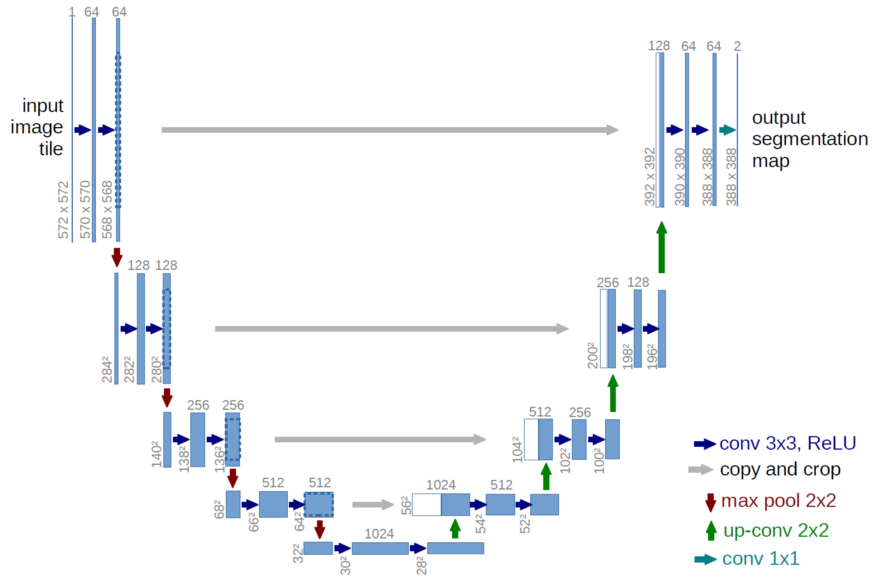
2.1Unet
Unet 可以作为 image segmentation 实作的其中一个手段,而 Unet 的架构也可以看作为 Autoencoder 的变型。但训练时 input 为一个 image,而 ouput 则是 segmentation 的 mask。
2.2Recursive Autoencoders
这是一个将新的输入文字结合其他输入的 latent space 的网路,这个网路的目的是情绪分类,而如此这个网路便可以提取不断输入的 sparse 文字,找出重要的 latent space。这个也可以看作是Autoencoder 的变形。

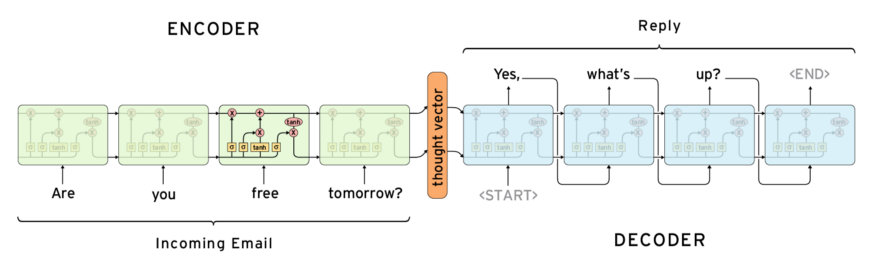
2.3Seq2Seq
Sequence to Sequence 是前阵子很红的生成式模型,它精彩地解决了 RNN 类型无法处理不定长配对的困境,在 chatbot、文字生成等主题上都有很好的表现。而这个也可以看做一种 Autoencoder 的架构。
3Autoencoder 的应用
看完了千奇百怪的 Autoencoder 变形后,来看看 Autoencoder 还可以在哪些场合使用吧!
3.1Model pretrained weight
Autoencoder 也可以用于 weight 的 pretrain,pretrain 的意思即为让模型找到一个较好的起始值。用下图来举例,当我们想要完成的目标模型如 target。hidden layer 分别为: [1000, 1000, 500],因此在一开始我们使用 autoencoder 的概念输入 784 维,中间的 latent space 为 1000 维先去做 pretrain,因此这 1000 维就可以很好的保留住 input 的资讯,接着我们把原本的 output 拔掉,在接上第二层,以此类推的做下去。这样子整个模型就会得到一个比较好的起始值。
咦! 有个地方怪怪的 … 如果你用 1000 neuron 去表示 784 维的 input 的话,不就代表 network 只要全部复制一遍就好了吗!? 还需要什么训练呀ˋˊ!没错,所以有在像这样的 pre-train 时,通常我们都会加上 L1 norm 的 regularizer,让 hidden layer 不要全部复制一遍。
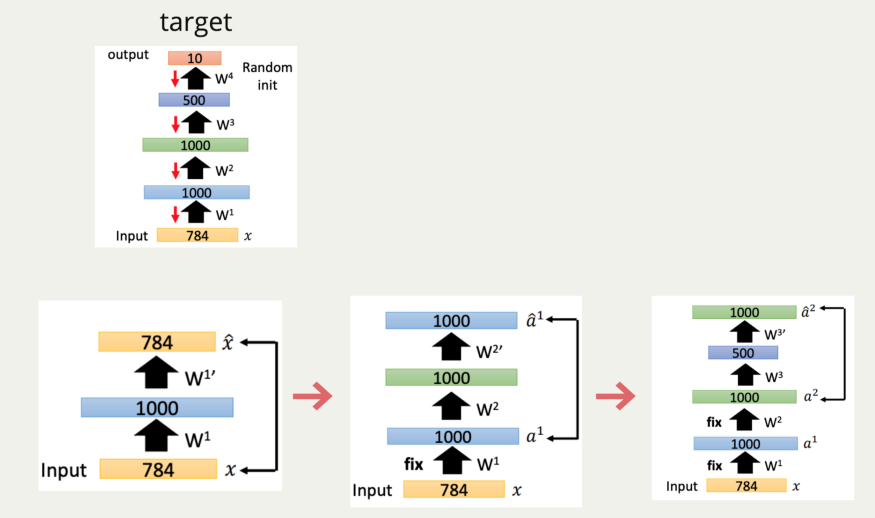
根据李宏毅老师的说法,在过去比较会使用如此的方法去做 pre-train,现在由于 training skill 的增加,已经不需要使用这种方法了。但是如果你有的 label data 非常少,但却有一堆的没 label data 时,你就可以用这样的方法去做 weight pre-train ,因为 Autoencoder 本身就是一个 unsupervised learning 的方法,我们用没 label 过的 data 先得到 weight 的 pre-train,再用有 label 的 data 去 fine-tune 权重,如此一来就可以得到不错的模型。详细的细节可以再看李老师的影片,讲解的很好!
3.2Image segmentation
刚刚看到的 Unet 模型,我们就再来看看,因为这基本上就是台湾制造业最常见到的 defect detection 的问题。
首先我们要先将 input data label 好,这会是我们的 output,我们要做的事情就是建构一个 network,输入原始的图片(左图,牙齿 X 光照)后,要产生 output ( 右图,牙齿构造分类) 。那在这种 case 上,encoder & decoder 都会是图形判断较为强大的 convolution layers,萃取出有意义的特征,并在decoder 里 deconvolution 回去,便可以得到 segmentation 的结果。

3.3Video to Text
像这样的 image caption 问题,想当然尔的就用到 sequence to sequence 模型拉,input data 是一堆的照片,output 则是描述照片的一段文字,在这边的 sequence to sequence 模型,我们会使用 LSTM + Conv net 当作encoder & decoder,可以很好的描述一连串的有顺序性的动作 & 使用 CNN kernel 来提取 image 中必须要 latent space。但这个 task 用想的就很难,就让有兴趣的大家去试试看搂!

3.4Image Retrieval
Image Retrieval 要做的事情就是输入一张图片,然后试着去找出最相近的,但若以 pixel-wise 的去比照,那么其实很容易找到完全不相干的东西,因为机器根本没有学到特别的特征,只是一个 pixel 一个 pixel 的去算 loss。若使用 Autoencoder 的方式,先将图片压缩到 latent space,再对 image 的 latent space 计算 similarity,那么出来的结果便会好上许多,因为在 latent space 里的每一个维度,可能就代表了某种特征。若在 latent space 上算距离,便很合理的可以找到相似的图片。尤其这会是一种 unsupervised learning 的方法,不用去 label data ,是个很棒的做法!
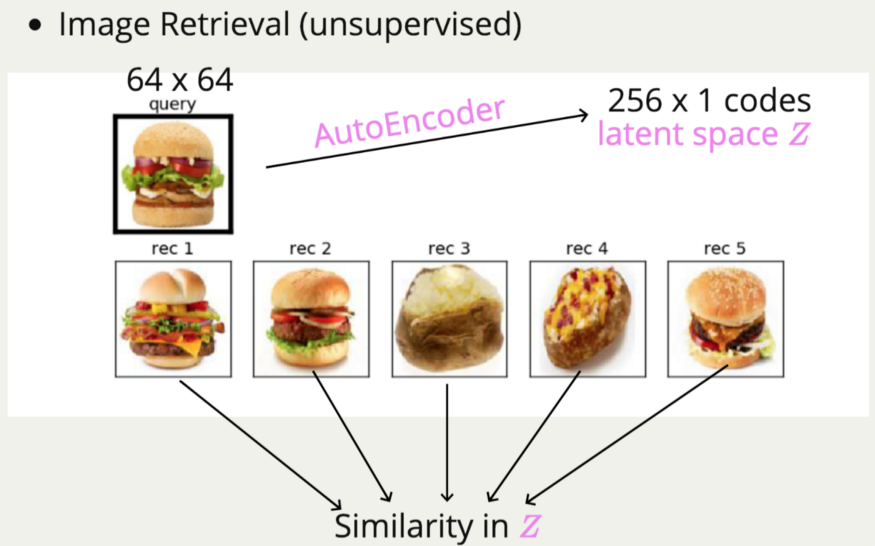
以下是著名的 Deep Learning 大神 Georey E. Hinton 提出的论文,左上角的图示想要搜索的图,而其他的皆为被 autoencoder 认为很像的图,的确 autoencoder 似乎能够看到 input data 的精髓,但也有些抓出来的图片怪怪的 XDD

3.5Anomaly Detection
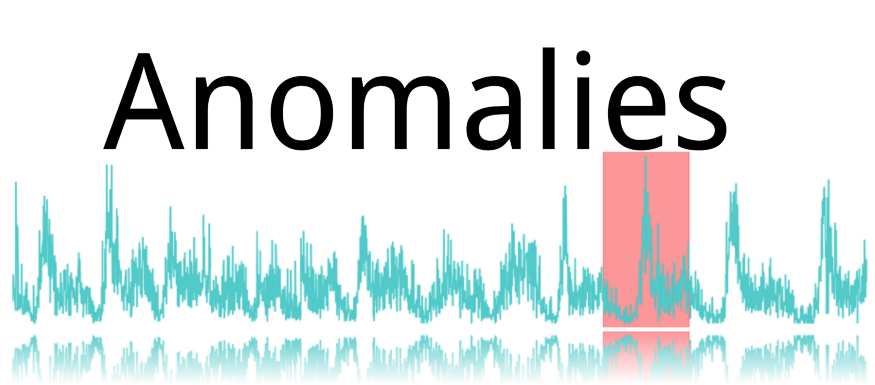
寻找 anomalies 也是超级常见的制造业问题,那这个问题也能拿 Autoencoder 来试试看!先来谈谈实际的 anomalies 的发生状况,anomaly 发生次数通常都很少,比如说机台的讯号异常,温度突然飙升等。这种状况了不起一个月发生一次(再多应该机器要被强迫退休了),如果每 10 秒都搜集一次 data,那么每个月会搜集到 26 万笔 data,但是却只有一段时间的资料是 anomalies,那其实这就会是一笔非常 unbalance 的资料。
那么对于这种状况,最好的方法就是去拿原有的资料,毕竟那是我们拥有最大量的资料!若我们能将好的资料拿去训练出一个好的 Autoencoder,这时若有 anomalies 进来,那么自然地 reconstruct 后的图形就会坏掉。这便是我们使用 autoencoder 去找出 anomalies 的起始想法!
4Implementation
在此我们使用 Mnist 当作 toy example,并使用 Tensorflow.keras 高阶 API 实作一个 Autoencoder! 由于 tf.keras 的新套件释出不久,我们就练习使用文件里的 Model subclassing 作法实战 autoencoder。
4.1Vallina_AE
先 import tensorflow!
'-.,_,.-'”*-.,_☆tf.keras 的使用方法就这么简单,打上 tf.keras 就是了!(不知所云的一段话 lol)
Load data & model preprocess
首先我们先把 Mnist data 从 tf.keras.dataset 拿出来,且做一下 preprocess,
Nomalize: 将值压缩到 0 ~ 1 之间,训练会较易收敛。
Binarization: 将比较明显的地方凸显出来, training 会得到比较好的结果。
# load data first from tf.keras.dataset
( train_images , _ ), ( test_images , _ ) = tf . keras . datasets . mnist . load_data ()
# data preprocess
## use in Convolution autoencoder
train_images = train_images . reshape ( train_images . shape [ 0 ], 28 , 28 , 1 ). astype ( 'float32' )
test_images = test_images . reshape ( test_images . shape [ 0 ], 28 , 28 , 1 ). astype ( 'float32' )
## use in DNN autoencoder
train_images_flatten = train_images . reshape ( train_images . shape [ 0 ], - 1 )
test_images_flatten = test_images . reshape ( test_images . shape [ 0 ], - 1 )
# Normalizing the images to the range of [0., 1.]
train_images /= 255.
test_images /= 255.
# Binarization to make it more easy to training
train_images [ train_images >= .5 ] = 1.
train_images [ train_images < .5 ] = 0.
test_images [ test_images >= .5 ] = 1.
test_images [ test_images < .5 ] = 0.
Create a Model — Vallina_AE
这个是 Tensorflow Document 提供的创建模型方法。Subclassing 提供了较灵活的继承方式,但可能会比较复杂。
我目前看下来的心得是,在 init 的地方,创建 layer,并 define forward pass 在 call 里面。
因此我们用两个 sequential model 去分别创建 Encoder & decoder。两个是一个对称的结构,encoder 先接上 input layer 负责承接 input data 再接上三个 dense layer。Decoder 一样,用 input layer 承接 latent space,再使用三个 dense layer 做 reconstruction。
class vallina_AE ( tf . keras . Model ):
def __init__ ( self , latent_dim ):
super ( vallina_AE , self ). __init__ ()
self . latent_dim = latent_dim
self . encoder = tf . keras . Sequential (
[
tf . keras . layers . InputLayer ( input_shape = ( 784 ,)),
tf . keras . layers . Dense ( 32 , activation = "relu" ,),
tf . keras . layers . Dense ( 16 , activation = "relu" ,),
tf . keras . layers . Dense ( latent_dim )
]
)
self . decoder = tf . keras . Sequential (
[
tf . keras . layers . InputLayer ( input_shape = ( latent_dim ,)),
tf . keras . layers . Dense ( 16 , activation = "relu" ,),
tf . keras . layers . Dense ( 32 , activation = "relu" ,),
tf . keras . layers . Dense ( 784 , activation = "sigmoid" )
]
)
self . AE_model = tf . keras . Model ( inputs = self . encoder . input , outputs = self . decoder ( self . encoder . output ))
def call ( self , input_tensor ):
latent_space = self . encoder . output
reconstruction = self . decoder ( latent_space )
AE_model = tf . keras . Model ( inputs = self . encoder . input , outputs = reconstruction )
return AE_model ( input_tensor ) ##拿这个去串连所有
def summary ( self ):
return self . AE_model . summary ()
vallinaAE = vallina_AE ( 2 )
再来在 call 下面,我们要将 encoder & decoder 串接起来,首先先定义 latent space 为 self.encoder 的 output,然后 reconstruction 为通过 decoder 的结果。接着我们使 tf.keras.Model() 将两个 model 我们 在__init__ 定义的 model 接起来。AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) 指定 input为 encoder 的 input,output 为 decoder 的 ouput 这样就 OK 哩!再来就是 return 接起来的 AE_model 就可以搂!
Model Compile & training
Keras 在训练模型前,必须要先 compile,之后才能丢进去训练。在 compile 中指定要使用的 optimizer 跟想要计算的 loss。训练的话就使用 VallinaAE.fit 把资料喂进去就可以了,但要记得我们是要还原自己,所以X跟Y要丢入一样的资料。
vallinaAE . compile ( optimizer = tf . keras . optimizers . Adam ( lr = 0.001 ), loss = 'binary_crossentropy' )
vallinaAE . fit ( train_images_flatten , train_images_flatten , epochs = 100 , batch_size = 256 , shuffle = True ,
validation_data = ( test_images_flatten , test_images_flatten ), verbose = 1 )
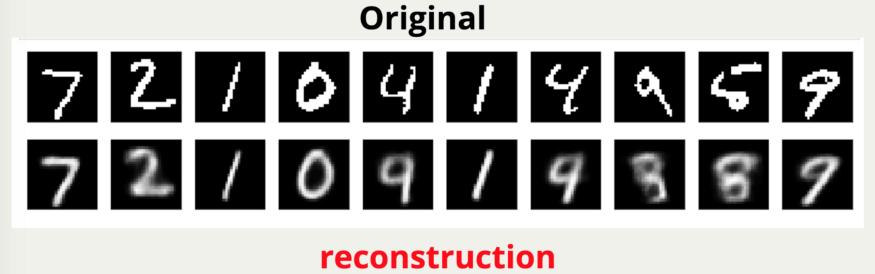
我们来看一下训练了 100 个 epoch 的结果,看起来 reconstruct 的结果并没有想像中的好。
4.2Create a Model
顾名思义,我们可以使用 Convolution layer 作为 hidden layer 去学习更能够 reconstruct 回去的特征。模型建立方法也非常的类似,只是我们的 encoder & decoder 架构稍微改变了一下,改成了 Conv layer 跟 max pooling layer。
class conv_AE ( tf . keras . Model ):
def __init__ ( self ):
super ( conv_AE , self ). __init__ ()
self . encoder = tf . keras . Sequential (
[
tf . keras . layers . InputLayer ( input_shape = ( 28 , 28 , 1 )),
tf . keras . layers . Conv2D ( 16 , ( 3 , 3 ), activation = 'relu' , padding = 'same' ),
tf . keras . layers . MaxPool2D (( 2 , 2 ), padding = "same" ),
tf . keras . layers . Conv2D ( 8 , ( 3 , 3 ), activation = 'relu' , padding = 'same' ),
tf . keras . layers . MaxPool2D (( 2 , 2 ), padding = "same" , name = "latent_space" )
]
)
self . decoder = tf . keras . Sequential (
[
tf . keras . layers . InputLayer ( input_shape = ( 7 , 7 , 8 ),),
tf . keras . layers . UpSampling2D (( 2 , 2 )),
tf . keras . layers . Conv2D ( 16 , ( 3 , 3 ), activation = 'relu' , padding = 'same' ),
tf . keras . layers . UpSampling2D (( 2 , 2 )),
tf . keras . layers . Conv2D ( 1 , ( 3 , 3 ), activation = "sigmoid" , padding = "same" )
]
)
self . conv_AE = tf . keras . Model ( inputs = self . encoder . input , outputs = self . decoder ( self . encoder . output ))
def call ( self , input_tensor ):
latent_space = self . encoder . output
reconstruction = self . decoder ( latent_space )
conv_AE = tf . keras . Model ( inputs = self . encoder . input , outputs = reconstruction )
return conv_AE ( input_tensor ) ##拿这个去串连所有
def summary ( self ):
return self . conv_AE . summary ()
conv_AE = conv_AE ()
conv_AE . compile ( optimizer = 'Adam' , loss = 'binary_crossentropy' )
conv_AE . fit ( train_images , train_images , epochs = 100 , batch_size = 128 , shuffle = True ,
validation_data = ( test_images , test_images ), verbose = 2 )
# print([x.name for x in vallinaAE.trainable_variables])
那改了模型后,可以再来看一下结果,看是不是有进步呢?

看起来 Reconstruction 的结果好非常多,训练下去大概 10 个 epochs 左右就快速收敛到了非常低的 loss。
4.3denoise_AE
另外,autoencoder 也可以实现去杂讯的功能,这边我们试着制作一个有去噪功能的 denoise-autoencoder!
noise = 0.2
train_images_noise = train_images + noise + np . random . normal ( loc = 0.0 , scale = 0.5 , size = train_images . shape )
test_images_noise = test_images + noise + np . random . normal ( loc = 0.0 , scale = 0.5 , size = test_images . shape )
train_images_noise = np . clip ( train_images_noise , 0. , 1. )
test_images_noise = np . clip ( test_images_noise , 0. , 1. )
首先可以先将原始图片加入 noise,加入 noise 的逻辑为在原始的 pixel 先做一个简单 shift 之后再加上 random的数字。这个当作我们的有 noise 的 input data。Image preprocess 的部份我们可以简单的做 clip 小于 0 的就为 0,大于 1 的就为 1。如下图,在经过 clip 的影像处理后,我们可以让图片变得更锐利,明显的地方变得更明显一些。如此一来在丢进 Autoencoder 时可以得到更好的结果。

而模型本身跟 Conv_AE 没有差异,只是在 fit 的时候要改成
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
要将原始的 noise_data 还原成原始 input data

可以看到,在Mnist 上,简单的Autoencoder 就可以很快速的达到去噪的效果。
5Great examples
这边提供一下很好的学习资源给有兴趣的人可以继续参阅
1、Building Autoencoders in Keras[1] autoencoder系列的实作都写得很清楚,可以当作入门去看看。 2、Tensorflow 2.0 官方文件[2] tutorial,东西很完整,只是写的有点难,要花蛮多时间去看的(至少我拉 XD)。 3、李宏毅老师的 deep learning[3] 也是非常推荐,讲得很清晰易懂,非本科系的也能够听得懂的解释,堪称 machine learning 界的最红 youtuber!
6Conclusion
使用这篇文章快速地向大家建立 Autoencoder 的基本概念,一些 Autoencoder 的变形以及运用场景。简单的说 Autoencoder 除了最基本的 latent reprsentation 外,还有这么多的运用,

接下来的几篇会往 generative models 着手,从 autoencoder 的概念延伸,VAE,再到 GAN,还有一路下去的延伸与变形。想要理解地更加深入,请
阅读本文完整代码[4]。
相关阅读
一文掌握降维三剑客 PCA、t-SNE 和自编码器 自编码器很简单?看看这些都掌握了吗 2020 顶会论文解读: 草图秒变高清人脸图
CVPR 2020 最佳论文解读: 从单张图像中无监督学习三维形状的自编码器
⟳参考资料⟲
Building Autoencoders in Keras: https://blog.keras.io/building-autoencoders-in-keras.html
[2]官方文件: https://github.com/tensorflow/docs/tree/master/site/en/r2
[3]李宏毅老师的 deep learning: https://youtu.be/Tk5B4seA-AU
[4]完整代码: https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
[5]原文链接: https://medium.com/ai-academy-taiwan/what-are-autoencoders-175b474d74d1